


k-means算法是根据给定的n个数据对象的数据集,构建k个划分聚类的方法每个划分聚类即为一个簇。该方法将数据划分为k个簇,每个簇至少有一个数据对象,每个数据对象必须属于而且只能属于一个簇,同时要满足同一簇中的数据对象相似度高,不同簇中的数据对象相似度较小。聚类相似度是利用各族中对象的均值来进行计算的。
新的簇中心计算方法是计算该族中所有对象的平均值,也就是分别对所有对象的各个维度的值求平均值,从而得到簇的中心点。
k-means 算法使用距离来描述两个数据对象之间的相似度。距离函数有明式距离、欧氏距离、马式距离和兰氏距离,最常用的是欧氏距离。
k-means 算法是当准则函数达到最优或者达到最大的迭代次数时即可终止。
k-means 算法的处理流程如下。首先,随机地选择k个数据对象,每个数据对象代表一个簇中心,即选择k个初始中心;对剩余的每个对象,根据其与各簇中心的相似度(距离),将它赋给与其最相似的族中心对应的簇;然后重新计算每个簇中所有对象的平均值,作为新的簇中心。不断重复这个过程,直到准则函数收敛,也就是簇中心不发生明显的变化。通常采用均方差作为准则函数,即最小化每个点到最近簇中心的距离的平方和,即
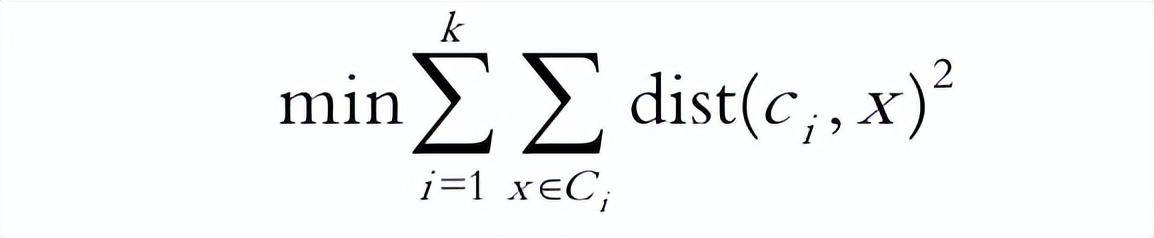
其中,k是簇的个数,ci是第i个簇的中心点,dist(ci,x)为x到ci的距离
2.Spark MLlib 中的 k-means 算法
Spark MLlib 中的 k-means 算法的实现类 KMeans 具有以下参数:
class KMeans private (
private var k: int,
private var maxIterations: Int,
private var runs: Int,
private war initializationMode: String,
private var initializationSteps: Int,
private var epsilon: Double.
private var seed: Long) extends Serializable with Logging

K-Means算法的过程:
1、从样本中所有的n个点中,随机选取其中的k个做中心点;
2、将样本中剩余n-k个样本点分别划分到离它们最近的中心点上,这里的划分完成后,就做完了一次聚类;
3、计算每一个类的平均值,并将每一个平均值作为新的中心点;
4、重复执行步骤2和3,直到中心点的位置不再发生变化。
1、原理简单,收敛速度快,这个是业界用它最多的重要原因之一;
2、调参的时候只需要改变k一个参数;
3、算法的原理简单,可解释性好。
K-Means的缺点:
1、对于离群点和噪音点敏感。例如在距离中心很远的地方手动加一个噪音点,那么中心的位置就会被拉跑偏很远。
2、k值的选择很难确定。
3、只能发现球状的簇。在k-means中,我们用单个点对cluster进行建模,这实际上假设了各个cluster的数据是呈高维球型分布的,但是在生活中出现这种情况的概率并不算高。例如,每一个cluster是一个一个的长条状的,k-means的则根本识别不出来这种类别(这种情况可以用GMM)。实际上,k-means是在做凸优化,因此处理不了非凸的分布。
4、如果两个类别距离比较近,k-means的效果也不会太好。
5、初始值对结果影响较大,可能每次聚类结果都不一样。
6、结果可能只是局部最优而不是全局最优。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76680
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!