
01 dataloader加缓存
dataloader做数据特征工程与数据自动标注。因子一多,计算量较大,每次启动都计算一次,影响效率,我们可以借助hdf5存储dataframe的能力,把计算好的因子与标注结果存储起来,下一次直接从缓存里加载。
数据加载器从数据库、csv文件或者hdf5存储格式中读取数据,通常是一个个symbol对应的时间序列数据,以pandas的dataframe的格式加载入内存。而后使用表达式管理器对特征进行计算,并保存到对应的dataframe里。
# encoding:utf8
import pandas as pd
from loguru import logger
from engine.datafeed.expr.expr_mgr import ExprMgr
from engine.datafeed.datafeed_hdf5 import Hdf5DataFeed
from engine.config import DATA_DIR_HDF5_CACHE
class Dataloader:
def __init__(self, symbols, names, fields, load_from_cache=False):
self.expr = ExprMgr()
self.feed = Hdf5DataFeed()
self.symbols = symbols
self.names = names self.fields = fields with pd.HDFStore(DATA_DIR_HDF5_CACHE.resolve()) as store: key = 'features' if load_from_cache and '/' + key in store.keys(): # 注意判断keys需要前面加“/” logger.info('从缓存中加载...') self.data = store[key] else: self.data = self.load_one_df() store[key] = self.data def load_one_df(self): dfs = self.load_dfs() all = pd.concat(dfs) all.sort_index(ascending=True, inplace=True) all.dropna(inplace=True) self.data = all return all def load_dfs(self): dfs = [] for code in self.symbols: # 直接在内存里加上字段,方便复用 df = self.feed.get_df(code) for name, field in zip(self.names, self.fields): exp = self.expr.get_expression(field) # 这里可能返回多个序列 se = exp.load(code) if type(se) is pd.Series: df[name] = se if type(se) is tuple: for i in range(len(se)): df[name + '_' + se[i].name] = se[i] df['code'] = code dfs.append(df) return dfs
dataloader接受4个参数:symbols, names, fields和load_from_cache。
symbols:需要加载的证券列表。
names: 特征名称。
fields: 因子表达式列表。
load_from_cache:是否从缓存中加载。
Load_dfs,按symbol进行遍历。每一个symbol原始dataframe读入内存后,对names和fields需要计算的特征列,计算因子值,并保存到datafram里。
Load_one_df把load_dfs返回的多个dataframes合并成一个dataframe返回,并保存到缓存中备用。
02 随机森林升级为boosting GBDT
from sklearn.ensemble import RandomForestRegressor,AdaBoostRegressor,HistGradientBoostingRegressor e.add_model(SklearnModel(AdaBoostRegressor()), split_date='2020-01-01', feature_names=feature_names)
GBDT的几大算法都有类似的sklearn的接口。
03 Keras深度学习框架
深度学习是当下最前沿的人工智能技术之一。但深度学习比起传统机器学习,比如sklearn框架,学习门槛要高得多。深度学习需要使用者自己搭建网络结构,设定学习率,选择优化目标函数等。功能灵活且强大,学习曲线也高。
最热门的两个深度学习框架当属factbook的pytorch和google的tensorflow。纯粹比较两个框架而言,pytorch的学习曲线要比tensorflow低得多,但仍然要求初学者有矩阵运算,微积分等的数学知识。
Keras的出现,大幅降低的tensorflow的使用门槛。
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的成本把你的想法转换为实验结果,是做好研究的关键。
官方给出的使用场景:
·允许简单而快速的原型设计(由于用户友好,高度模块化,可扩展性)。
·同时支持卷积神经网络和循环神经网络,以及两者的组合。
·在 CPU 和 GPU 上无缝运行。
Keras最大的优点就是简单而快速的原型设计,这一点对于初学者非常重要。我们的目标是量化投资,把深度学习应用于量化,而不是研究深度学习细节本身,所以,能够最小代价满足我们的诉求是关键。后续选择深度强化学习的框架也同样遵从这样的原则。
keras内置数据集:


数据转换:把N个28*28的数据,转为N*784的二维数据:

标签转为one hot的格式:

真正建模的代码很短:
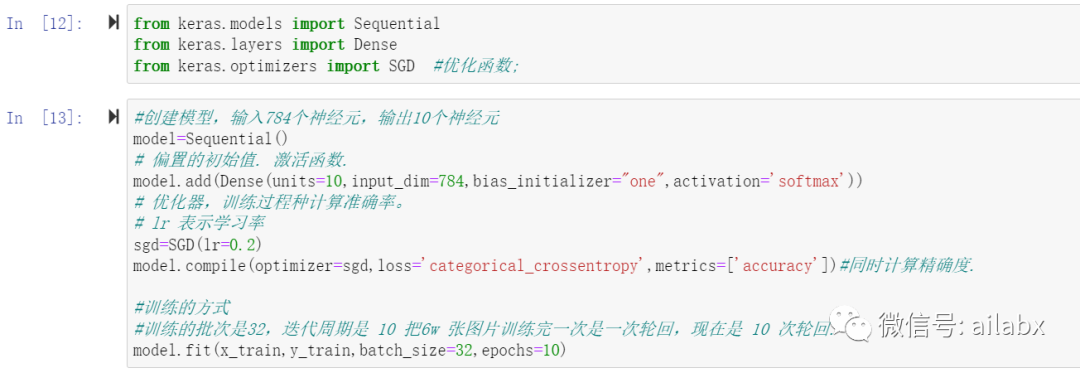

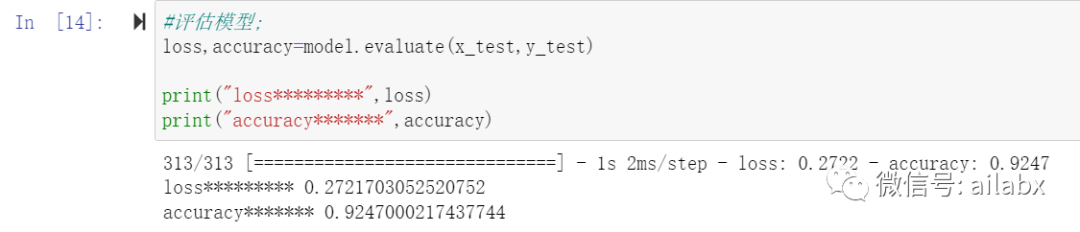
10个epochs,准确率为92%。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104204
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!