
近年来,梯度提升(boosting)算法及其变种在许多社区中受到了广泛关注。这主要是因为与其他机器学习算法相比,梯度提升算法在产品和机器学习竞赛中获得了更好的性能表现。基于梯度提升机的两种最受欢迎的算法是XGBoost和LightGBM。一些数据科学从业者花费大量时间思考采用哪种算法,并且最终往往会进行大量的尝试和尝试,本文将从实践的角度和一点理论的角度来探索这两种技术,以更好地理解它们的优缺点。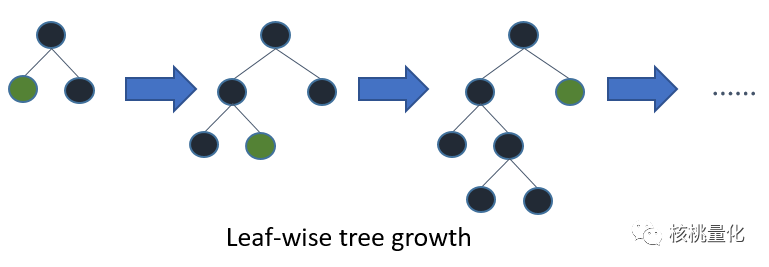
什么是梯度提升?
梯度提升是指机器学习中的一种方法,其中使用弱学习器集合来提高模型在效率、准确性和可解释性方面的性能。这些学习者被定义为比随机机会具有更好的表现。此类模型通常是决策树,它们的输出被组合起来以获得更好的整体结果。
该假设是过滤掉难以准确预测的实例,并开发新的弱学习器来处理它们。训练初始模型并在整个数据集上运行预测。计算实际值和预测之间的误差,并对不正确的预测给予更多的权重。随后,尝试修复先前模型的错误的新模型并以类似的方式创建了多个模型。我们通过对所有模型的平均值进行加权得出最终模型。
XGBoost
XGBoost(eXtreme Gradient Boosting)是一种专注于计算速度和模型性能的机器学习算法。它由Tianqi Chen引入,并目前是DMLC(分布式机器学习社区)更广泛工具包的一部分。XGBoost适用于回归和分类任务,并且专为处理大型和复杂的数据集而设计。
XGBoost支持以下类型的Boosting:
-
梯度提升,由学习率控制; -
随机梯度提升,利用行、列或列的子采样在每个分割级别; -
正则化梯度提升,使用L1(Lasso)和L2(Ridge)正则化。
从系统性能角度来看,XGBoost提供了其他一些功能,包括:
-
使用机器集群进行分布式计算来训练模型; -
利用CPU的所有可用内核在并行化树构建过程中; -
在处理无法放入内存的数据集时进行外部计算。 -
通过缓存优化充分利用硬件资源
除了上述框架之外,XGBoost还具有以下特点:
-
支持多种类型的输入数据; -
适用于树和线性增强器的稀疏输入数据; -
支持使用自定义的目标函数和评估函数。
LightGBM
LightGBM是由Microsoft开发的一个分布式高性能框架,用于排序、分类和回归任务,并使用决策树进行模型构建。
LightGBM的优点如下:
-
LightGBM是一种基于直方图的算法,能够执行值分桶,这样可以在提高训练速度和准确性的同时需要更少的内存。 -
LightGBM对于大型和复杂的数据集也具有良好的兼容性,但在训练过程中速度更快。 -
LightGBM支持并行学习和GPU学习,提供了更高的计算效率。
与XGBoost中的水平增长(level-wise)不同,LightGBM采用了垂直增长(leaf-wise),这可以减少更多的损失,从而提高准确度并加快训练速度。然而,这种方法可能导致过度拟合训练数据,但可以通过指定最大深度参数来控制分割发生的位置。因此,相比较而言,XGBoost能够构建更稳健的模型。
XGBoost和LightGBM的差异
XGBoost和LightGBM之间的结构差异主要体现在以下几个方面:
-
叶子生长:LightGBM采用了基于梯度的一侧采样(GOSS)和独家功能捆绑(EFB)两种新技术。GOSS保留梯度较大的实例,并对梯度较小的实例进行随机采样,从而提高了执行速度和准确性。EFB则将稀疏空间中很少同时取非零值的特征捆绑在一起,降低了维度并提高了效率。相比之下,XGBoost使用预排序和基于直方图的算法来计算最佳分割。 -
分类特征处理:LightGBM可以轻松处理分类特征,通过设置参数来检测哪些列是分类列,并使用相等性拆分处理。而XGBoost默认将分类特征视为有顺序的数值变量,需要进行额外的处理,例如进行one-hot编码,但对于大型数据集可能会导致时间开销较大。 -
缺失值处理:两种算法都通过将缺失值分配给每次分割中损失减少最多的一侧来处理缺失值。 -
特征重要性方法:两种算法都提供了特征重要性的计算方法。XGBoost和LightGBM都支持增益方法,即特定特征在特定树的上下文中的相对贡献。而分割/频率/权重方法,在LightGBM中称为分割,而在XGBoost中称为频率或权重方法,计算特征在模型树的所有分割中出现的相对次数。另外,XGBoost还提供了覆盖范围方法,用于计算每个特征的相对观察数量。
XGBoost和LightGBM的重要参数说明
XGBoost的重要参数如下:
-
n_estimators:集合中树的数量,默认值为100,较高的值可以提高模型性能,但会增加训练时间。 -
max_depth:树的最大深度,默认为3,控制模型的复杂度和拟合能力。较小的值可能导致欠拟合,较大的值可能导致过拟合。 -
min_child_weight:树节点上的最小权重总和,默认为1。通过限制树的深度来进行正则化,较大的值可以降低过拟合的风险。 -
learning_rate/eta:学习率或步长,默认为0.3。控制每次迭代中模型权重的更新幅度,较小的值可以提高模型准确性,但训练时间会增加。 -
gamma/min_split_loss:最小分裂损失,默认为0。正则化参数,控制树的分裂过程,较大的值可以降低过拟合的风险。 -
colsample_bytree:每棵树使用的特征比例,默认为1.0。控制每棵树使用的特征数量,降低过拟合的风险和训练时间。 -
subsample:每棵树使用的样本比例,默认为1.0。控制每棵树使用的训练样本数量,降低过拟合的风险和训练时间。
LightGBM的重要参数如下:
-
max_depth:与XGBoost类似,此参数指示树的生长不要超过指定深度。较高的值会增加模型过度拟合的机会。 -
num_leaves:这个参数对于控制树的复杂性非常重要。该值应小于2^(max_depth),因为对于一定数量的叶子而言,叶子树比深度树深得多。因此,较高的值可能会导致过度拟合。 -
min_data_in_leaf:该参数用于控制过拟合。较高的值可以阻止树生长得太深,但也可能导致算法学习较少(欠拟合)。根据LightGBM的官方文档,作为最佳实践,它应该设置为数百或数千的数量级。 -
feature_fraction:类似于XGBoost中的colsample_bytree参数,指示每棵树使用的特征比例。它可以降低过拟合的风险并加快训练速度。 -
bagging_fraction:类似于XGBoost中的subsample参数,指示每棵树使用的样本比例。它可以降低过拟合的风险并加快训练速度。
XGBoost和LightGBM的性能比较
下图比较了两种算法在相同任务下的运行时间。你会发现,随着样本数量的增加,XGBoost的训练时间呈线性增长,也就是说,数据越多,训练时间越长。与之相对,LightGBM的训练时间并没有增长较多。LightGBM之所以能够在训练时间上表现得更好,是因为它采用了一些高效的技术和算法。比如,它使用了基于直方图的决策树分裂和Leaf-wise生长策略。这些优化方法使得LightGBM可以更快地训练模型,特别是在处理大规模数据集时效果显著。
因此LightGBM能够在更短的时间内完成模型训练,同时保持良好的性能。所以,如果你需要在有限时间内训练模型,LightGBM是一个非常值得考虑的选择!它可以提高训练效率,让你更快地得到结果。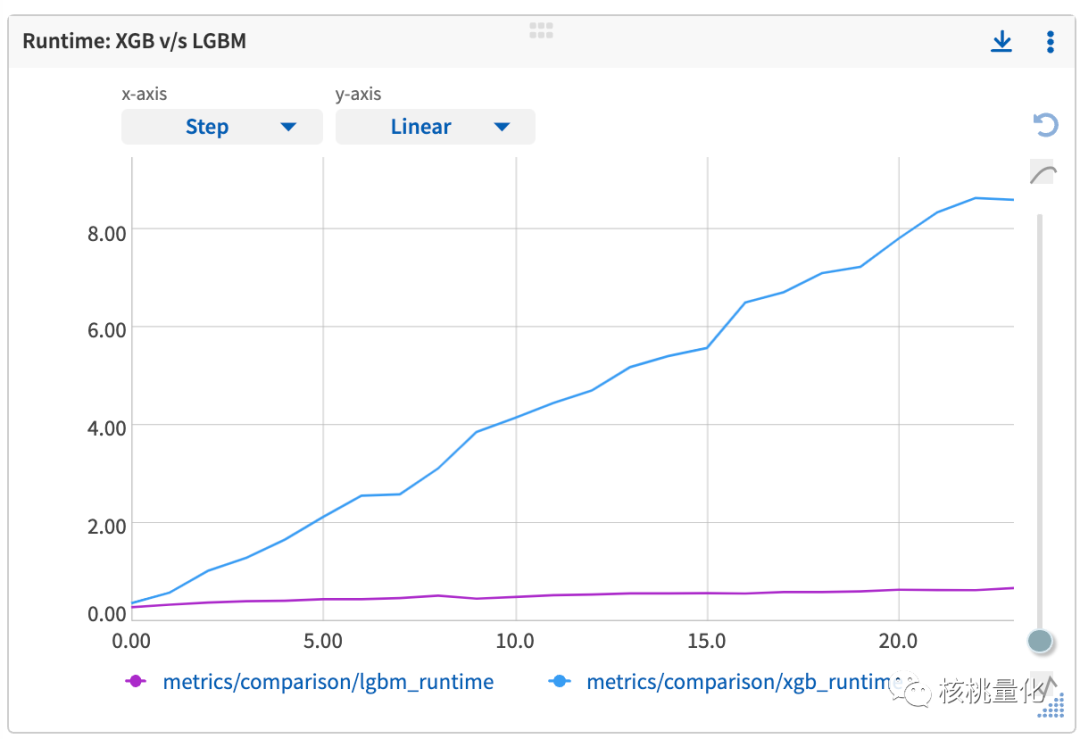
下图显示在不同样本量下,XGBoost和LightGBM之间的准确度分数差距并不明显。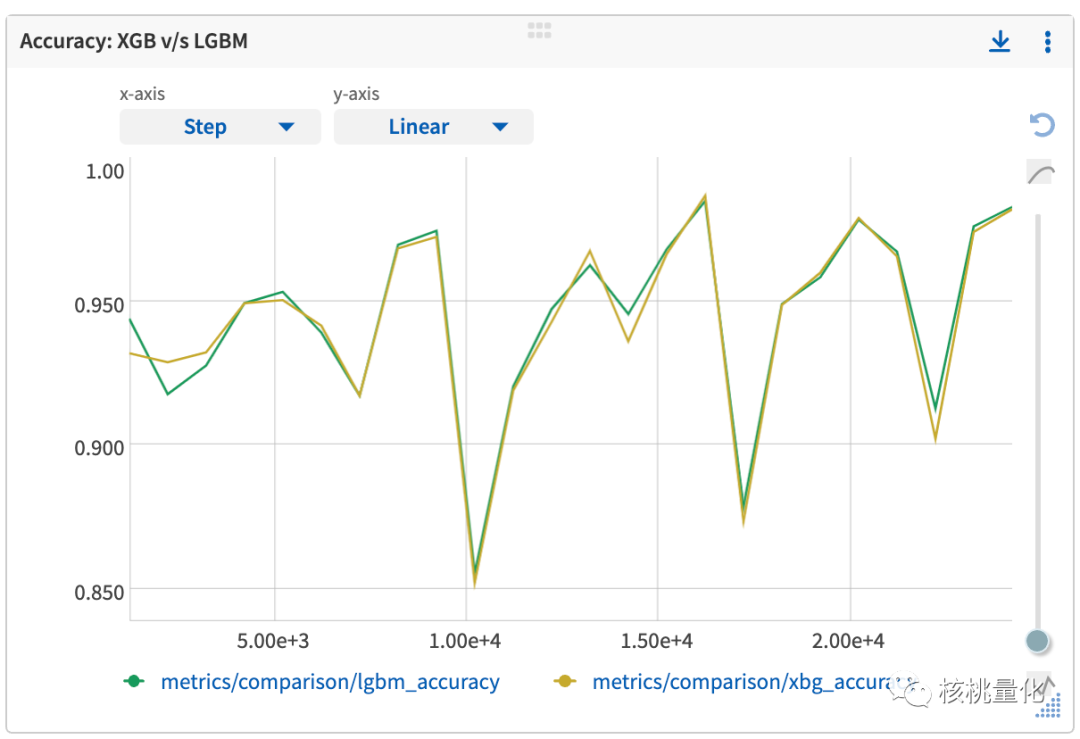
总结
选择使用XGBoost还是LightGBM取决于项目的限制和需求。如果内存受限或需要更短的训练时间,特别是在处理大型数据集时,LightGBM是更好的选择。如果没有技术限制,并且需要广泛的文档和社区支持,以及更多的参数调整选项,那么XGBoost可能是更好的选择。XGBoost通常被认为是比LightGBM更常用和更好的梯度增强模型。它具有出色的性能、抗过度拟合能力,以及丰富的文档资源和参数调整选项。然而,这并不意味着LightGBM在所有情况下都不如XGBoost。根据项目的具体需求和限制,选择最适合的模型是很重要的。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111100
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





![[通达信指标]基本面组合公式1](https://95sca.cn/2024/08/07/m3fb3hzZLlKWo3Q1722995263.591668.jpg?imageMogr2/thumbnail/!480x300r|imageMogr2/gravity/center/crop/480x300)