
【网格策略】
网格的核心逻辑是找到一个“锚”,然后低位时多买,高位卖出。越跌越买,越涨越卖的逻辑。听到这个逻辑,你应该看出来,高波动的振荡的标的特别适合这个策略。
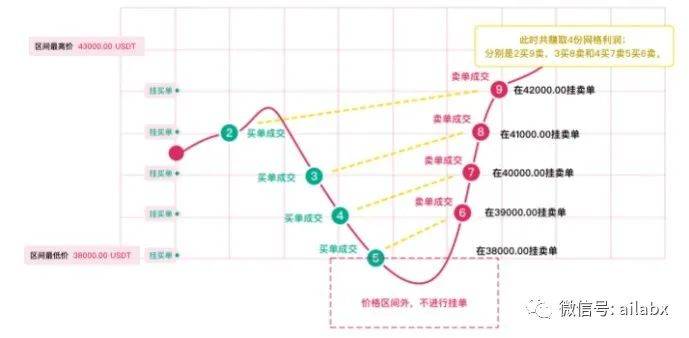

价格的锚点是三年的最高价与最低价的平均。
proj = ProjConfig()
proj.name = '网格策略'
proj.fields = ['max(high,1440', 'low(low,1440)', '(highest_1440+lowest_1440)/2']
proj.name = ['highest_1440', 'lowest_1440', 'mid']
在这个mid的基础上,划分N档。
网格策略的代码如下:
import numpy as np from .algo_base import Algo class AlgoGrid(Algo): def __init__(self): self.perc_levels = [x for x in np.arange( 1 + 0.005 * 5, 1 - 0.005 * 5 - 0.005 / 2, -0.005)] self.last_price_index = None def __call__(self, target): df_bar = target.df_bar mid = df_bar['mid']['B0'] close = df_bar['close']['B0'] price_levels = [mid * x for x in self.perc_levels] signal = False curr_price_index = None for i in range(len(price_levels)): if close > price_levels[i]: curr_price_index = i break if not curr_price_index: return False if self.last_price_index is None: signal = True else: if curr_price_index != self.last_price_index: signal = True if signal: target.order_target_percent( target=curr_price_index / (len(price_levels) - 1)) self.last_price_index = curr_price_index return False
【框架升级】
今天把toml配置文件,使用dataclass重构一下。
dataclass顾名思义就是数据类,可以方便地转为dict,dict可以直接dump/load到toml。
很重要的一个特性是嵌套的数据结构,dataclass的asdict都可以直接转为字典,反向也可以直接生成类。
@dataclass class AlgoConfig: name: str args: list @dataclass class ProjConfig: name: str = '' desc: str = "" start_date = '20100101' end_date = None benchmark: list[str] = field(default_factory=list) symbols: list[str] = field(default_factory=list) data_folder: str = 'futures' fields: list[str] = field(default_factory=list) names: list[str] = field(default_factory=list) algos: list[AlgoConfig] = field(default_factory=list) def to_toml(self): data = asdict(self) toml.dump(data, open("{}.toml".format(self.name), "w", encoding='utf8')) def from_toml(filename): with open(filename, "rb") as f: config = tomli.load(f) proj = ProjConfig(**config) return proj
吾日三省吾身
量化里最重要的事情是什么?投资逻辑。量化只是投资逻辑的数量表达。
最简单的定投,网格背后都有它的逻辑。
无论主动还是背后,投资都是一个概率的逻辑。概率就有有可能发生,有可能不发生。具体结果如何,事后才知道。
那从交易体系而言,就是迎着更大的概率事情而布局,但对可能发生的小概率甚至黑天鹅事件做好底线预案。
即便你有一个超级AI模型,告诉你某支股票会猛涨,这时候,我会怎么办?拿更大的桶去接?当然没错,但这是索罗斯的能力圈,普通人,至少不要加杠杆,你永远问一句,如果方向不及预期的发展呢?比如何时止损,还是死扛——至少你需要想过这个问题。——之前看过一本写得不错的二级市场的小说,结果发现没有续集了——一查发现作者在2015年的牛市见顶之后,加杠杆死杠,然后就没有然后了。
一个成熟的交易体系就是“先胜而后求战”。
大类资产轮动,逻辑比较简单,就是选股,仓位分配。
但到的择时策略,精细化反而更加复杂。
比如说网格,可以是价值与阈值进行判断,来计算signal,根据signal来计算仓位。
2023 Q4 星球OKRs:
目标:以择时策略为主,走通实盘基础闭环。
关键结果1:
1、10月中完成单标的择时策略模板可视化配置。
2、补充止损,仓位管理,网格等基础算子。
3、实现CTA连接模拟账号自动化实盘交易。
使用OKR来灵活管理星球的目标。
老朋友们都知道,这个目标会变化。随着认知的提升,未来也许还会变,变化不是什么坏事,但计划是必须的。我把它都沉淀在一个贴子里,还置顶了,不怕打脸。

9月的关键词是“策略”,可交付实盘的策略,当时聚焦的ETF里。今天要讨论一下这个主题。昨天星球小组例会其实有展开论述。
之前为何我很少关注择时策略,甚至说是刻意避开?
1、大类资产配置的优点是“分散”,天然对冲波动性。它可以有效控制回撤。一个投资组合看起来,曲线比较漂亮,缺点是收益率相对有限。
2、轮动在资产配置与择时之间,它满足了“感觉”上覆盖的市场上多数的标点,对它们截面因子进行比较后“优中选优”。即有资产配置分散降低波动率的优点,又有主动择时提升alpha的能力。因此一度我的策略主要以轮动为主。
轮动的底层逻辑是标的池的相关性,正相关或者负相关。然而这个相关性随时间在变化的,策略如果实盘不及预期,问题不好定位,择时不够精细。
再来说择时。择时约等于投机,“预测”市场,是三者中最难的。
但在量化技术上,却是最简单的。单标的,数据处理简单,加载,计算速度都快。时间序列的稳定性,肯定强过截面。比如白酒和新能源车,你非得说有什么关系,那就是都在A股里,螺纹钢和塑料有什么关系?而白酒自己本身时间序列有自己的基本面,技术的的特征。
择时并非不选股,也并非不分散。而是分层次的。选股在策略之外,分散也在策略之外。比如你选什么标的来做网格,你有波动率的考量,有你对标的熟悉度的考虑。而分散是通过“多策略组合”来实现。多种标的,多种周期,多种操盘思路的不同策略组合起来。
说白了,择时策略是交易体系里的一个部分,细化后可精细化的管理。
最后一点也很关键,就是择时最符合日常操作。无论是构建什么组合,落地时,都是一个个标的去交易,在交易账户里看到了,也是一个个具体标的盈利情况。组合只是我们脑子里的一个逻辑概念。
因此,Q4的重点会落在择时策略上。
昨天使用pyinstaller对软件进行的打包,后续可以直接把安装包发给大家。
在对比了pyinstaller和nuika之后,还是决定使用更容易使用的pyinstaller。
pip install pyinstaller即可,然后在主程序比如main.py上,使用 pyinstall main.py –noconsole,noconsole是为了不出现控制台界面,因为我们使用的是桌面gui。
首先打包比较慢,后面增量就很快了。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103849
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!