
一 本文概要
众所周知,数据科学在线社区日渐成熟,越来越多的爱好者投身于网络编程竞赛之中。国内量化私募九坤投资在2022年1月启动了Kaggle竞赛,吸引了两千多只队伍参赛,该竞赛任务为基于给定的A股匿名特征,预测股票未来短期收益,评价指标为预测收益和真实收益的IC值,属于典型的监督学习问题,和实际量化选股场景较贴近。在此背景下,本文梳理了九坤Kaggle量化大赛高分队伍解决方案,总结出四个主要改进方向:引入均值因子,引入CCC损失,时序交叉验证,模型集成。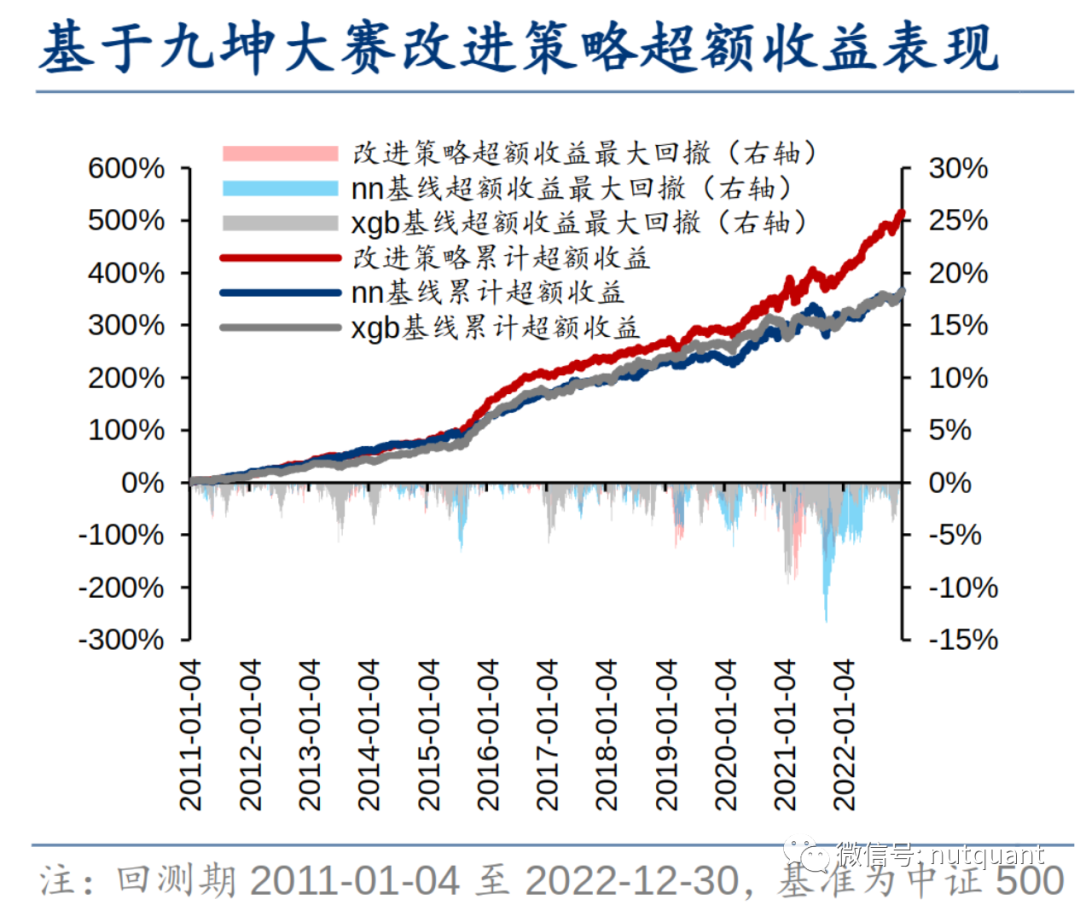
二 任务描述
九坤Kaggle量化大赛的任务是基于给定的A股匿名特征,利用机器学习或深度学习算法预测股票未来短期收益,并且评价指标为预测收益和真实收益的IC值均值。该任务属于典型的监督学习问题,训练数据提供了超过18GB的样本数据,每条数据包含时间id、股票id、300个匿名特征和预测目标等信息。
三 高分方案
从排名靠前的队伍公开的解决方案中,可以发现具有共性的四个方向,包括特征工程、损失函数、交叉验证和模型集成。特征工程方面,高分队伍普遍使用了官方提供的300个特征和按时间id求平均的100个特征,以及对特征的均值、标准差和分位数等操作进行特征增强。损失函数方面,一些队伍使用了RMSE和MSE等传统的损失函数,而其他队伍则采用了IC值作为损失函数进行优化。在交叉验证方面,PurgedGroupTimeSeries和TimeSeriesSplit等方法被广泛应用于处理时间序列数据。在模型集成方面,多个LGBM、NN和自制模型的加权平均或者取平均值等方法都被使用。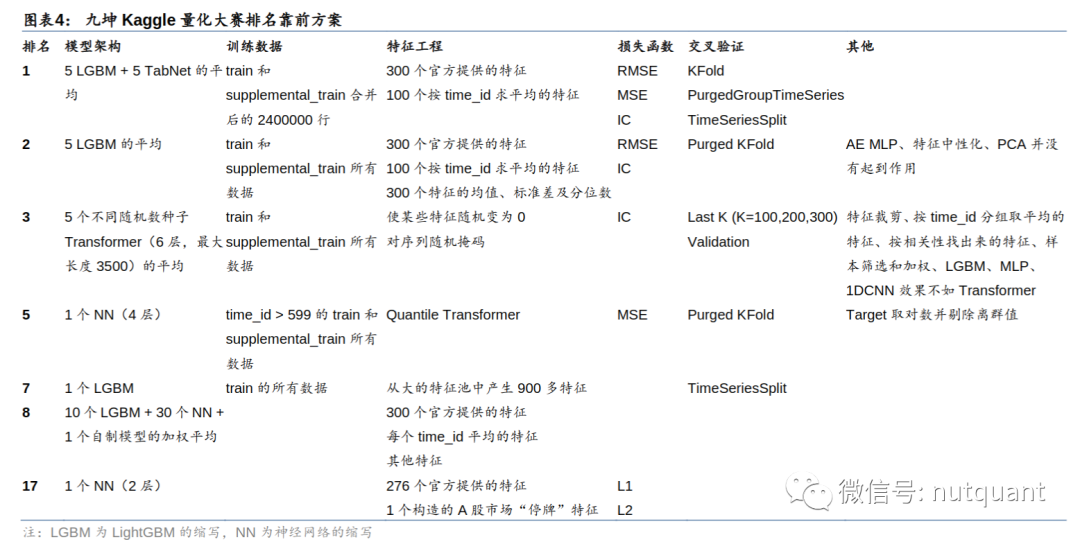
四 本文工作
4.1 特征工程
特征工程包括数据预处理和新特征构造。数据预处理主要包括缺失值填充、异常值剔除和标准化等操作;新特征的构造则依赖投资者的经验和对市场的理解。由于原始数据进行了预处理和匿名处理,无法基于因子含义构造新特征,因此高分队伍们通过构造“按照时间ID取平均的均值因子”来提升模型效果。具体来说,他们在每个交易日对全部股票的某个因子求均值,得到该交易日股票的均值因子,并且该交易日全部股票的均值因子取值相同,在交易日间有差异,反映该因子整体分布的时变特性。虽然在传统机器学习中这种操作不常见,构造一个全部股票取值相同的因子也稍显反常,但是在股票收益率预测任务中有效。
这种构造的均值因子反映了原始因子整体分布的时变特性,可能具备一定的信息量。这也说明了股票收益率预测任务与其他领域的预测问题相比,有其特殊性,未来表现不仅和股票本身特征相关,还与市场整体环境相关,规律存在时变特性,因此引入特征刻画市场环境变化是必要的。
4.2 损失函数
损失函数决定了模型的优化方向,在九坤量化大赛中,最终评价指标为IC值,即预测收益和真实收益的线性相关程度。部分高分队伍直接采用IC值的相反数作为损失函数,而另一些队伍则使用MSE或RMSE衡量预测值和真实值之间的距离。
IC作为损失函数的优点是和比赛最终的评价指标直接挂钩,也是量化机构都会考察的指标,不受量纲影响从而在模型间可比。缺点是非凸不保证收敛,可能导致训练不稳定。MSE作为损失函数的优点是易于计算和求导,具有凸性从而保证收敛,在数据噪声较小的情况下可作为IC的替代。缺点是受数据量纲影响。
CCC是一种融合IC和MSE的方法,它同时考虑相关性和距离。观察CCC的定义,分子中的ρxy代表Pearson相关系数,即IC;分母对两组数据均值的偏离度进行了惩罚。本文使用的CCC是原始CCC的等价形式变换。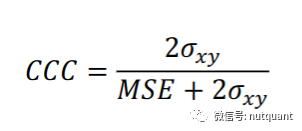 4.3 交叉验证
4.3 交叉验证
交叉验证是一种常用的选择模型超参数的方法,可以将原始数据分成训练集和验证集,在验证集上评价模型的性能。最简单的方式是单次验证,即选择固定比例的训练集和验证集。常用的方式是K折交叉验证,将原始数据分成K份,每次使用K-1份训练模型,使用剩余1份评价模型,对K次评价取平均作为该组超参数的整体评价。
然而K折交叉验证可能存在使用未来信息的问题,因此第1、7名队伍在九坤量化大赛中均提到了这个问题,并提出了时序交叉验证。时序交叉验证将原始数据按时间顺序划分为K份,在第i次验证时,使用前i份数据训练模型,使用第i+1份数据评价模型,避免了未来信息的使用。总的来看,时序交叉验证的优点是无未来信息,且使用数据量较少,时间开销低,但可能存在欠拟合风险。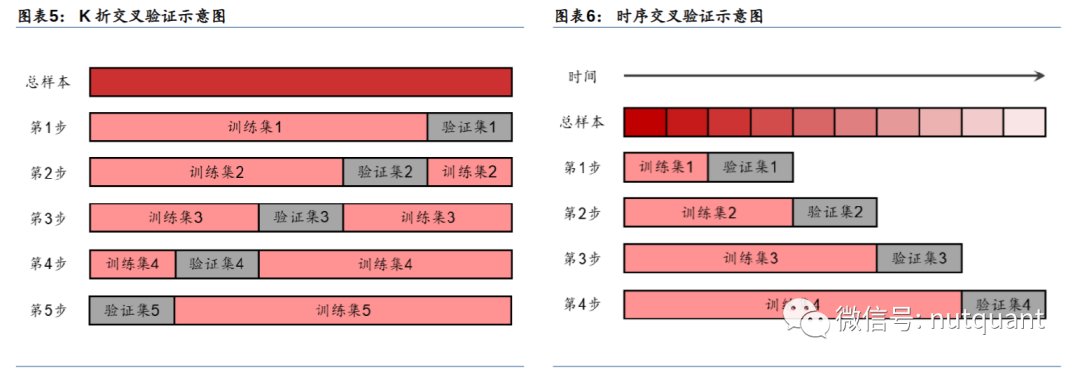
4.4 模型集成
模型集成是一种机器学习中常用的方法,可以将多个子模型融合在一起,取长补短,提高整体性能。在九坤量化大赛中,许多高分队伍采用了模型集成的策略。其中,第1、8、17名队伍集成了多种不同类型的子模型,如决策树类模型和神经网络模型;第2、3名队伍则集成了多个同类型的子模型。尽管投票法、Stacking等模型集成方法层出不穷,比赛中仍主要采用最简单的等权法。
高分队伍使用决策树类模型和神经网络模型作为子模型,两者有各自优势,集成能起到互补效果。决策树类模型对于数据的要求相对较低,对异常值、缺失值和特征间数量级不敏感,是在实践中较常用的一类模型。神经网络一般要求数据数量级一致、不能有缺失值,但可以通过批量训练将多个截面的信息一并地输入到模型中,自动构造出有效的新特征。
除了模型集成外,高分队伍在模型架构上也有可取之处,如第1名队伍采用TabNet,第3名队伍采用Transformer。少数队伍还采用了独特的训练技巧,如第3名队伍使某些特征随机变为0,第5名队伍对预测目标取对数,对特征做分位数转换。这些个性化处理也可能会对模型的表现产生积极影响。
五 实验分析
本研究在已有周频中证500指数增模型基础上,引入了九坤量化大赛中的技巧,并测试其改进效果。全部测试模型包括全连接神经网络(nn)和XGBoost(xgb),特征为42个常规的基本面和量价因子,标签为未来10个交易日收益率在截面上的排序。采用加权mse(wmse)作为损失函数,以截面上个股收益率排序进行衰减加权。交叉验证方法为单次验证,以2526个交易日为训练集,2522个交易日为验证集,252*0.5个交易日为测试集,相当于约半年滚动训练一次。交叉验证配合早停,仅用于确定模型的迭代次数,其余超参数均为固定值。
核心结论如下:
-
引入的均值因子对神经网络有提升,但削弱了XGBoost。 -
MSE损失表现不突出;IC损失单因子测试表现好,但指增组合回测表现差;CCC损失在单因子测试表现一般,但指增组合回测表现较好;加权均优于等权。 -
交叉验证调参改进不显著,考虑到时间开销大,性价比并不高,算力有限前提下,使用经验超参数即可。 -
模型集成提升较稳定,神经网络类和决策树类模型有互补效果。
测试模型因子评价指标及回测绩效如下表格和图表所示: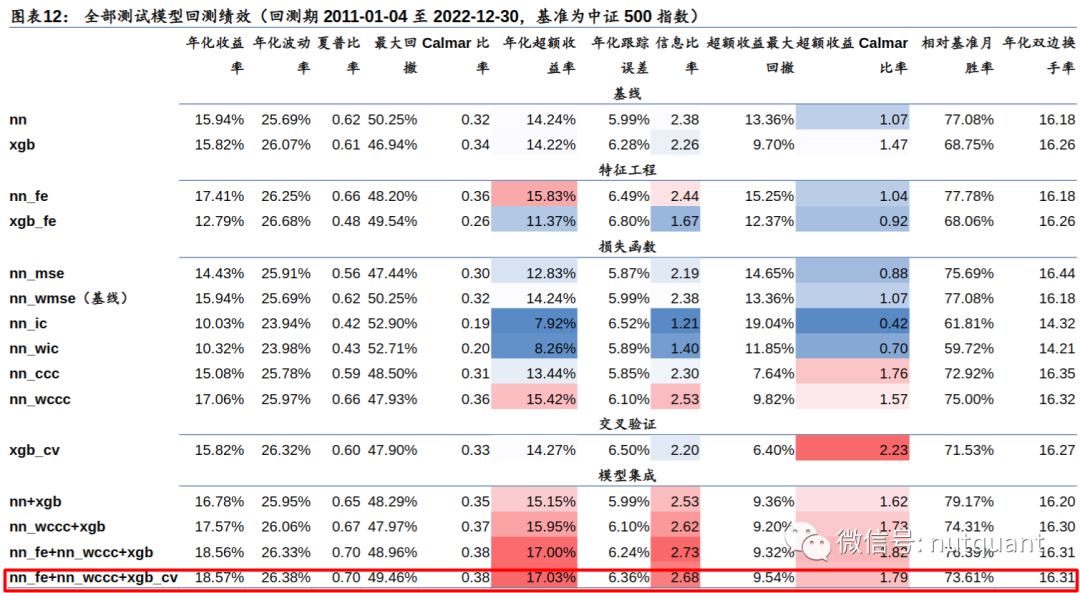
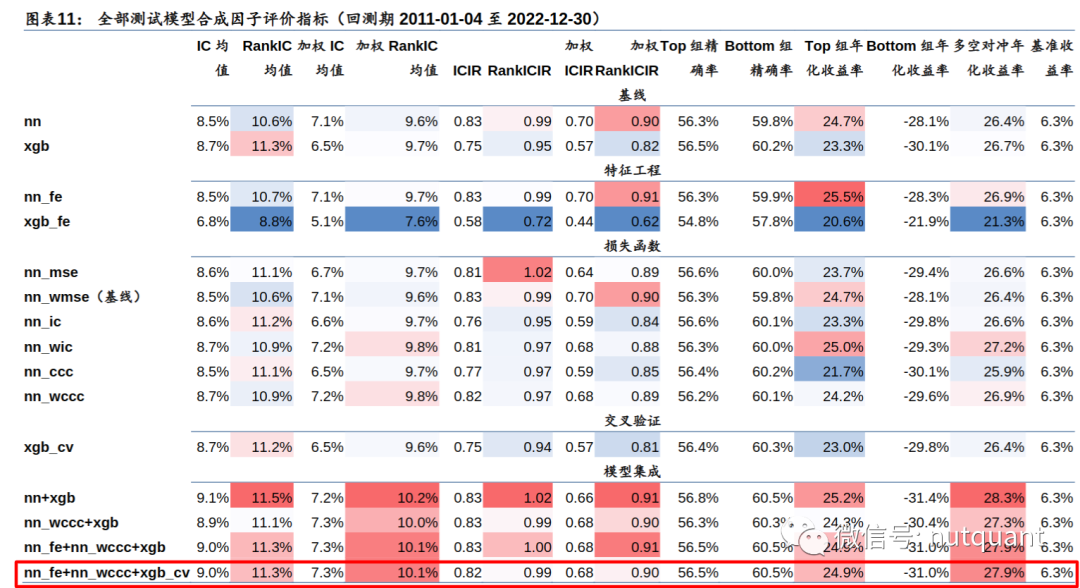
六 总结展望
本文介绍了九坤量化大赛中的股票预测方案,提炼出具有共性的技巧,分别从特征工程、损失函数、交叉验证和模型集成四个方向进行介绍。具体来说,本文发现特征工程引入截面上全部股票因子的均值对神经网络有提升,但对XGBoost模型无效。原因在于均值因子属于弱因子,比重不宜过大;而XGBoost引入弱因子后,特征采样可能会排除原始因子,削弱模型。在损失函数方面,MSE表现不突出,IC损失单因子测试表现好,但指增组合回测表现差,主要是因为因子合成和组合优化的目标不匹配。CCC融合IC和MSE,兼顾共性和个性,是一类理想的损失函数。时序交叉验证效果不明显,使用经验超参数即可。模型集成提升较稳定,神经网络类和决策树类模型有互补效果。总之,本文提供了一些有价值的思路和技巧,可供股票预测领域的相关研究和实践参考。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/110949
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!




