
正则表达式re,为regular expression的缩写,使用单个字符串来描述、匹配某个句法规则的字符串,一般用于爬虫或者自动化测试前后端不分离项目。我们可以先用它来做个练习,查找字符。首先,导入re库。
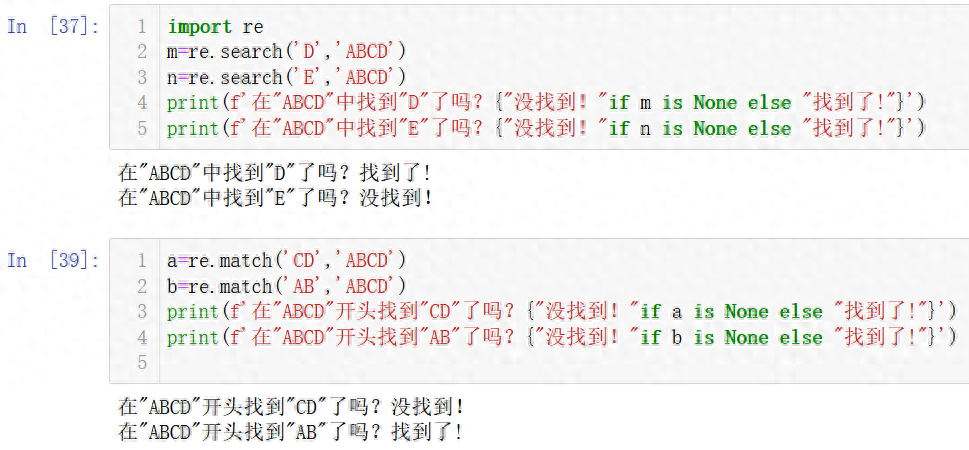
import re
1、search()方法。语法为re.search(要查找出来的字符串,被查找的字符串)
search()方法从头到尾查找,如果找不到会返回None值,找到的话返回非None值。例如:
m=re.search(‘D’,’ABCD’)
n=re.search(‘E’,’ABCD’)
print(f’在”ABCD”中找到”D”了吗?{“没找到!”if m is None else “找到了!”}’)
print(f’在”ABCD”中找到”E”了吗?{“没找到!”if n is None else “找到了!”}’)
结果为:
在”ABCD”中找到”D”了吗?找到了!
在”ABCD”中找到”E”了吗?没找到!
2、match()方法。语法为re.match(要查找出来的字符串,被查找的字符串)
match()仅从开头开始查找,如果开头不匹配,则直接返回None值,开头匹配的话返回非None值。例如:
a=re.match(‘CD’,’ABCD’)
b=re.match(‘AB’,’ABCD’)
print(f’在”ABCD”开头找到”CD”了吗?{“没找到!”if a is None else “找到了!”}’)
print(f’在”ABCD”开头找到”AB”了吗?{“没找到!”if b is None else “找到了!”}’)
结果为:
在”ABCD”开头找到”CD”了吗?没找到!
在”ABCD”开头找到”AB”了吗?找到了!

发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/75079
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!