
2023 Q4 星球OKRs:
目标:以择时策略为主,走通实盘基础闭环。
关键结果1:
1、10月中完成单标的择时策略模板可视化配置。
2、补充止损,仓位管理,网格等基础算子。
3、实现CTA连接模拟账号自动化实盘交易。
使用OKR来灵活管理星球的目标。
老朋友们都知道,这个目标会变化。随着认知的提升,未来也许还会变,变化不是什么坏事,但计划是必须的。我把它都沉淀在一个贴子里,还置顶了,不怕打脸。


9月的关键词是“策略”,可交付实盘的策略,当时聚焦的ETF里。今天要讨论一下这个主题。昨天星球小组例会其实有展开论述。
之前为何我很少关注择时策略,甚至说是刻意避开?
1、大类资产配置的优点是“分散”,天然对冲波动性。它可以有效控制回撤。一个投资组合看起来,曲线比较漂亮,缺点是收益率相对有限。
2、轮动在资产配置与择时之间,它满足了“感觉”上覆盖的市场上多数的标点,对它们截面因子进行比较后“优中选优”。即有资产配置分散降低波动率的优点,又有主动择时提升alpha的能力。因此一度我的策略主要以轮动为主。
轮动的底层逻辑是标的池的相关性,正相关或者负相关。然而这个相关性随时间在变化的,策略如果实盘不及预期,问题不好定位,择时不够精细。
再来说择时。择时约等于投机,“预测”市场,是三者中最难的。
但在量化技术上,却是最简单的。单标的,数据处理简单,加载,计算速度都快。时间序列的稳定性,肯定强过截面。比如白酒和新能源车,你非得说有什么关系,那就是都在A股里,螺纹钢和塑料有什么关系?而白酒自己本身时间序列有自己的基本面,技术的的特征。
择时并非不选股,也并非不分散。而是分层次的。选股在策略之外,分散也在策略之外。比如你选什么标的来做网格,你有波动率的考量,有你对标的熟悉度的考虑。而分散是通过“多策略组合”来实现。多种标的,多种周期,多种操盘思路的不同策略组合起来。
说白了,择时策略是交易体系里的一个部分,细化后可精细化的管理。
最后一点也很关键,就是择时最符合日常操作。无论是构建什么组合,落地时,都是一个个标的去交易,在交易账户里看到了,也是一个个具体标的盈利情况。组合只是我们脑子里的一个逻辑概念。
因此,Q4的重点会落在择时策略上。
昨天使用pyinstaller对软件进行的打包,后续可以直接把安装包发给大家。
在对比了pyinstaller和nuika之后,还是决定使用更容易使用的pyinstaller。
pip install pyinstaller即可,然后在主程序比如main.py上,使用 pyinstall main.py –noconsole,noconsole是为了不出现控制台界面,因为我们使用的是桌面gui。
首先打包比较慢,后面增量就很快了。
人工智能现在还不能自主参与投资,但若你本身会投资,又懂得借力人工智能,你将无往而不利。
做知识星球的初心:以实战、盈利为导向,开发可持续的策略和平台。
市场覆盖:ETF、可转债、股票、期货和数字货币。
项目100%对星友开源,持续维护和升级。
目前加入星球的的收益:
星球当前的价值点:
1、策略:十几个年化超过20%的量化策略源代码与实现思路文章。
2、代码:一个已经成熟的完全自主研发的可视化AI量化系统,全部源代码。
3、数据:高质量价量数据、估值数据、基本面指标数据打包下载,每日更新。(已经预处理成大宽表,可直接用于数据分析或AI量化)。
4、人脉:星球内部交流群:550+多位星友,有公募、私募基金及券商研究员,职业投资者,算法工程师,金融工程师,数学博士等。
5、课程 :AI量化——从入门到实盘体系教程。
其余精彩待挖掘…
星友画像:
1、主观交易者,希望学习AI量化赋能投资。
2、工程师,对投资理财感兴趣。
3、有量化交易经验,想了解前沿人工智能技术如何赋能量化。
所以,如果大家理念一致,或者有任何问题,意见或建议,可以到星球找我,每天都在。
在这里希望你学会投资,而且学会人工智能技术。
小结
七年之约,只是开始。
践行长期主义。
万物之中,希望至美。
人工智能与金融投资,都是长坡厚雪,且还是为数不多,可以满足个人英雄主义情结的地方。
走,一起赶路吧。
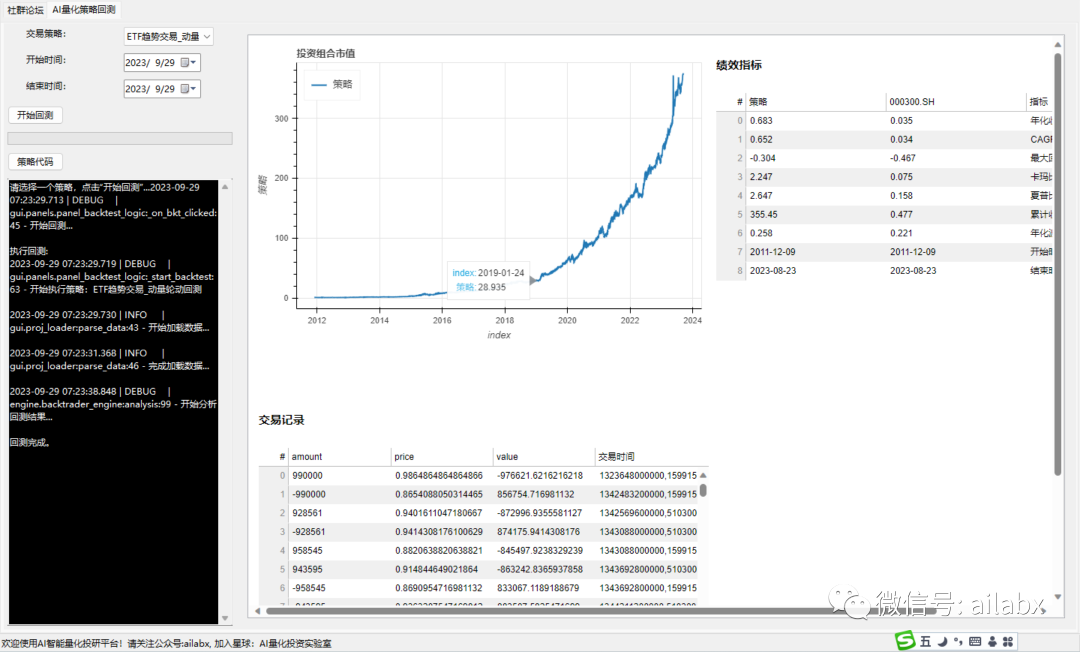
今天实现一下performance计算,对于回测而言,我们最关心的几个指标:最大回撤,波动率,年化收益等。
先看效果:

代码下工程如下位置:(已经更新至星球)

import pandas as pd from datetime import datetime def year_frac(start, end): """ Similar to excel's yearfrac function. Returns a year fraction between two dates (i.e. 1.53 years). Approximation using the average number of seconds in a year. Args: * start (datetime): start date * end (datetime): end date """ if start > end: raise ValueError("start cannot be larger than end") # obviously not perfect but good enough return (end - start).total_seconds() / (31557600) def calc_stats(df_price: pd.DataFrame): if type(df_price) is pd.Series: df_price = pd.DataFrame(df_price) df_price.dropna(inplace=True) df_rates = df_price.pct_change() df_equity = (1 + df_rates).cumprod() df_equity.dropna(inplace=True) df_rates.dropna(inplace=True) # import empyrical # print('年化收益:', round(empyrical.annual_return(df_rates), 3)) count = len(df_price) start = df_price.index[0] end = df_price.index[-1] accu_return = round(df_equity.iloc[-1] - 1, 3) accu_return.name = '累计收益' annu_ret = round((accu_return + 1) ** (252 / count) - 1, 3) annu_ret.name = '年化收益' annu_ret2 = round((accu_return+1) ** (1 / year_frac(start, end)) - 1,3) annu_ret2.name = 'CAGR' # 标准差 std = round(df_rates.std() * (252 ** 0.5), 3) std.name = '年化波动率' # 夏普比 sharpe = round(annu_ret / std, 3) sharpe.name = '夏普比率' # 最大回撤 mdd = round((df_equity / df_equity.expanding(min_periods=1).max()).min() - 1, 3) mdd.name = '最大回撤' ret_2_mdd = round(annu_ret / abs(mdd), 3) ret_2_mdd.name = '卡玛比率' df_ratios = pd.concat([annu_ret, annu_ret2, mdd, ret_2_mdd, sharpe, accu_return, std], axis=1) df_ratios['开始时间'] = start.strftime('%Y-%m-%d') df_ratios['结束时间'] = end.strftime('%Y-%m-%d') return df_ratios.T
我的计算方式,与zipline类似,

bt的计算与我的略有差别:

我看了下它的代码:bt的逻辑是按照自然天数/365,我们是按照回测天数/252。从合理性而言,bt的更符合直觉。

大家可以看下对比情况:

另外可以给loguru添加全局的重定向:
def my_logger_notify(data): g.notify({'msg_type': 'LOGGER', 'message': data}) from loguru import logger logger.add(my_logger_notify)
如此,日志可以实时显示在gui的文本框里。

吾日三省吾身
野蛮扩展和生长的时代,兴趣和事业是可以分开的。
胆识和机遇,喜不喜欢在其次。
但在当下高度成熟的市场,供过于求,竞争高度内卷,唯热爱可抵岁月长。
发现自己。擅长(喜欢的)的事情,用利他的方式做。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103853
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!