
目前可转债数据,因子计算,我们只需要可转债价格、可转债转债价即可。
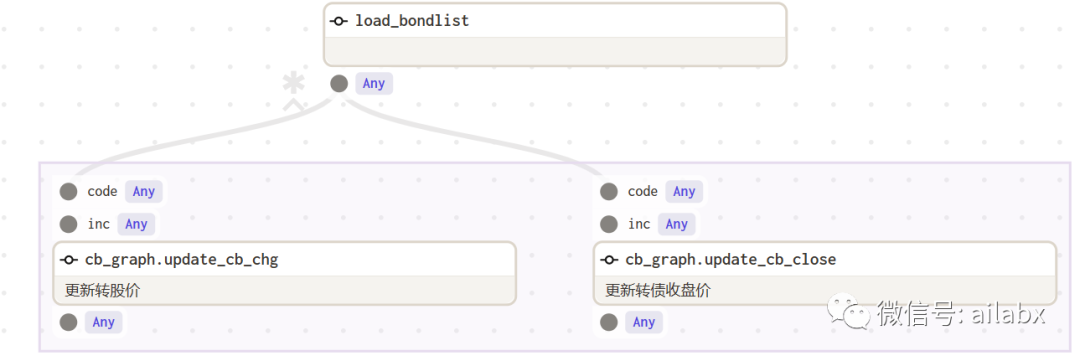

每天下午5:00,自动执行可转债数据入库:
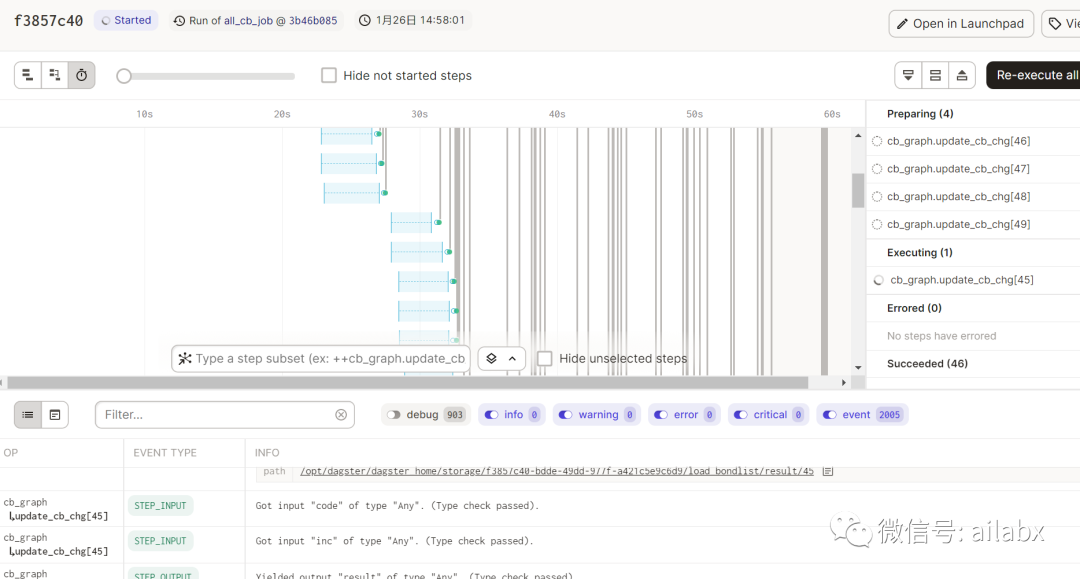
而对应的正股,我们需要更新正股价格,净利润年增长率,PB,PB等指标。

dagster是不错的框架,相比于生长于hadoop时代的airflow,要轻得多,优雅得多。机器学习、数据驱动、定时任务都非常适合这个框架。
有了基础数据,我们还需要对数据做“预计算”。
我们的多因子模型,需要一些衍生指标,比如“pb分位点”,比如“转股溢价率”。在多因子合成时,还需要对衍生指标进行排序,综合排序加权得到最终的得分。
这样的排分若不经过“预计算”,是无法做到“实时查询”的。这就是“OLAP”与OTLP的区别。OTLP更强调业务逻辑、事务,每次动作或数据呈现数据量不大,比如数据的增、删、改多是针对单条数据,甚至还有缓存。查询也是按条件、分页呈现有限条。OLAP的场景则不同,它可能需要从全量、多库、多表、高维数据中得到某个结果。
像文本的全文检索,其实就是对全量文本做了“倒排索引”和“N级缓存”。说白了,用空间换时间。大数据领域的思路基本差不多,预计算,分层计算等。
我这里的做法如下,把720支转债的相关因子,下载到“本地“,做好延伸因子计算,然后存储到hdf5文件里。这里使用了dagster的asset。

@asset(description='转债因子数据合成一个dataframe') def merge_cb_all(): if not os.path.exists(DATA_DIR_HDF5_CB_DATA.resolve()): get_dagster_logger().error('转债因子数据未合成') return datas = [] with pd.HDFStore(DATA_DIR_HDF5_CB_DATA.resolve()) as s: for k in s.keys(): datas.append(s[k]) all_df = pd.concat(datas) all_df.sort_index(inplace=True, ascending=True) print(all_df) with pd.HDFStore(DATA_DIR_HDF5_CB_ALL.resolve()) as s: s['all'] = all_df get_dagster_logger().info('转债因子数据合成成功!')
asset的测试比op和job要简单,直接调用dagster的”物化“函数。
if __name__ == '__main__': from dagster import materialize materialize([merge_cb_all])
全市场转债数据30M左右,还好。

这个all文件可以用于全市场转债策略多因子回测,还可以把当天或者历史上某一天按多因子选债的结果呈现出来。
我们把all里的dataframe读取出来,取某一天的所有数据,然后对因子进行综合排序,给出综合rank得分。
dagster这一次改进,op进化为asset看似复杂,实则精妙。
转债列表,可以依赖正股列表,正股列表在更新数据时可以复用。正股列表更新后,更新转债列表,自动缓存。在排序后可以合成大宽表等等。
其实asset就是一个job,不需要op以及graph或者job,它的运行概念叫”物化“。这在大数据和人工智能领域,这种数据驱动型的应用里特别合适,大量的中间计算可以被复用,省时省事。而且让我们有意识地对中间计算结果进行复用。

发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104165
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!