
一 本文概要
在很多现实机器学习应用中,小样本的表格任务是很常见的,这是因为标注的成本很高或很难收集新的样本。虽然小样本学习已经是一个研究领域已有一段时间了,但主要的研究工作都集中在计算机视觉领域。相较于图像数据,表格数据具有更高的维度和异质性,因此在表格任务中进行有效的小样本学习仍然面临许多挑战。本文提出了一个简单而有效的框架STUNT,用于小样本的半监督表格学习。其关键思想是通过将随机选择的列作为目标标签,自动生成不同的小样本学习任务,然后使用元学习方案来学习具有构造任务的可概括知识,通过引入了一种无监督验证方案,利用STUNT从未标记的数据中生成伪验证集来进行超参数搜索和早期停止。实验结果表明,相较于之前的半监督和自我监督基线,STUNT在各种小样本表格任务基准下都带来了显著的性能提升。
STUNT的核心思想是通过采样生成不同的学习任务,使用元学习来学习元知识,以达到进一步提高模型的性能的效果。
二 背景知识
在机器学习应用中,学习少量标记样本通常是一个重要因素。然而,在各种领域中,包括图像和语言,积极开发了各种少样本学习方案,但在表格领域中,这样的研究尚未得到充分的开发。特别是,在各种表格数据集中,少样本表格学习是一个关键的应用,因为各种表格数据集遭受高成本的标注,例如金融数据集中的信用风险,并且甚至出现在收集新样本以进行新任务方面存在困难,例如患有罕见或新疾病的患者。为了解决这些有限的标签问题,不同领域的共识是利用未标记的数据集来学习可泛化和可转移的表示形式。
为了在很少标记样本的情况下学习有效的表示,先前的工作建议利用未标记样本。这类工作大致可分为半监督和自我监督两种方案。对于半监督学习方法,一种常见的方法是通过使用模型的预测为每个未标记的数据生成伪标签,然后用相应的伪标签训练模型。更先进的方案利用动量网络和具有数据增强的一致性正则化来生成更好的伪标签。另一方面,自我监督学习方案的目的是通过使用特定领域的归纳偏差对表征进行预训练,然后对一些标记样本进行微调或调整。两种方法的工作都严重依赖于扩充方案,但由于表格数据集的异质性,尚不清楚如何将这种方法扩展到表格数据领域。
三 本文工作
本节的工作介绍了一个利用无监督元学习的有效少样本表格学习框架,称为STUNT,关键思想是将随机选择的特征列视为目标标签,以自行生成不同的小样本任务用以学习具有元知识的神经网络表示。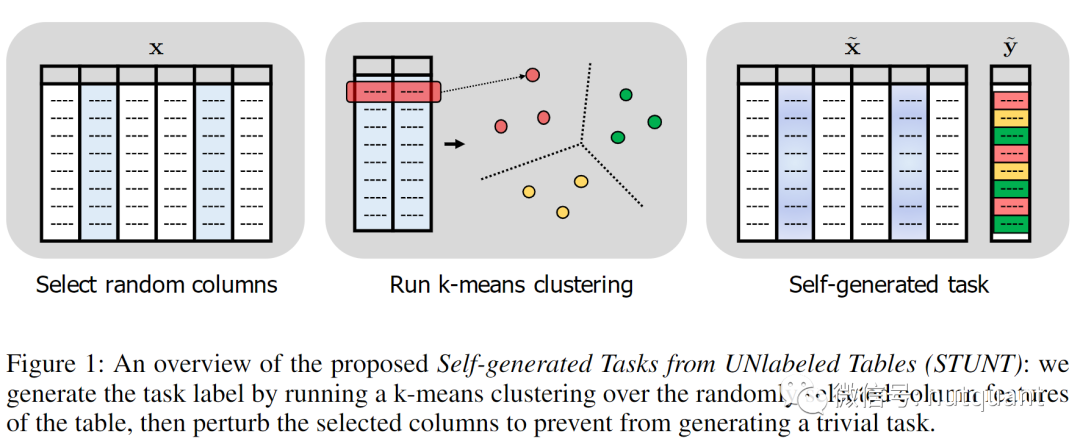

生成任务
STUNT关键想法是将表格数据的列特征视为有用的伪标签,并从未标记数据生成多样化的任务集合。直观地说,由于表格数据的异构性(即每一列拥有不同的特征值),任何Label类型都可以被视为表格列,因此也可以将任何列特征重新考虑为任务Label。特别是存在某些与原始标签高度相关的列,因此使用此类列特征构建的新任务与原始分类任务非常相似。例如,通过“BMI”和“年龄”预测“糖尿病”的原始任务与通过“BMI”和“年龄”预测“血糖”的新任务非常相似。基于这种直觉,STUNT通过对随机选择的列运行k-means聚类来生成伪标签,以提高多样性并增加采样高度相关的列的可能性(与原始标签)。
使用生成的任务进行元学习
基于生成的任务,STUNT利用ProtoNet对网络进行元学习。在网络的嵌入空间上执行非参数分类器。ProtoNet是一种用于元学习的算法,它使用原型网络作为元学习分类器。具体来说,在ProtoNet中,嵌入空间被学习,可以通过计算到每个类原型向量的距离来执行分类,其中原型向量是每个类样本的平均嵌入向量。因此,ProtoNet可以使用少量标注数据生成元任务,并应用于具有不同类别数目和特征的数据集。此外,ProtoNet非常适合于处理表格数据,因为表格数据中的列通常对应于分类问题中的特征。
四 实验结果
实验结果表明,相较于之前的半监督和自我监督基线,STUNT在各种小样本表格任务基准下都带来了显著的性能提升。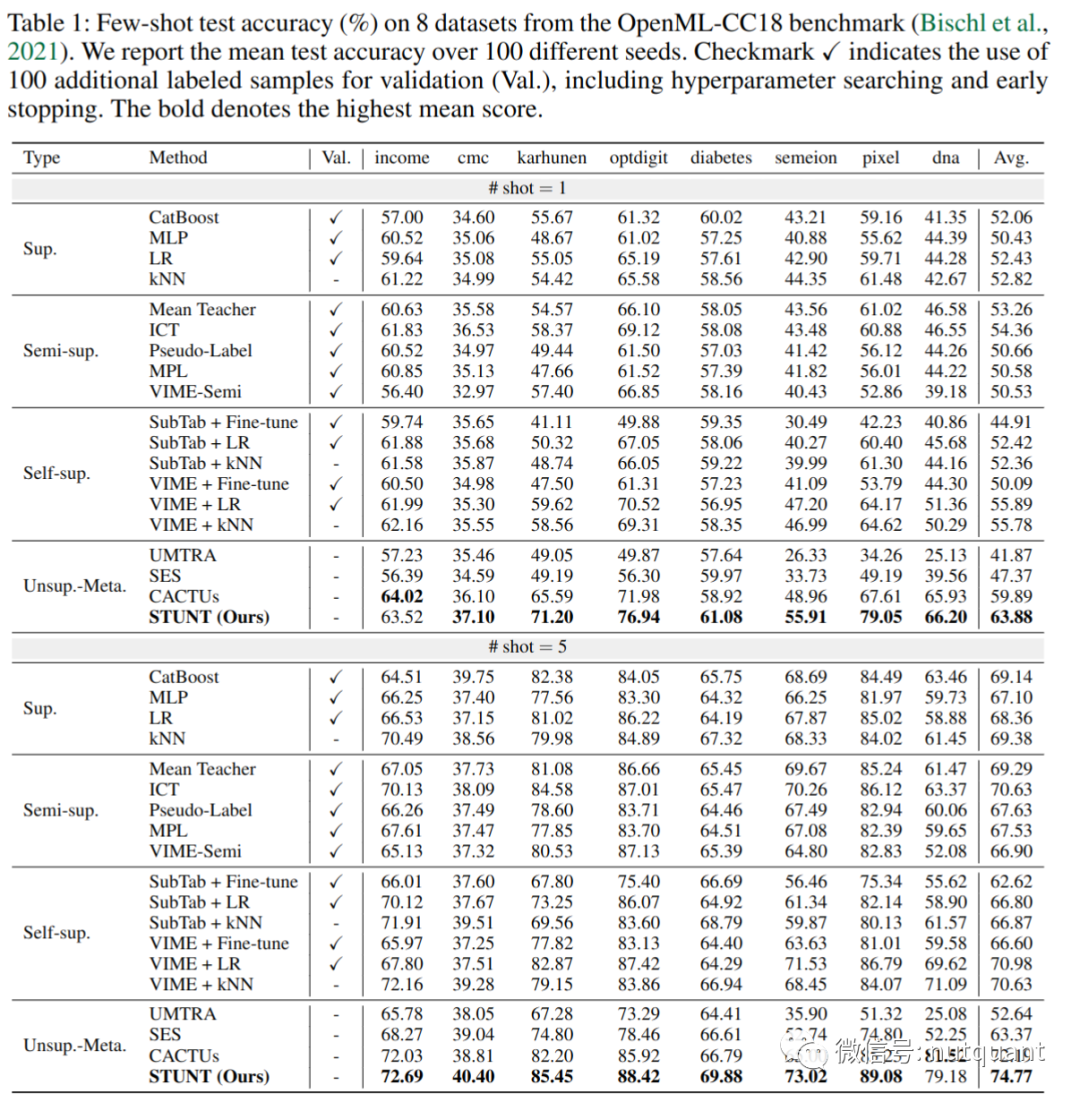

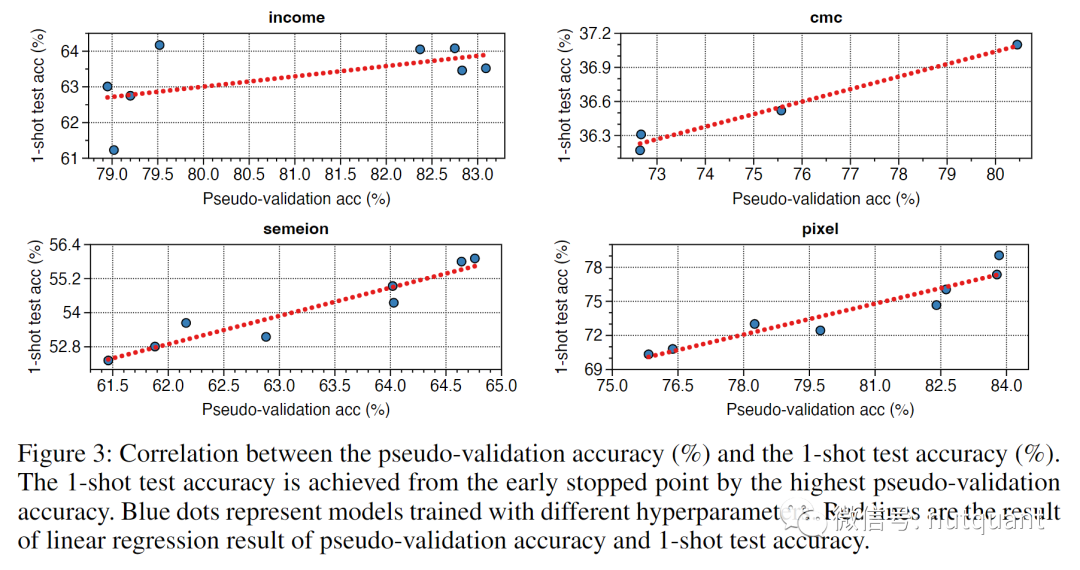
五 总结展望
本文提出了STUNT来解决表格任务上的小样本学习问题,它可以从未标记的表格中元学习生成任务。在不同类型的表格数据集上进行的各种few-shot分类任务验证了STUNT的有效性。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111089
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!