
drop_duplicates()是pandas库中的一个数据去重的函数。“去重”的意思就是找出重复的行,然后按照一定的方式去处理。
drop_duplicates函数的语法为:
drop_duplicates(subset=None, keep=‘first’, inplace=False)
各参数说明
subset:根据指定的列名进行去重,就是在指定列上数据相同的行就认为是重复,就要去除;默认则为所有列,通俗来说就是两行数据一模一样才去重。
keep:可选值——‘first’、‘last’、False,默认为first。first,默认保留第一次出现的重复值,并删去其他重复的数据;last,默认保留最后一次出现的重复值,并删去其他重复的数据;False是指删去所有重复数据。
inplace:可选值——True、False,默认False。True,对数据集本身进行修改;False,不对数据集本身进行修改。
下面用数据进行举例,先读取一个股票的历史行情:
import pandas as pd
df = pd.read_csv('stock.csv')
df返回:
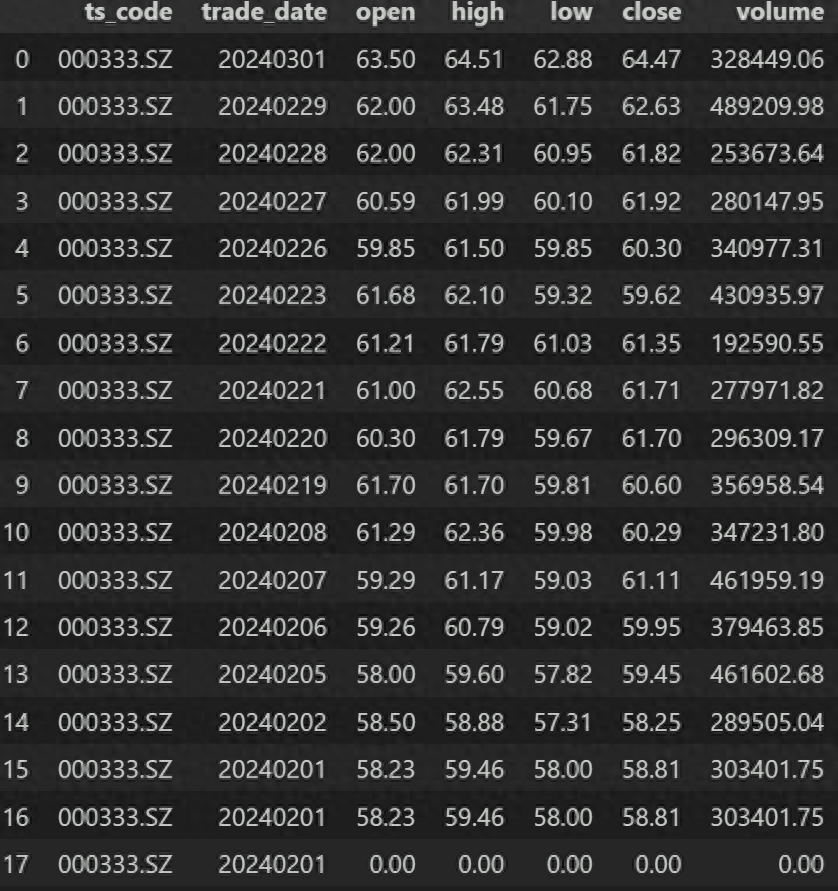

原数据到第15行,为了讲解,我们完全复制第15行,生成了第16行;复制了第15行的代码和日期,其他行填0,生成了第17行。下面我们进行去重:
#不指定列,如遇重复保留第一行,不修改数据
df.drop_duplicates(subset=None, keep='first', inplace=False)返回:
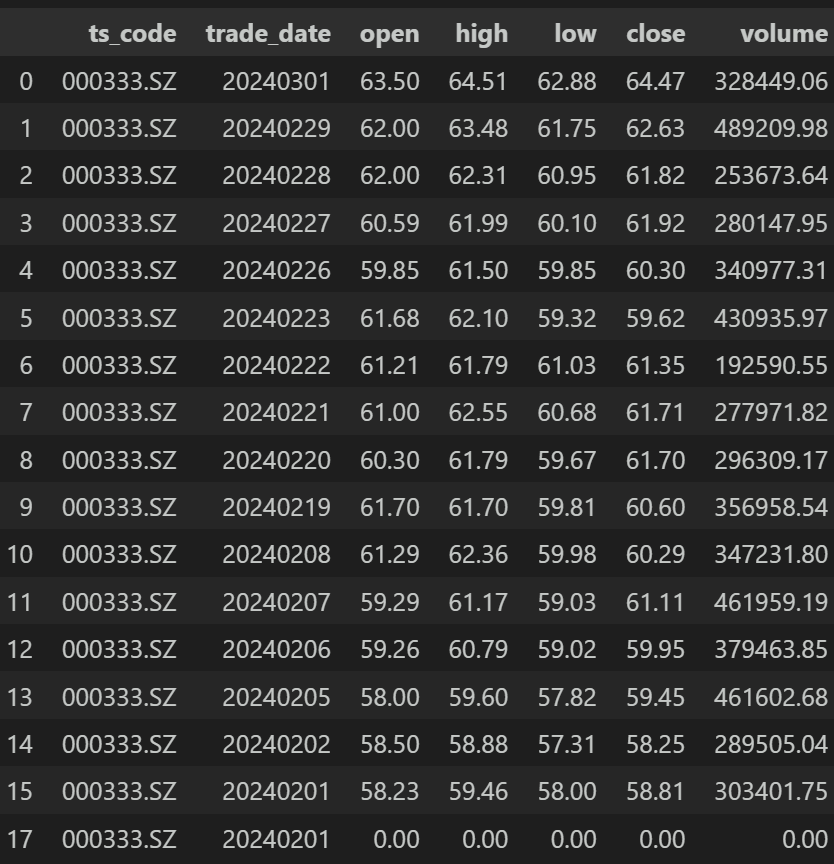
可以看到,因为原表第15和第16行完全一样,所以去除了原表第16行,保留第15行(keep=’first’)。下面我们换一下参数再试:
#指定'ts_code'、'trade_date'两列,如遇重复保留最后一行,不修改数据
df.drop_duplicates(subset=['ts_code','trade_date'], keep='last', inplace=False)返回:
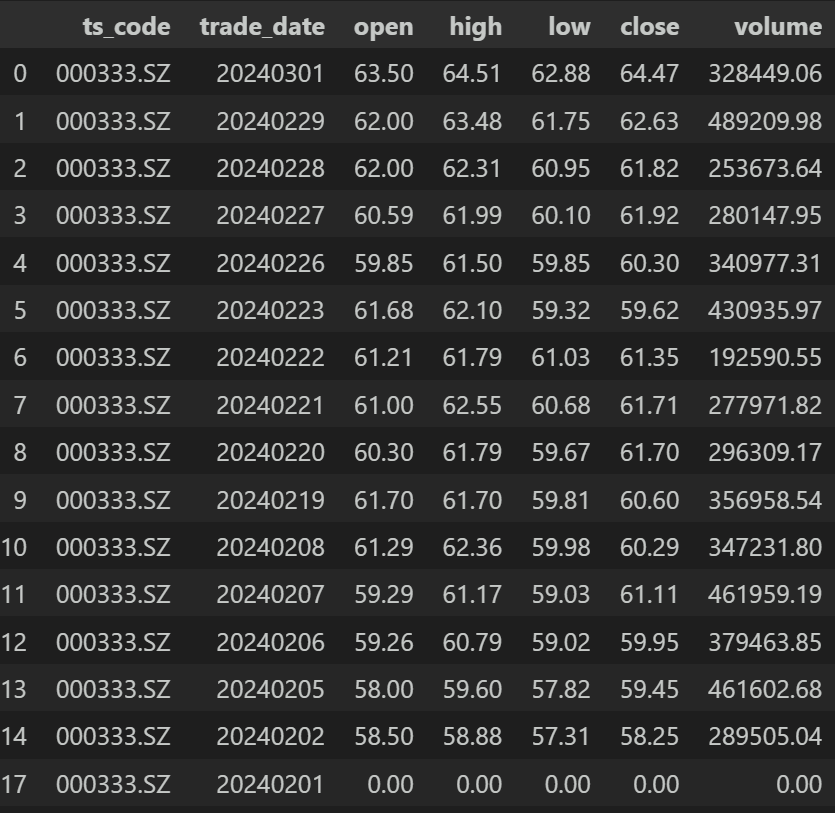
按’ts_code’、’trade_date’两列查找重复,则15、16、17行都符合,处理方式为只保留最后一行,所以15、16行被删除了,17行保留。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/74921
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!