
高斯混合模型(Gaussian Mixture Model, GMM)是用多个高斯分布函数去近似任意形状的概率分布,所以GMM就是由多个单高斯密度分布(Gaussian)组成的。每个Gaussian叫一个”Component”,这些”Component”线性加和即为 GMM 的概率密度函数。今天就来深度了解高斯混合模型GMM吧!


将待聚类的数据点看成是分布的采样点,通过采样点利用类似极大似然估计的方法估计高斯分布的参数,用EM算法求出参数即得出了数据点对分类的隶属函数。
GMM是通过选择成分最大化后验概率来完成聚类的,各数据点的后验概率表示属于各类的可能性,而不是判定它完全属于某个类,所以称为软聚类。其在各类尺寸不同、聚类间有相关关系的时候可能比k-means聚类更合适。
GMM的概率密度函数:
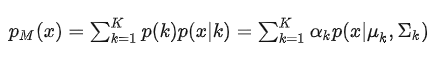
K:模型的个数,即Component的个数(聚类的个数)
αk 为属于第k个高斯的概率(也称为先验分布),其需要满足大于零,且对一个x而言 αk 之和等于1
p(x|k)为第k个高斯的概率密度,其均值向量为 μk , Σk 为协方差矩阵
K是人工给定,其他参数都需要通过EM算法进行估计。
聚类过程:
设置k的个数,即初始化高斯混合模型的成分个数。
算每个数据点属于每个高斯模型的概率,即计算后验概率。
3) 计算 α,μ,Σ 参数使得数据点的概率最大化,使用数据点概率的加权来计算这些新的参数,权重就是数据点属于该簇的概率。
4) 重复迭代2和3直到收敛。
【注意:
1、高斯模型,主要是由方差和均值两个参数决定,对均值和方差的学习,采取不同的学习机制,将直接影响到模型的稳定性、精确性和收敛性。
2、前提假设数据集服从高斯混合分布。
3、K-Means是GMM的特例,即方差在所有维度上都接近于0时簇就会呈现出圆形。
4、聚类评估,并选择最优k个数,模型中封装了Akaike information criterion (AIC) 、Bayesian information criterion (BIC)两种评价方法。最佳的聚类数目是使得AIC或BIC最小化的值。】

GMM的优点:
1、GMM使用均值和标准差,簇可以呈现出椭圆形,优于k-means的圆形;
2、GMM是使用概率,故一个数据点可以属于多个簇。
GMM的缺点:
容易收敛到局部最优解。对于 K-means,通常是重复多次然后取最好的结果,但GMM 每次迭代的计算量比 K-means 要大很多,一般是先用 K-means(重复并取最优值),然后将聚类中心点(cluster_centers_)作为GMM的初始值进行训练。

GMM语法:
Class sklearn.mixture.GaussianMixture(n_components=1, covariance_type=’full’, tol=0.001, max_iter=100, init_params=’kmeans’)
n_components :高斯模型的个数,即聚类个数
covariance_type : 通过EM算法估算参数时使用的协方差类型:‘full’,‘tied’, ‘diag’, ‘spherical’,默认”full”
full:每个模型使用自己的一般协方差矩阵
tied:所有模型共享一个一般协方差矩阵
diag:每个模型使用自己的对角线协方差矩阵
spherical:每个模型使用自己的单一方差
tol:EM 迭代停止阈值,默认为 1e-3
reg_covar:协方差对角非负正则化,保证协方差矩阵均为正,默认为 0
max_iter:最大迭代次数,默认为100
n_init:初始化次数,用于产生最佳初始参数,默认为 1
init_params:初始化参数类型:‘kmeans’, ‘random’,默认用 kmeans 实现,也可选择随机产生
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76679
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!