
前段时间招商证券出了一份关于市场底部特征的研报,被很多财经自媒体大V引用,该研报总结了市场历史大底的5个信号:
- 超额流动性与新增社融增速的组合出现转正回升。
- 估值水平降到历史低位。
- 外部流动性环境出现边际改善。
- 成交低迷,换手率明显下降。
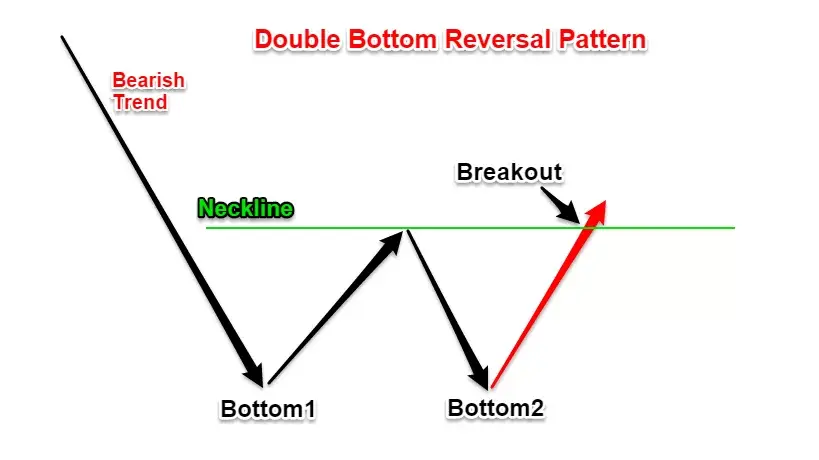
- K线出现类似W底的组合。并且还引用了一句俗语:“单底不是底,双底得天下”。
这份研报也讲了w底形成的原因。当有重要的会议(讲话)出来提振了市场情绪,投资者开始抄底,市场反弹,这时候形成了第1个底。但由于此时可能并未出现流动性和基本面改善的实质性信号,并且因为市场在前期大幅下跌,恐慌情绪仍未消除。部分抄底的投资者在反弹一段时间后选择获利了结头寸,并且之前大跌时未减仓的投资者也利用此次反弹选择降低仓位,从而形成了第二次探底,从K线组合上看就是一个W形态。
经典的技术分析书籍《笑傲牛熊》中也谈到了w底(双重底), 并且指出同时出现成交量明显放大,很好地相对强度和最小的阻力区域时,极有可能预示着客观的上涨,特别的,因为w底经常出现,所以也特别重要。
w底在投资者的交流中也经常出现,尤其在股吧,投资者论坛等等.

有很多种方法可以检测出w底,本文给出一种比较简单的算法,仅仅使用pandas和numpy,不涉及像TensorFlow 或 PyTorch 这样的机器学习库。
1.首先获取价格, 无论从哪个渠道获取,都转为如下格式:
ticker_df = get_stock_price('000895.SZ').reset_index()
ticker_df.head()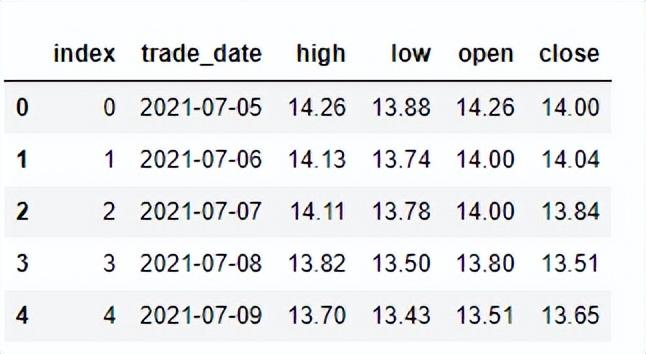
2.进行多项式拟合, 用图形展示则是为了方便进行调参。
x_data = ticker_df.index.tolist()
y_data = ticker_df['low']
x = np.linspace(0, max(ticker_df.index.tolist()), max(ticker_df.index.tolist()) + 1)
pol = np.polyfit(x_data, y_data, 17) # 注意这个参数
y_pol = np.polyval(pol, x)
plt.figure(figsize=(15, 2), dpi= 120, facecolor='w', edgecolor='k')
# 显示股价
plt.plot(x_data, y_data, 'o', markersize=1.5, color='grey', alpha=0.7)
# 显示多项式拟合
plt.plot(x, y_pol, '-', markersize=1.0, color='black', alpha=0.9)
plt.legend(['股价', '多项式拟合'], prop=font)
plt.show()
3.检测局部最小值和局部最大值。局部最小值用红色标记,局部最大值用蓝色标记。
data = y_pol
min_max = np.diff(np.sign(np.diff(data))).nonzero()[0] + 1 # 局部最小 & 最大
l_min = (np.diff(np.sign(np.diff(data))) > 0).nonzero()[0] + 1 # 局部最小
l_max = (np.diff(np.sign(np.diff(data))) < 0).nonzero()[0] + 1 # 局部最大
plt.figure(figsize=(15, 2), dpi= 120, facecolor='w', edgecolor='k')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.plot(x, data, color='grey')
plt.plot(x[l_min], data[l_min], "o", label="min", color='r') # 最小
plt.plot(x[l_max], data[l_max], "o", label="max", color='b') # 最大
plt.title('局部最小 & 最大')
plt.show()
4.拟合函数在 x 轴上的局部极小值位置应该对应于数据中极小值的 x 轴位置。所以要进行一些处理。
delta = 10 # 设置范围
dict_i = dict()
dict_x = dict()
df_len = len(ticker_df.index)
for element in l_min:
l_bound = element - delta
u_bound = element + delta
x_range = range(l_bound, u_bound + 1)
dict_x[element] = x_range
y_loc_list = list()
for x_element in x_range:
if x_element > 0 and x_element < df_len:
y_loc_list.append(ticker_df.low.iloc[x_element])
dict_i[element] = y_loc_list 5.上一步找到了可疑的价格低点。但要寻找的是全局最小值,所以要设置一个阈值,比如设置为最低点的某个百分比(考虑到离群值,也可以采用几个最低值的平均值来改进)。
y_delta = 0.12
threshold = min(ticker_df['low']) * 1.15 # 设置全局低部的阈值,会有很多底部值,但是只有低于这个的才是
y_dict = dict()
mini = list()
suspected_bottoms = list()
for key in dict_i.keys():
mn = sum(dict_i[key])/len(dict_i[key])
price_min = min(dict_i[key])
mini.append(price_min)
l_y = mn * (1.0 - y_delta)
u_y = mn * (1.0 + y_delta)
y_dict[key] = [l_y, u_y, mn, price_min]
for key_i in y_dict.keys():
for key_j in y_dict.keys():
if (key_i != key_j) and (y_dict[key_i][3] < threshold):
suspected_bottoms.append(key_i) 6.可视化展示最终结果。
plt.figure(figsize=(20, 10), dpi= 120, facecolor='w', edgecolor='k')
plt.plot(x_data, y_data, 'o', markersize=1.5, color='magenta', alpha=0.7)
plt.plot(x_data, ticker_df['high'], linestyle='-.', color='g')
plt.plot(x_data, ticker_df['open'], 'o', markersize=1.5, color='grey', alpha=0.7)
plt.plot(x_data, ticker_df['close'], 'o', markersize=1.5, color='red', alpha=0.7)
plt.plot(x, y_pol, '-', markersize=1.0, color='black', alpha=0.9)
for position in suspected_bottoms:
plt.axvline(x=position, linestyle='-.', color='r')
plt.axhline(threshold, linestyle='--', color='b')
#计算颈线值
lowest_idx = [x for x in set(suspected_bottoms)]
lowest_idx.sort()
first_lowest, seconde_lowest = lowest_idx[-2:][0], lowest_idx[-2:][1]
current_price = max(ticker_df.iloc[-1:]['close'])
neckline_price = max((ticker_df.iloc[first_lowest:seconde_lowest])['high'])
plt.axhline(max((ticker_df.iloc[first_lowest:seconde_lowest])['high']), linestyle='-.', color='g')
for key in dict_x.keys():
for value in dict_x[key]:
plt.axvline(x=value, linestyle='-', color = 'lightblue', alpha=0.2)
plt.show()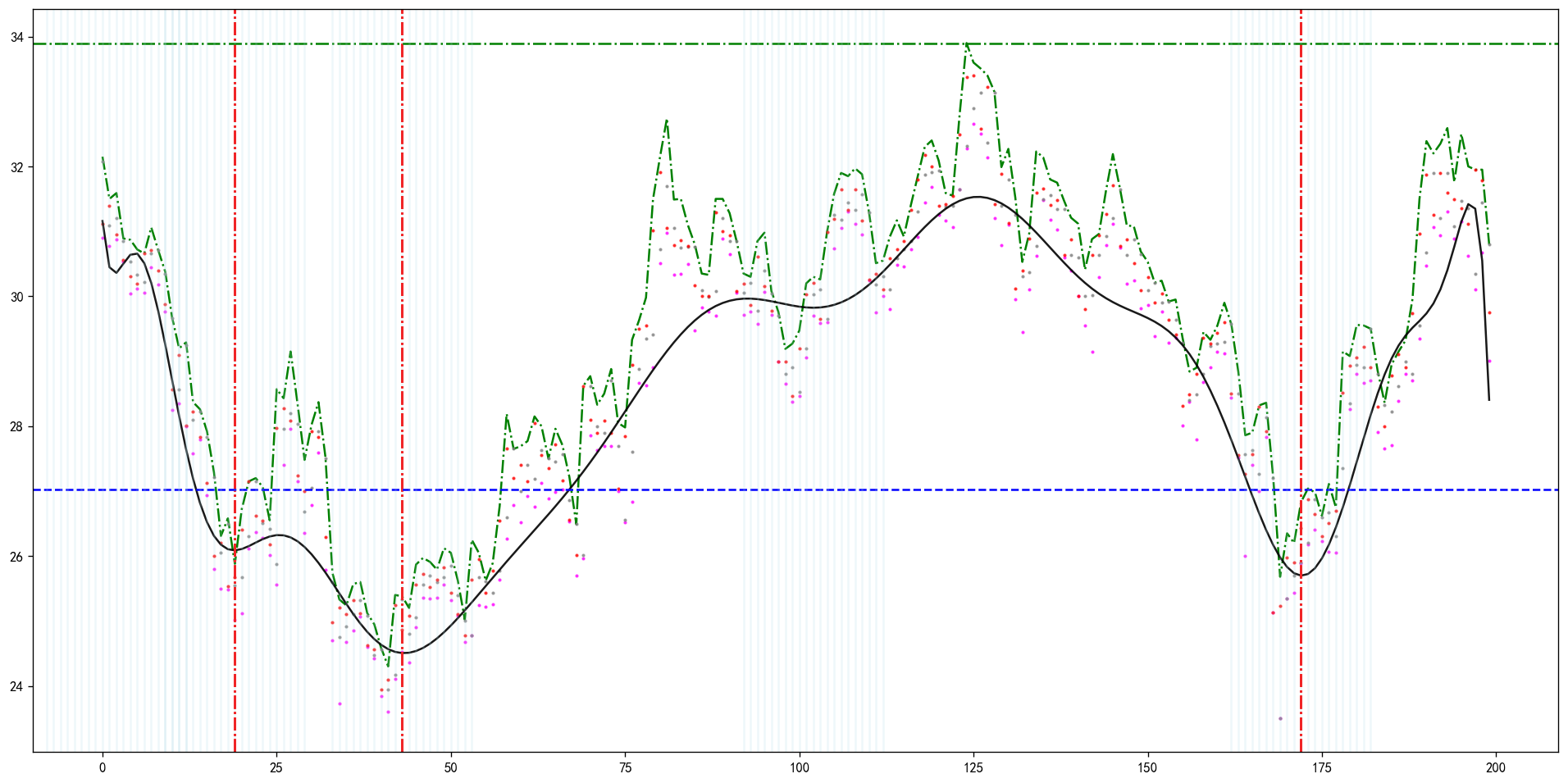
计算的完整代码如下:
def get_double_bottom_info(ticker_df):
x_data = ticker_df.index.tolist()
y_data = ticker_df['low']
x = np.linspace(0, max(ticker_df.index.tolist()), max(ticker_df.index.tolist()) + 1)
# 多项式拟合
pol = np.polyfit(x_data, y_data, 17) # 注意这个参数
y_pol = np.polyval(pol, x)
data = y_pol
min_max = np.diff(np.sign(np.diff(data))).nonzero()[0] + 1 # 局部最小 & 最大
l_min = (np.diff(np.sign(np.diff(data))) > 0).nonzero()[0] + 1 # 局部最小
l_max = (np.diff(np.sign(np.diff(data))) < 0).nonzero()[0] + 1 # 局部最大
delta = 10 # 设置范围
dict_i = dict()
dict_x = dict()
df_len = len(ticker_df.index)
for element in l_min:
l_bound = element - delta
u_bound = element + delta
x_range = range(l_bound, u_bound + 1)
dict_x[element] = x_range
y_loc_list = list()
for x_element in x_range:
if x_element > 0 and x_element < df_len:
y_loc_list.append(ticker_df.low.iloc[x_element])
dict_i[element] = y_loc_list
y_delta = 0.12
threshold = min(ticker_df['low']) * 1.15 # 设置全局低部的阈值,会有很多底部值,但是只有低于这个的才是
y_dict = dict()
mini = list()
suspected_bottoms = list()
for key in dict_i.keys():
mn = sum(dict_i[key])/len(dict_i[key])
price_min = min(dict_i[key])
mini.append(price_min)
l_y = mn * (1.0 - y_delta)
u_y = mn * (1.0 + y_delta)
y_dict[key] = [l_y, u_y, mn, price_min]
for key_i in y_dict.keys():
for key_j in y_dict.keys():
if (key_i != key_j) and (y_dict[key_i][3] < threshold):
suspected_bottoms.append(key_i)
# 移除重复值并降序返回
double_bottom_idx = [x for x in set(suspected_bottoms)]
double_bottom_idx.sort()
return double_bottom_idx
如果存在两个或以上的值,就说明存在w底。然后根据返回的值计算是否突破了颈线。W底只是一个形态,实际中使用还要配合成交量,基本面,动量,RPS等特征。
当然啦,w底有很多种计算方式,特别地对于机器学习来说。对于类如w底的模式检测,Kathryn Dover的Pattern Recognition in Stock Data值得看看。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/78337
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!