
今天开始使用pybroker进行机器学习赋能量化投资。
这里先写下一些思考,传统的投资也好,量化也罢,终究是一个“多因子”的问题。价值投资,你考虑了基本面因子,估值因子,可能还会考虑行业、宏观景气度之类的。只是有些是个人主观判断,没有去量化罢了。——其实是可以且应该量化的。技术分析更不必说的,一个roc_20,或者macd金叉,等等,都可以看做是因子。
只不过价值投资,偏左侧交易,就是只判断位置,不“预测”方向。就是我觉得这个东西值,那就屯起来,等不值了就卖掉。从大逻辑上讲,这个体系是自洽的,没有人可以“预测”市场。估值与位置相对好判断一些,但需要花大量的时间调研,访谈,其实普通人拿到的,听到了,都是过了N手的消息了,普通人做这些没有优势,倒不如找一个靠谱的基金公司或者基金经理。
另外价值投资有一个缺点,就是太难熬。有时间市场错位的时间,会远远超出你的耐心和承受力。
普通人,程序员,做量化,而且是偏右侧可能更有机会。
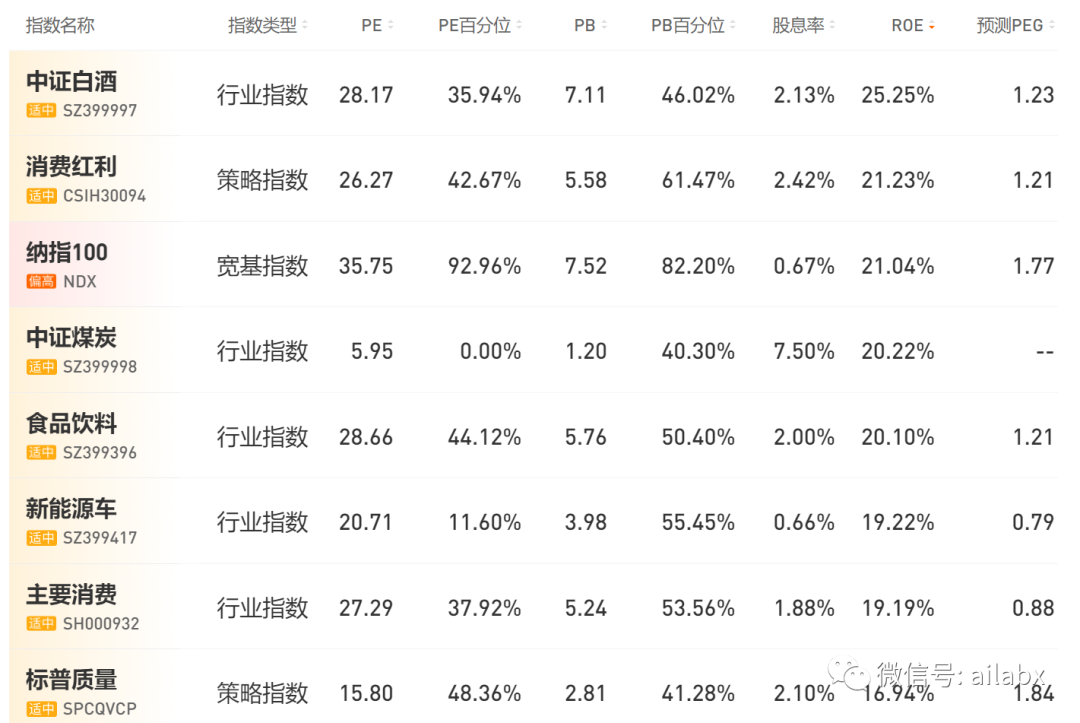
话说,如果从估值来看,这几年来,纳指100都没有机会上车,估值PE分位点一直在80%往上居高不下。但我通过恒定市值定投上车,涨10%就卖出这10%,跌10%就定投补仓,成本持续降低,而且也被动低买高卖,也挺好。这就是相信这个指数的未来。——从这个角度上,我们只需要找到高ROE的指数,恒定市值定投也是不错的一条路。
白酒ROE非常高,现在看百分位还行。煤炭有点出乎意料。

右侧交易的逻辑,就是趋势交易或者均值回归。CTA也是趋势交易,趋势交易就是“追涨杀跌”,这个符合人性。不能叫“预测”市场,而是跟随市场,在趋势确认的情况下,进场;趋势变化了,离场。如此而已。
pybroker整合机器学习
pybroker的扩展完全是传入函数,这是充分使用了python的特点。
传入的参数是symbol,以及这个symbol按train_size划分的数据集——dataframe格式,然后使用sklearn的slr作为示例。
这里有一个问题,与qlib不同,qlib是使用所有symbols的数据训练一个模型,而pybroker是为每个symbol单独训练一个模型。这里的优点是,假设每个证券有自己的规律,相互之间不影响。这个假设有一定的道理,尤其是沪深300与标普500这样的低相关性的指数,各自训练自己模型。
但是在一些轮动型的策略里,比如可转债的双低,我们使用多因子来训练,是会模向比较标的之间的动量,估值情况等。这个在pybroker里似乎不好做了。
在规则量化里,pyBroker使用set_after_exec来动态再平衡,set_before_exec来横向比较权重。但机器学习里没有看到这个部分。当然我们可以考虑自己扩展。
def train_slr(symbol, train_data, test_data): # Train # Previous day close prices. train_prev_close = train_data['close'].shift(1) # Calculate daily returns. train_daily_returns = (train_data['close'] - train_prev_close) / train_prev_close # Predict next day's return. train_data['pred'] = train_daily_returns.shift(-1) train_data = train_data.dropna() # Train the LinearRegession model to predict the next day's return # given the 20-day CMMA. inds = ['cmma_20'] X_train = train_data[inds] y_train = train_data[['pred']] model = LinearRegression() model.fit(X_train, y_train) # Test test_prev_close = test_data['close'].shift(1) test_daily_returns = (test_data['close'] - test_prev_close) / test_prev_close test_data['pred'] = test_daily_returns.shift(-1) test_data = test_data.dropna() X_test = test_data[inds] y_test = test_data[['pred']] # Make predictions from test data. y_pred = model.predict(X_test) # Print goodness of fit. r2 = r2_score(y_test, np.squeeze(y_pred)) print(symbol, f'R^2={r2}') # Return the trained model and columns to use as input data. return model#,['cmma_20']
这里的逻辑是每天预测明天的收益率,如果为正,则买入,反之卖出。
这里我们可以在回测时,按预测的得分排序,然后最高分者持仓,倒也可以。标的之间自己的模型不影响。
pybroker使用WalkforwandAnalysis:

这是比较前沿的做法。
后续几件事情:
1、因子表达式。
2、模型比如随机森林、lightGBM, xgboost,深度模型等等。
3、因子评估,比如alphalens。
4、积木式开发。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104127
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!