
XGBoost(eXtreme Gradient Boosting)全名为极端梯度提升,是一种Boosting集成算法。它通过最小化损失函数(目标函数)训练单个弱学习器,然后计算得出残差,用残差集再去训练新的弱学习器,目的在于让样本的损失变得更小。今天就认识一下XGBoost模型的智能选股策略吧!


XGBoost的创新之处在于在单纯的损失函数基础上增加了惩罚项,降低模型的复杂度,从而避免过拟合问题。
XGBoost的思想可以用一个通俗的例子解释,假如某人有170厘米身高,我们首先用160厘米去拟合,发现残差有10厘米,这时我们用6厘米去拟合剩下的残差,发现残差还有4厘米,第三轮我们用3厘米拟合剩下的残差,残差就只有1厘米了。如果迭代轮数还没有完,可以继续迭代下去,每一轮迭代,拟合的身高残差都会减小。
XGBoost的重要参数包含框架参数与弱学习器参数:
【框架参数】
n_estimators:最大弱学习器的个数。一般来说n_estimators太小容易欠拟合,数量太多容易过拟合。实际调参时n_estimators与learning_rate一起考虑。
learning_rate:学习率,每个弱学习器的权重缩减系数v,也称作步长,取值在0到1之间。v越小,弱学习器迭代次数越多。
subsample:子采样率,取值在0到1之间。若取值为1,则使用全部样本。如果取值小于1,则只有部分样本会做XGBoost拟合,可以减少方差,防止过拟合;但同时会增大样本拟合的偏差,因此取值不能太低。

【弱学习器参数】
max_features:决策树划分时考虑的最大特征个数,默认全部考虑。若特征过多可以取部分特征以加快生成时间。
colsample_bytree:构建树时的列抽样比例。
colsample_bylevel:决策树每层分裂时的列抽样比例。
XGBoos拥有4个优势:
1、XGBoost 在损失函数里加入了正则项,用于控制模型的复杂度。从方差和偏差权衡的角度来讲,正则项降低了模型的方差,使训练得出的模型更加简单,能防止过拟合。
2、XGBoost 除了决策树外,还支持线性分类器作为弱分类器,此时XGBoost 相当于包含了L1 和L2 正则项的Logistic 回归(分类问题)或者线性回归(回归问题)。

3、XGBoost 借鉴了随机森林的做法,支持特征抽样,在训练弱学习器时,只使用抽样出来的部分特征。这样不仅能降低过拟合,还能减少计算。
4、XGBoost 支持并行。但是XGBoost 的并行不是指能够并行地训练决策树,XGBoost 也是训练完一棵决策树再训练下一棵决策树的。XGBoost 是在处理特征的层面上实现并行的。我们知道,训练决策树最耗时的一步就是对各个特征的值进行排序(为了确定最佳分割点)并计算信息增益,XGBoost 对于各个特征的信息增益计算就可以在多线程中进行。
如何用XGBoost进行智能选股呢?
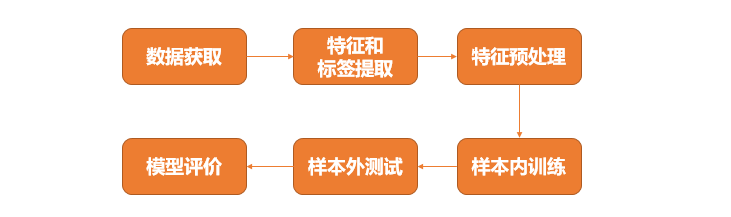
如图所示,XGBoost的策略构建包含下列步骤:
获取数据:A股所有股票。
特征和标签提取:计算18个因子作为样本特征;计算未来5日的个股收益作为样本的标签。
特征预处理:进行缺失值处理。
模型训练与预测:使用XGBoost模型进行训练和预测。
策略回测:利用2010到2017年数据进行训练,预测2017到2019年的股票表现。每日买入预测排名最靠前的5只股票,至少持有五日,同时淘汰排名靠后的股票。具体而言,预测排名越靠前,分配到的资金越多且最大资金占用比例不超过20%;初始5日平均分配资金,之后,尽量使用剩余资金(这里设置最多用等量的1.5倍)。
模型评价:查看模型回测结果,并与随机森林进行对比。

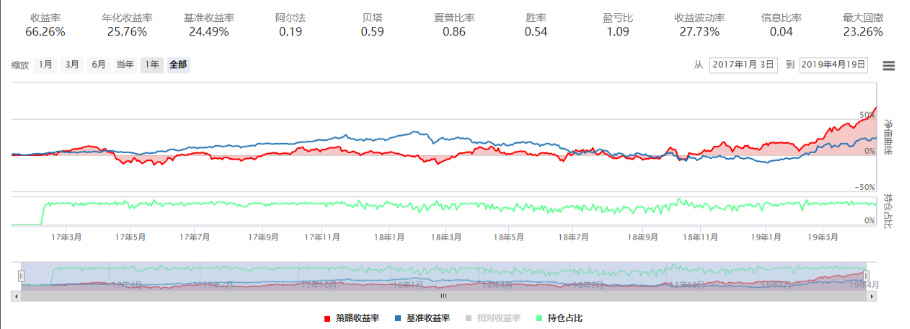
XGBoost与随机森林相比,明显的优势在于回测速度很快,这和其并行处理特征的特点相关。从回测结果来看,XGBoost策略不及随机森林,收益率比随机森林低10%,且最大回撤稍稍高出随机森林2%。当然,经过进一步调参,相信XGBoost的效果会有比较大的提升。
模型评估的结果也表明随机森林的拟合程度更高一些,但是从误差的角度来看,随机森林和XGBoost的差别不大。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/68205
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!