
一. 本文概要
特征选择是机器学习中一个重要的步骤,它可以帮助我们减少数据冗余并减轻模型过拟合的问题。但是,在流数据中,经常会出现概念漂移的现象,这会严重影响模型的性能。因此,我们需要在概念漂移的数据流上进行有效的特征选择。然而,现有的FS算法无法自适应地调整特征选择策略,当有效特征子集发生变化时,它们变得不适用于处理漂移的数据流。
本文提出了一种新的动态特征选择方法,利用深度强化学习来选择概念漂移数据流中的有效特征。本文的方法有两个关键的设计:首先,本文设计了一个跳过模式的强化学习环境,可以缩小高维特征选择任务的动作空间大小,从而降低计算复杂度。其次本文引入了好奇心机制,通过生成内在奖励来解决长期探索问题。这样,我们的特征选择代理可以更好地适应概念漂移,并选择出更有效的特征组合。实验证明,本文的方法在特征选择方面优于其他方法,并且能够动态地适应概念漂移的情况。
二. 本文方法
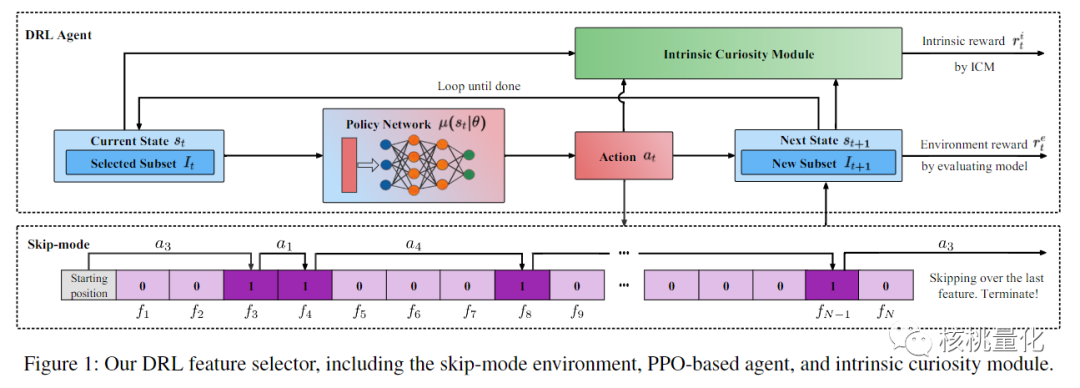
本文特征选择方法使用了强化学习的思想。通过设计了一个智能代理和一个特殊的环境,让它们不断地进行交互,以选择最好的特征子集。整个过程可以用一个流程来描述。首先,代理根据当前已选择的特征集合来判断下一个最佳的特征是什么。它通过观察数据的性能指标来评估选择的好坏,并得到一个奖励信号。另外,本文还引入了一个好奇心机制,鼓励代理去尝试新的特征,以便更好地探索。
强化学习环境是一个特殊设计的跳过模式环境。代理可以选择跳过一些特征,只选择那些被认为是关键的特征。这样做有两个好处:一方面,可以减少计算开销,加快特征选择的速度;另一方面,代理可以更快地找到最重要的特征。在整个过程中,不断地更新代理的策略网络,让它逐步学习并优化特征选择的过程。代理从空的特征集合开始,逐步选择特征,直到满足终止条件。为了衡量特征选择的好坏,本文使用了两种奖励信号。一种是根据选择的数据的性能指标计算的环境奖励(公式1);另一种是根据好奇心机制生成的内在奖励(公式2),这样可以帮助代理更好地探索特征空间。
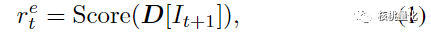
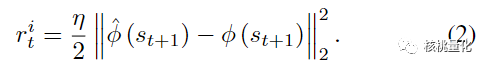
总的来说,本文方法通过智能代理与特殊设计的环境之间的交互,能够从大量的特征中选择出最为重要的特征子集。这种方法使用强化学习的思想,通过奖励信号和好奇心机制来引导代理的学习和探索。同时,跳过模式的环境设计使得特征选择过程更加高效。
三. 实验分析
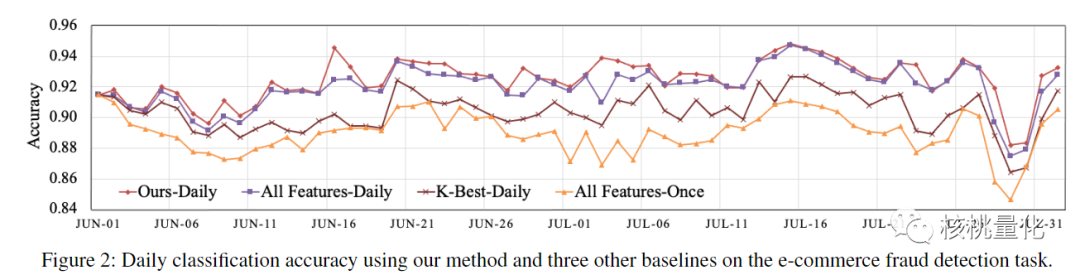
实验部分在一个电子商务欺诈检测的数据集上与其他三种方法进行了比较,这些方法都面临着特征漂移的问题。这个数据集是在一个真实的电子商务平台上实时收集的,其中包含了大约2000万个交易样本以及110个特征。每个样本都被标记为0或1,表示非欺诈和欺诈。
实验结果展示如上图所示。从结果可以看出,本文的方法(红线)每天都能找到有效的特征,并且在性能上超过了传统的特征选择方法,比如K最优法。尤其是当特征的变化非常剧烈时,比如在7月29日左右,本文的方法通过为下游模型提供及时有效的特征,减轻了特征变化对性能下降的影响。
四. 总结展望
本文提出了一种基于强化学习(RL)的特征选择(FS)方法,该方法可以根据特征漂移的变化动态地调整选择策略。实验显示该方法能够根据特征漂移的情况持续地选择最佳的特征子集,并且在性能上超过了传统的特征选择方法。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111112
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





