
1. 摘要
本文分享的工作使用DQN强化学习算法构建上证指数日频择时策略,使用2007 至2016 年的数据作为为训练集训练模型,在2017至2022年6月的测试集进行策略回测,年化超额收益率 18.2%,夏普比率1.31,年均调仓42.0 次;进行超参优化后,年化超额收益率提升至 37.0%,夏普比率提升至3.27,年均调仓35.5次。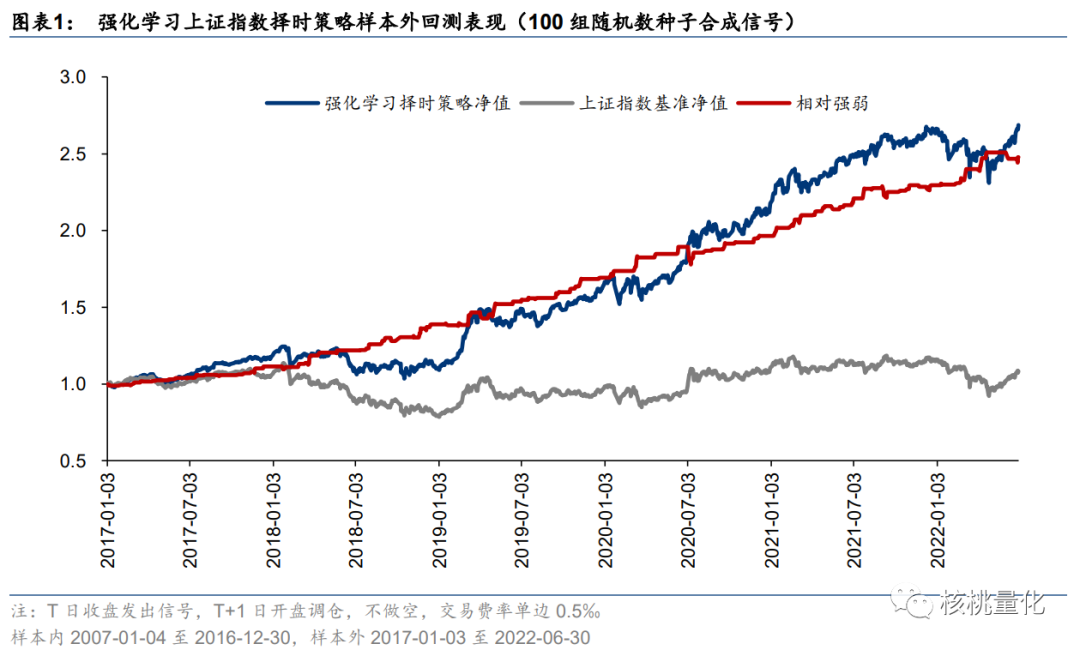
2. 背景知识
2.1 强化学习
与监督学习直接通过优化算法逼近标准答案(标签)不同,强化学习在没有标准答案的情况下,通过在环境中进行试错来学习策略以达成回报最大化。有标准答案的监督学习是人们对现实进行抽象与简化,构建出的乌托邦;而没有标准答案的强化学习,更接近世界的本质,也更接近真正意义上的“人工智能”。
强化学习的核心思想是个体通过与环境的交互,从反馈信号中进行学习。正如游戏玩家通过尝试多种策略,积累对游戏规则的理解;投资者通过交易行为,积累对市场规律的认知。如果某种行为可以使得投资者获得收益,那么这种行为将得到“强化”。强化学习由智能体和环境两部分构成。智能体(agent)是能够采取一系列行动并期望获得 高收益或者达到某一目标的个体,如游戏玩家,投资者。影响智能体行动 学习的其他因素统一称为环境(environment),如游戏的规则,投资标的和市场上其他参与者等。
智能体和环境每时每刻都会进行交互。智能体首先观察环境的状态(state),采取某种动作 (action),该动作对环境造成影响。随后,环境下一刻的状态和该动作产生的奖励(reward) 将反馈给智能体。智能体的目标是尽可能多地从环境中获取奖励。我们在下图以股票交易为示例,整个股票市场就是环境,股票价格,技术指标等信息是状态,买卖股票的交易操作是动作,收益是奖励。智能体首先观察环境,采取行动与环境互动,获得正向或负向奖励。随后,智能体借助反馈修正策略,尽可能最大化奖励。这与投资交易场景非常匹配。投资者首先观察市场,采取买入、卖出、持有等动作,产生盈亏。随后,投资者通过复盘修正投资策略,目标是最大化预期收益。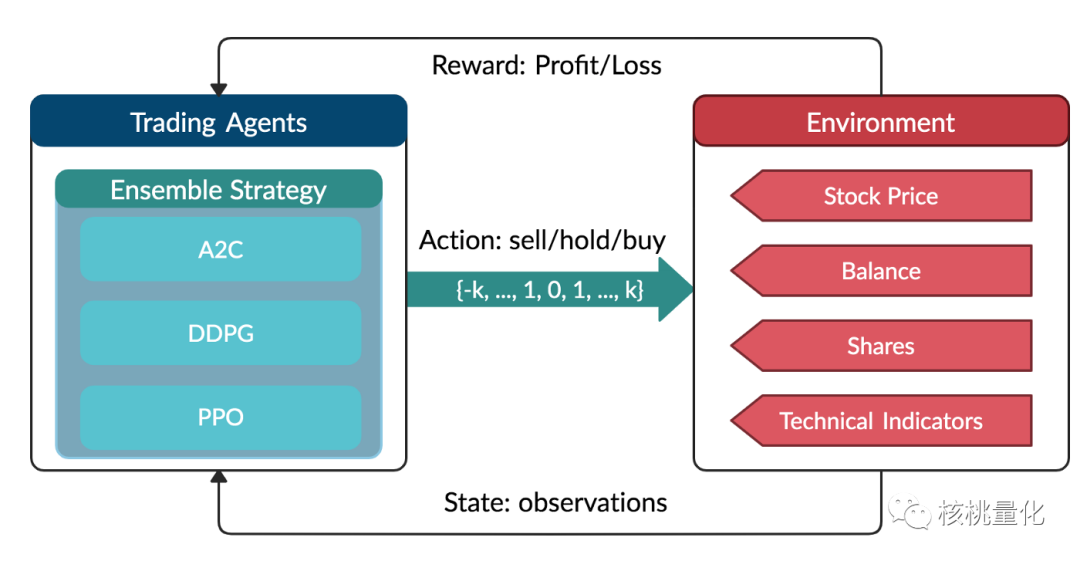
2.2 DQN算法
2015 年,DeepMind 在 Nature 发表论文 Human-level control through deep reinforcement learning,首次将深度强化学习应用于游戏领域并战胜人类,论文采用的强化学习算法正是 深度 Q 网络(Deep Q-learning Network,下文称 DQN)。
DQN 有一个记忆库用于学习之前的经历。Q learning 是一种 off-policy 离线学习法,它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历。所以每次 DQN 更新的时候, 都可以随机抽取一些之前的经历进行学习, 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率。DQN 中使用到两个结构相同但参数不同的神经网络, 预测Q估计的神经网络具备最新的参数, 而预测Q现实的神经网络使用的参数则是很久以前的,这样能够提升训练的稳定性。有关算法更多的详细描述可以参考文献[2]。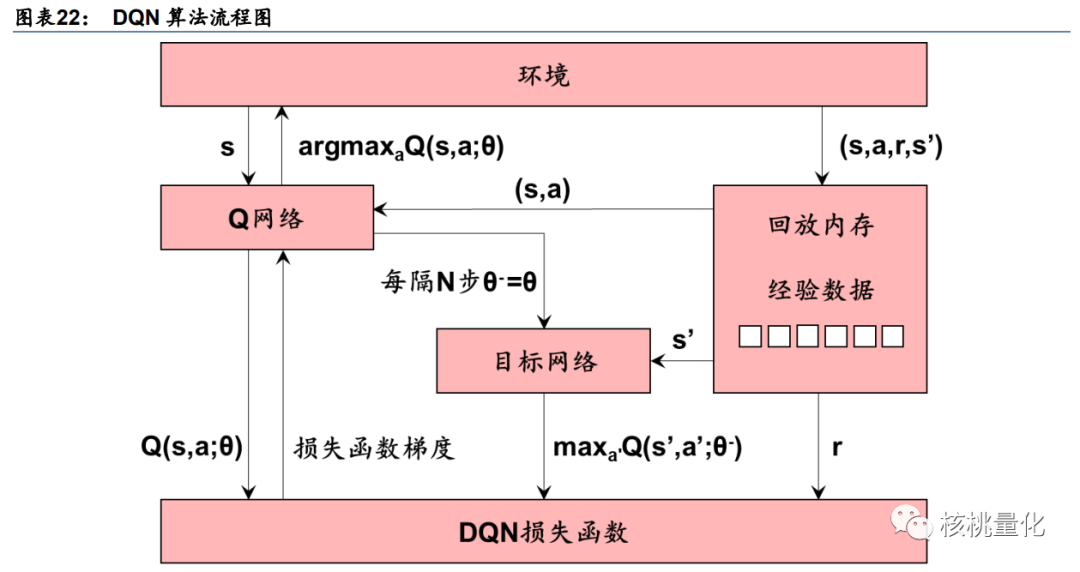
3. 本文方法
本文工作主要分为以下几部分:
-
强化学习的第一步是正确定义问题,对股指日频择时问题进行马尔可夫决策过程建模,定义状态空间、动作空间、状态转移矩阵、奖励函数、折扣因子构成的五元组。 -
第二步是确定强化学习算法设置。择时问题中,将智能体的决策空间简化为全仓做多、持有、 平多三种动作,动作空间属于离散集,因此选择基于价值的方法中的 DQN。进而构建 深度神经网络,包括确定网络结构、训练参数等。 -
强化学习对超参数敏感,对超参数进行参数敏感性分析。
3.1 定义问题
状态空间
表征状态的原始数据为股指在回看区间内日度开盘价、最高价、最低价、收盘价。预处理 方式为计算 t-lookback+1 至 t 日行情数据相对于过去 252 个交易日收盘价的 Z 分数。因此状态空间为 lookback*4 维实空间。回看区间 lookback 取 5 个交易日,同时测试 10 和 15。
**动作空间 **
动作空间定义为{buy, sell, hold}。其中 buy 代表全仓买入,sell 代表全仓卖出,hold 代表持有多仓或者保持空仓,不涉及做空。基于t日收盘价的状态选择动作,以t+1日开盘价执行交易。
状态转移矩阵
我们无法对股票市场的状态转移进行精确描述,状态转移矩阵对于智能体而言是未知的。因此采用免模型方法中的 DQN,免模型方法不需要状态转移矩阵,智能体通过与环境互动进入下一状态。
奖励函数
奖励分四种情况:
-
当前未持仓,且 At 为 buy 时,奖励为预测区间内扣费后多头收益率:
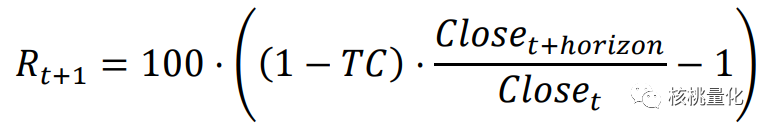
-
当前未持仓,且 At 为 sell 或 hold 时,奖励为预测区间内空头收益率:
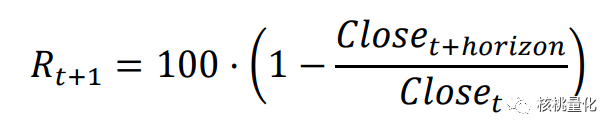
-
当前持多仓,且 At 为 sell 时,奖励为预测区间内扣费后空头收益率:
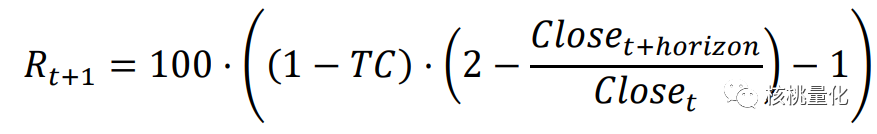
-
当前持多仓,且 At 为 buy 或 hold 时,奖励为预测区间内多头收益率:
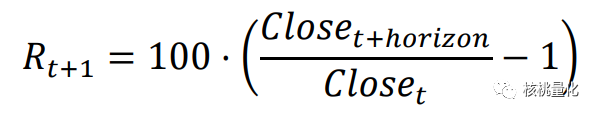
其中 TC 为单边交易费率,本文取万分之五;Closet+horizon为 horizon 日收盘价,预测区间horizon 取 5 个交易日,同时测试 1 和 10。
折扣因子
折扣因子默认取 0.9,同时测试 0.5 和 0.7。
3.2 算法设置
Q 网络是 DQN 的核心组件,本文 Q 网络结构为 3 层全连接网络,如下图所示。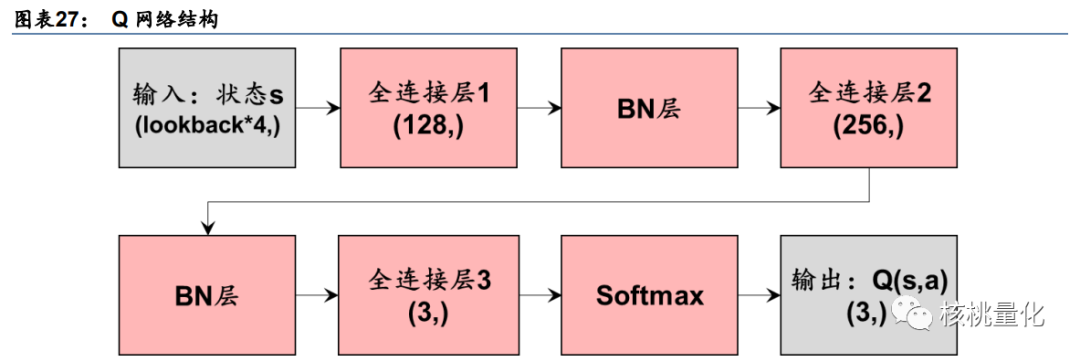
算法的主要步骤如下:
1. 初始化 Q 网络和目标网络;
2. 数据预处理,每个交易日 t,计算 t-lookback+1 至 t 日指数开高低收价格相对过去 252 日收盘价的 Z 分数,作为该日的观测状态;
3. 遍历训练集,构建四元组:按时间顺序,遍历训练集内每个交易日。通过 Q 网络计算该日状态的动作价值 ,通过 ε-贪心算法得到动作a;根据动作和奖励规则, 确定奖励值r(即 t 至 t+horizon 日多头或空头收益);将 t+horizon 日状态视作新的状态 ,由此得到每个交易日的(s,a,r,s’)四元组。
4. 存入回放缓冲区:将该条经验存入回放缓冲区。当回放缓冲区装满时,删除最早的一条数据。
5. 经验回放,优化 Q 网络:每得到一条经验,都对回放内存进行随机采样,得到小批量样本。基于 Q 网络和目标网络计算 Q 网络损失 L(θ),采用优化器更新Q网络参数。
6. 每隔指定epoch数量更新目标网络:每完整遍历一轮训练集,视作一个epoch。当训练轮数达到指定epoch次数时,停止训练。
7. 使用不同随机数种子合成信号,测试集回测:每组随机数种子训练一组 Q 网络。按时间顺序, 遍历测试集内每个交易日。根据该日状态 s 及训练好的 Q 网络计算动作价值,选择动作价值最高的动作 argmaxaQ(s,a;θ)。100 组随机数种子结果以多数票规则合成,得到最终交易信号。当处于空仓状态时,若动作为 sell 或 hold 则继续保持空仓,若动作为 buy 则于次日开盘做多。当处于做多状态时,若动作为 buy 或 hold 则继续保持做多, 若动作为 sell 则于次日开盘平仓。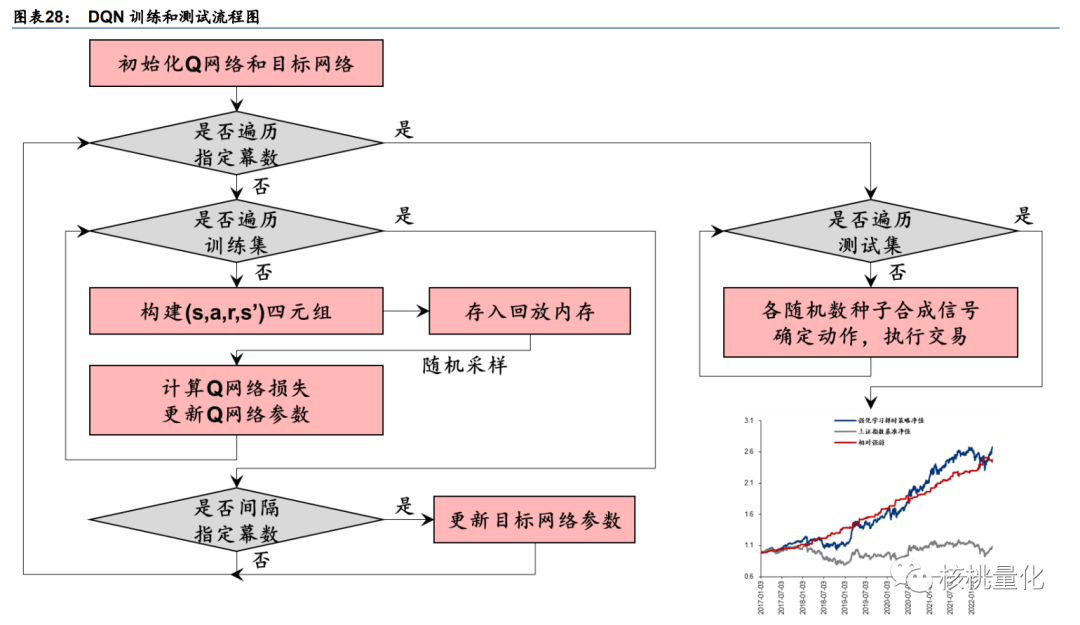
4. 实验分析
4.1 数据
数据为上证指数 2007-01-04至 2022-06-30日度行情数据。其中 2007至 2016年为训练集,用来训练强化学习策略;2017 至 2022 年为测试集,用来评估策略表现。
4.2 超参数

4.3 回测分析
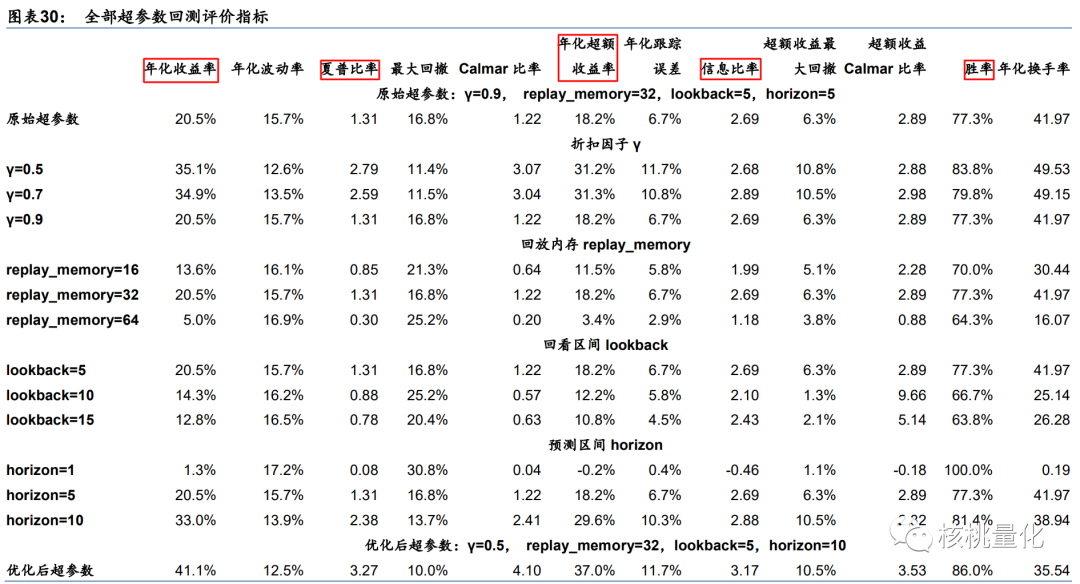
原始超参数为:折扣因子 γ=0.9,回放内存 replay_memory=32,回看区间 lookback=5,预测区间 horizon=5。择时策略样本外年化超额收益率为 18.2%,夏普比率为 1.31,年均调仓 42.0 次。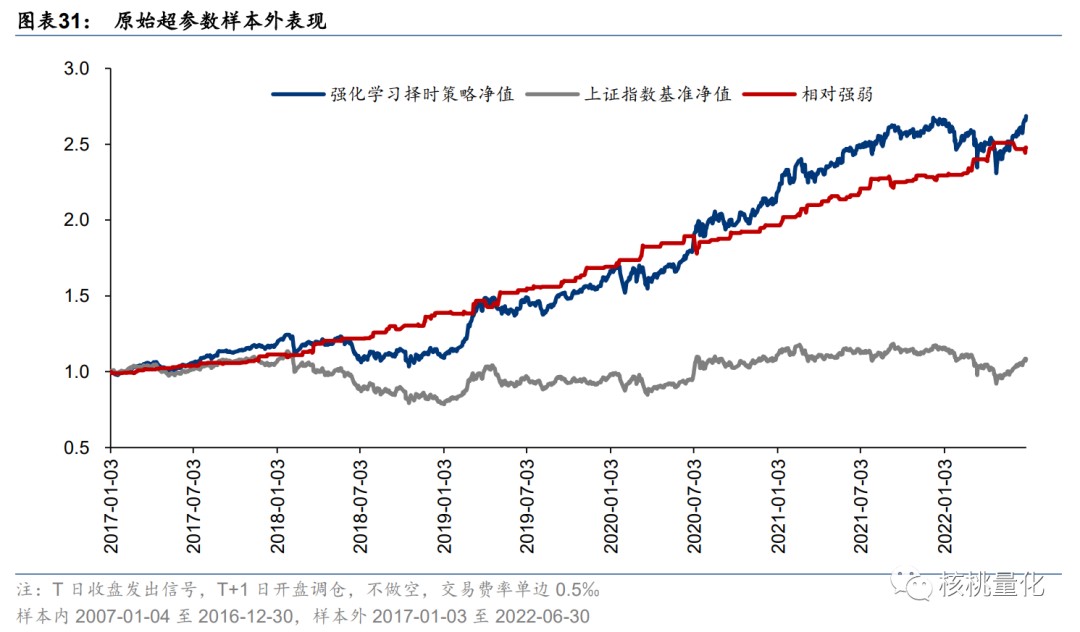
不同折扣因子收益率表现:γ=0.5 和 0.7 接近,γ=0.9 较差。折扣因子 γ 越小,远期奖励权重越低,越关注短期收益,有利于择时策略。 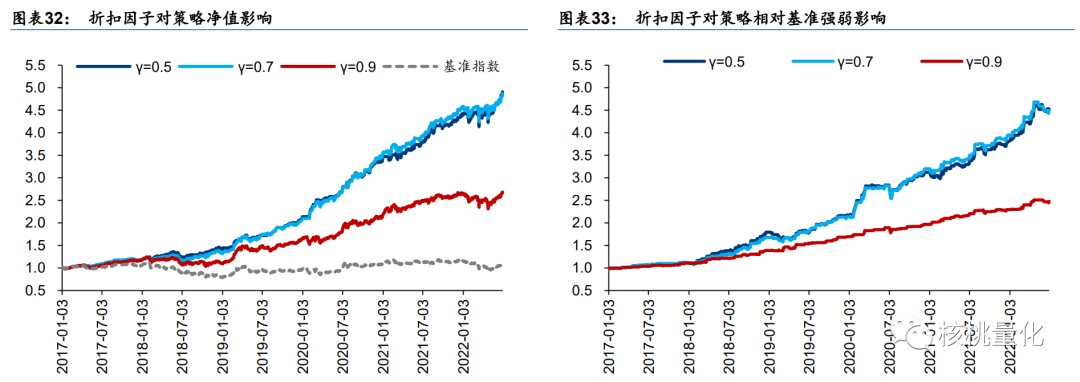
不 同 回 放 内 存 收 益 率 表 现不同,其中replay_memory=32 最好, replay_memory=16 次 之 , replay_memory=64 最差。回放内存和另一个超参数小批量样本数有关联。此处小批量样本数为 16,那么当回放内存为 16 时,每次取回放内存中的全部样本参与训练,失去了随机采样的意义,有损于模型训练。当回放内存较大时,回放内存中包含了相对久远的经验, 好比成年人用儿童的经验学习,也会有损于模型训练。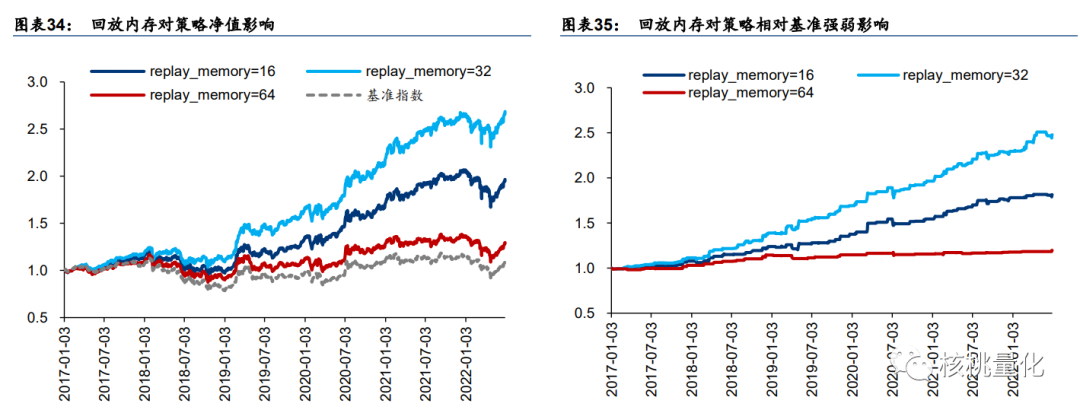
不同回看区间收益率表现:lookback=5 最好,lookback=10和15 接近,lookback=15 略好。过于久远的信息指示意义可能有限,降低数据信噪比,回看区间取短一些较好。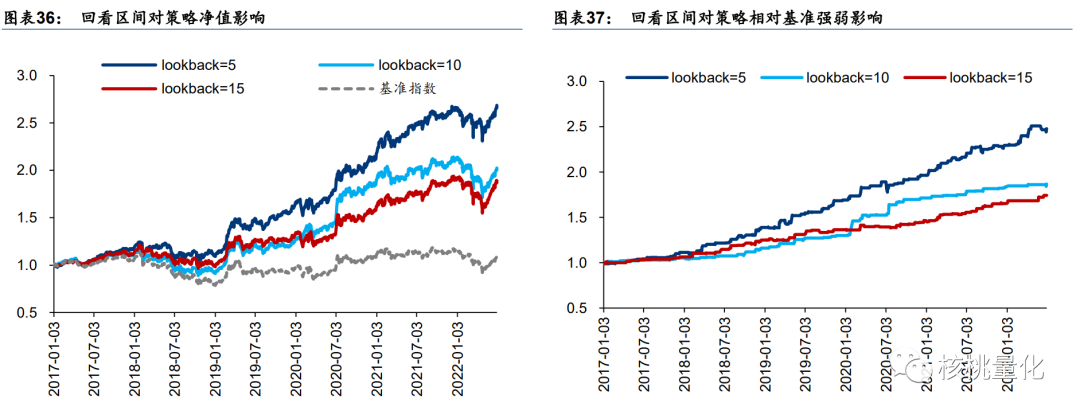
不同预测区间收益率表现:horizon=10 最好,horizon=5 次之,horizon=1 最差。预测区间 越大,计算奖励时目光越长远,有利于择时策略。预测区间 horizon=1 时,模型始终发出 buy 信号,因此策略和基准一致,这可能是因为下一日收益率随机性较大,模型难以学习。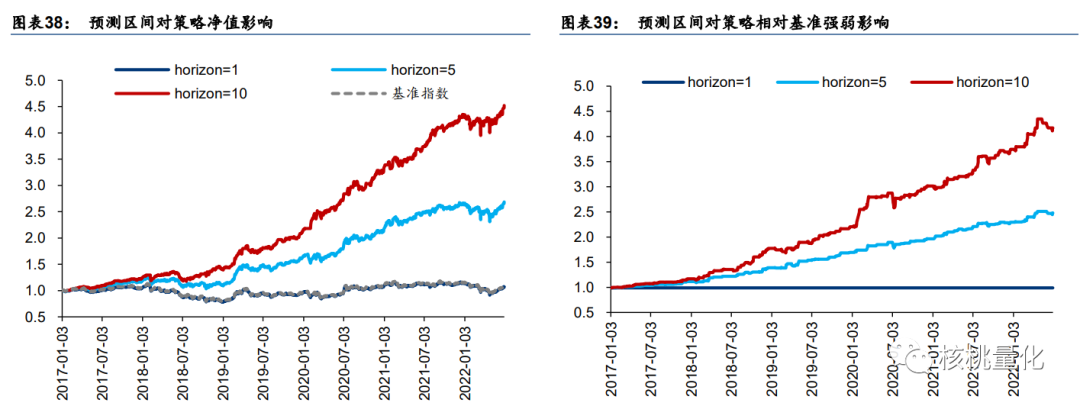
优化后的超参数为:折扣因子 γ=0.5,回放内存 replay_memory=32,回看区间 lookback=5, 预测区间 horizon=10。此时,择时策略样本外年化超额收益率提升至 37.0%,夏普比率提 升至 3.27,年均调仓 35.5 次。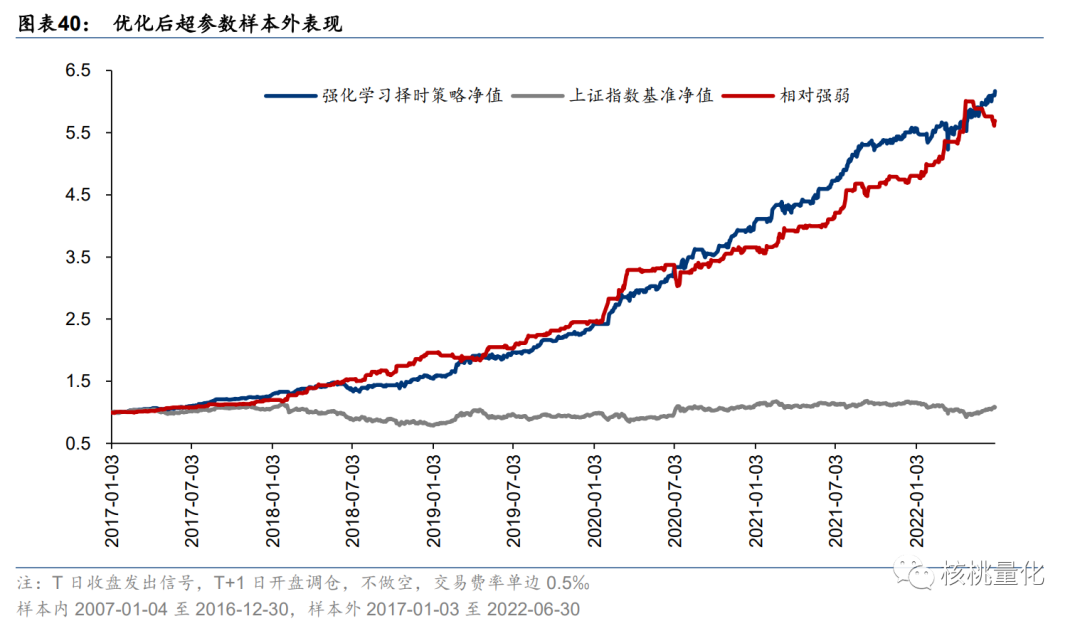
5. 总结展望
本文介绍基于强化学习DQN算法构建股指日频择时策略。有别于传统监督学习对真实标签的拟合,强化学习不存在标准答案,而是针对长期目标的试错学习。使用DQN构建上证指数择时策略,原始超参数样本外 2017 年至 2022 年 6 月年化超额收益率 18.2%,夏普 比率 1.31,年均调仓 42.0 次,优化后策略表现进一步提升。
本研究仅对上证指数进行择时测试,可扩展至更多可交易标的。状态空间仅采用原始行情数据,可扩展至择时指标,或使用神经网络编码。强化学习算法仅测试 DQN,可扩展至其他算法。强化学习存在过拟合风险,需探索过拟合检验方法。
虽然本文的方法表现非常不错,但仍然需要注意将强化学习应用于投资存在以下不可忽视的风险:
1. 数据量不足。训练强化学习模型需要较大数据量。对于股票择时场景,日频行情样本量约在10e3数量级,分钟频 行情样本量约在10e6数量级,逐笔数据样本量约在10e7数量级。强化学习可能更适用于 高频领域。低频领域如果要应用强化学习,就只能牺牲模型复杂度,并承担过拟合风险。
2. 缺少仿真环境。在传统量化研究中,通常只使用历史数据,缺少对市场的仿真模拟,模型的每个决策实际上并不会影响到市场。这种对市场的简化处理,一方面限制了新样本的获取,另一 方面也压缩了强化学习模型的试错空间。然而试图模拟市场又谈何容易,这是强化学习 应用于投资领域,相比于游戏等领域的关键差异和难点所在。
3. 可解释性差。深度强化学习相比深度学习“黑箱”程度更高。强化学习可解释性尚处于初步阶段,大量问题亟待解决。
4. 模型不稳定。强化学习模型超参数较多,并且对超参数、随机数种子较敏感。以前述择时策略为例,每组随机数种子单独产生信号,样本外策略相对基准强弱如下图,各随机 数种子表现差距较大。年化超额收益均值 13.4%,最高 28.0%,最低-0.3%,标准差高 达 8.0%,标准差超过均值的一半。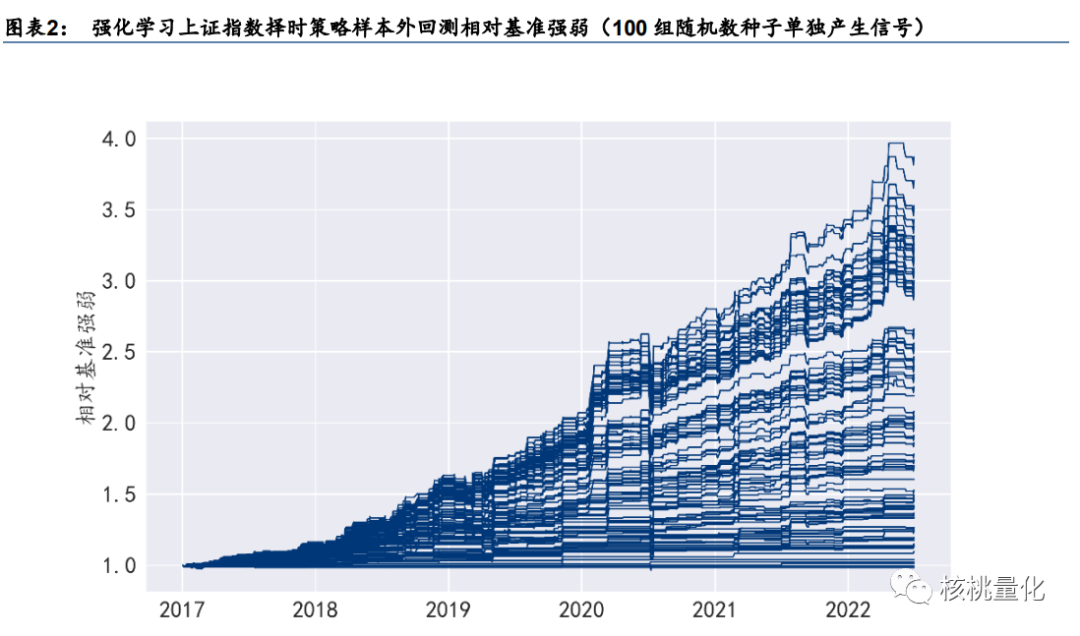
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/110937
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





