
一 本文概要
虽然深度学习在图像、音频和文本等同质数据领域取得了显著的成果,但对于表格数据而言,这种技术的表现并不是最佳的。目前,浅层模型(如梯度提升决策树)被认为是处理表格数据的最新技术。机器学习社区的研究表明,即使是最新的深度学习模型,在处理表格数据时仍然存在性能、训练和推理时间等方面的差距。此外,Kaggle上的许多机器学习竞赛也证明了浅层模型(如GBDT)在表格数据任务上仍然非常有效。因此,本文提出了一种名为门控添加树集成(GATE)的新深度学习架构,它是一种高性能、参数效率高和计算效率高的方法,专门用于处理表格数据。GATE使用一个门控机制作为特征表示学习单元,并带有内置的特征选择机制。通过与可微分且非线性的决策树集合组合,并通过简单的自我注意力进行重新加权,以预测所需的输出。通过在多个公共数据集上进行的实验(包括分类和回归),GATE被证明是现有技术(如GBDT、NODE、FT变换器等)的竞争性替代方案。
二 背景介绍
表格数据是以表格形式存储的结构化数据,每一行对应一个数据样本,每一列对应一个特征。表格数据任务是指对表格数据进行分析、处理或建模,以达到特定的目标,如分类、回归、聚类、预测等。在现实生活中,许多领域(如金融、医疗、广告等)都需要对表格数据进行任务处理。例如,在医疗领域,可以使用表格数据来诊断某些疾病或评估药物疗效;在金融领域,可以使用表格数据来预测股票价格或者风险等级。
虽然深度学习在计算机视觉、自然语言处理等领域取得了显著的成果,但在处理表格数据任务方面,深度学习模型的表现并不如树模型。大多数从业人员和数据科学竞赛仍然倾向于使用树模型处理表格数据任务。之前的一些工作也解释了为什么会出现这种现象。主要原因包括三个:神经网络偏向输出过于平滑的解,无信息特征对神经网络影响更大,神经网络对特征的旋转具有不变性,但是表格数据通常不具备旋转不变性。
三 本文贡献
本文尝试通过引入了门控添加树集成(GATE),这是一种新的专为表格数据设计深度学习架构,以提高深度学习模型在表格数据任务上的表现。
主要贡献可以总结如下:
-
本文引入了一个新颖的门控机制,灵感来自门控循环单元(GRU),用于表示学习。 -
本文提出了一种新颖的非线性决策树架构,具有参数效率和可扩展性,适用于具有数千个特征的大型数据集。 -
本文使用大量数据集进行实验,展示了GATE架构在能获得竞争性的性能前提下,同时保持了更好的参数效率和计算效率。
四 本文工作
GATE架构是专门根据以下原则设计的:
-
使用特征学习单元通过非线性处理原始特征来选择和学习新特征; -
基于所学习的特征构建多个多层可微分决策树; -
将输出组合在加权集成中,其中权重是从数据中学习的。
GATE模型有两个主要阶段:
-
首先使用一系列门控特征学习单元(GFLU) 来处理输入特征。GFLUs通过特征选择和特征交互来学习最佳特征表示,然后使用不同可训练的非线性决策树(DNDTs)的集成来对所学习的表示进行处理。 -
最后使用self-attention机制重新加权所有树的输出,并用于模型的最终预测。
GFLU模块
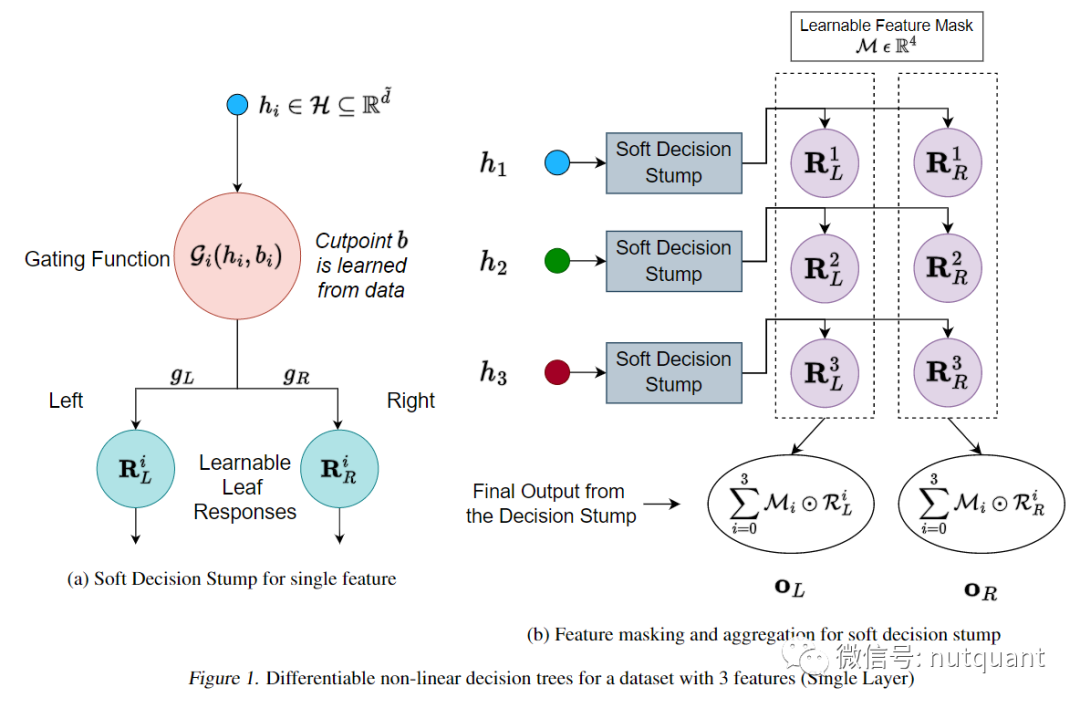
Gated Feature Learning Unit(GFLU)是一种架构,它受到GRU中的门控单元的启发。GFLU从原始特征中选择要使用的信息,并使用其内部机制来学习创建任务的所需的最佳特征集。这允许下游模块将其学习能力集中于只对任务最重要的特征,从而变得更加高效。为了实现重要特征的软选择,GFLU使用可学习的掩码M,对GFLU中特征学习的每个阶段进行特征选择。掩码是通过对可学习参数向量W进行稀疏变换来构造的,并鼓励稀疏性。为了实现稀疏性,建议使用α-entmax变换。单个GFLU的架构如下图所示:

门控机制将应用特征掩码后的输入𝑋_𝑛作为输入,并学习特征表示𝐻_𝑛。GFLU学习隐藏的特征表示。与标准GRU不同,不同GFLU之间的权重不共享,因为希望在特征表示在每个阶段应用不同的转换。
在任何阶段𝑛,隐藏特征表示是前一个特征表示𝐻_(𝑛−1)和当前候选特征表示 𝐻̃_𝑛 之间的线性插值: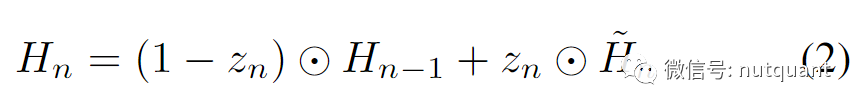
其中𝑧_𝑛是更新门,决定使用多少信息来更新其内部特征表示。更新门的计算方式为: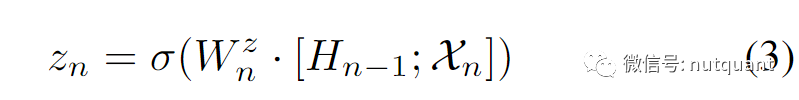
其中[𝐻_(𝑛−1); 𝑋_𝑛]表示𝐻_(𝑛−1)和𝑋_𝑛的连接操作,σ是Sigmoid激活函数,𝑊_zn是可学习参数。
候选特征表示𝐻̃_𝑛的计算方式为: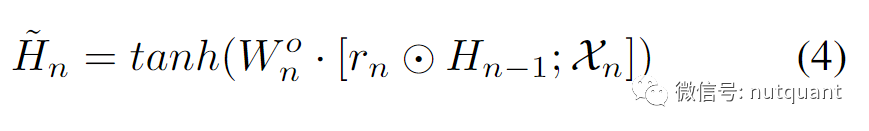
其中𝑟_𝑛是重置门,决定要从先前的特征表示中遗忘多少信息,𝑊_𝑜𝑛 是可学习参数,[ ]表示连接操作,r_n和H_(n-1)之间使用元素乘法。
重置门(𝑟_𝑛)的计算方式与更新门类似: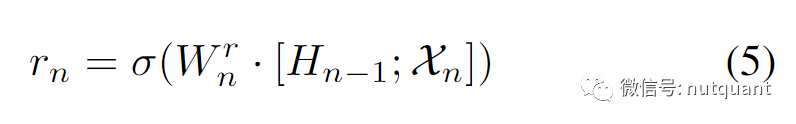
在实现中可以使用单个矩阵𝑊_𝑖𝑛来同时计算重置门和更新门,以节省计算量。可以堆叠任意数量的这样的GFLUs以鼓励特征的分层学习,最后一个GFLU阶段的特征表示𝐻在随后的阶段中进行使用。
可微非线性决策树(DNDT)
DNDT模块的输入为从最后一个GFLU阶段学习到的特征表示𝐻。该模块的目标是学习一个函数F。决策树方法通过递归地将特征空间划分为不相交的区域并为每个区域分配一个标签来构造函数F。而非线性决策树在决策树的每次分裂中以非线性方式使用所有特征,本文采用的是非线性决策树。
二叉决策树模型使用一系列分层节点进行决策,每个节点可以视为一个二进制分类器,将样本路由到左侧或右侧叶子节点。它选择单个特征,并从数据中学习一个值以形成对左侧或右侧叶子节点的硬路由,可以将这看作是一个门控函数 (G(hi,bi))。在标准决策树模型中,这个门控函数是Heaviside函数,由于不可微。本文工作采用了软分箱函数,并进行了以下修改:
-
替换softmax函数为α-entmoid函数以鼓励叶子节点得分的稀疏性; -
修改一次性对所有特征进行分箱,降低了运行时间。 -
改进了过程,使其仅限于二叉树,消除了一些昂贵的操作,再次降低了运行时间。
集成多棵树
将多个预测器的预测组合成一个单一预测器是机器学习中的一个流行思想。通过这种方法,得到的预测器通常比集合中的任何单个预测器更准确。本文使用多个DNDT进行加法集成。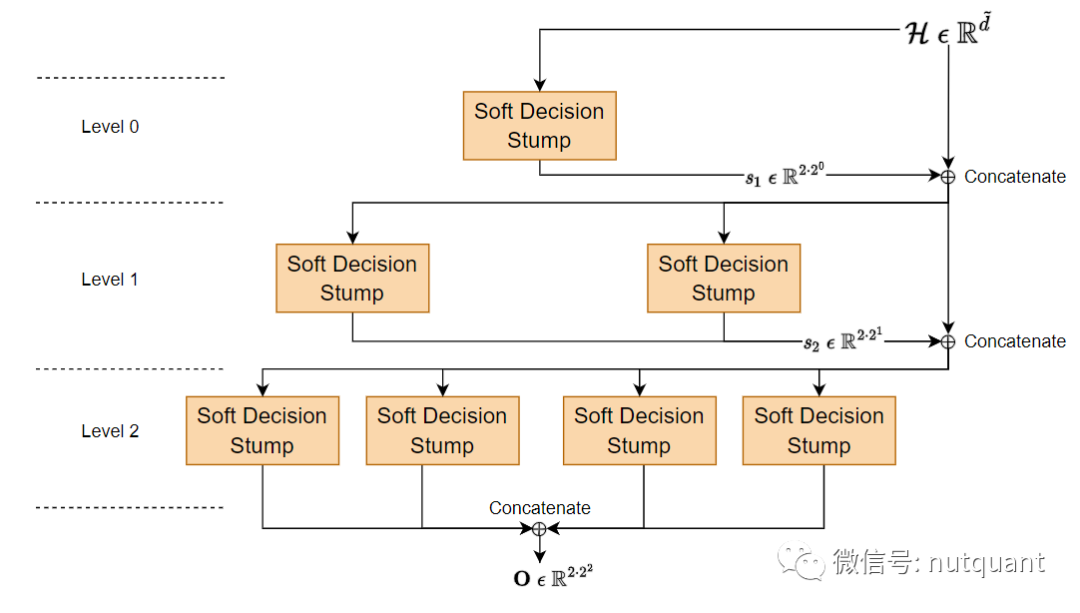
由于所有的 DNDT 都是从相同的特征集上进行训练的,因此各自的树输出必然具有一些内部联系和关系。为了充分利用这种内部关系,本文使用self-attenstion对树的输出进行重新加权。
将每棵树的叶节点响应向量转换成期望的输出。最终模型的预测结果根据以下公式确定:
构建加法集成有两种方法:Bagging和Boosting。Bagging使用并行树的方式,将所有的DNDTs从相同的输入集合并行执行,然后将输出组合在一起;Boosting使用链接树的方式,以链式形式连接这些树,使得前一棵树的输出成为下一阶段树的输入。实验表明,这两种形式都能很好地发挥作用,但是Boosting需要更多的计算开销,因为DNDT需要处理更多的特征。在没有采用链式树的情况下可以利用树的并行处理加速推理过程。
五 实验分析
数据集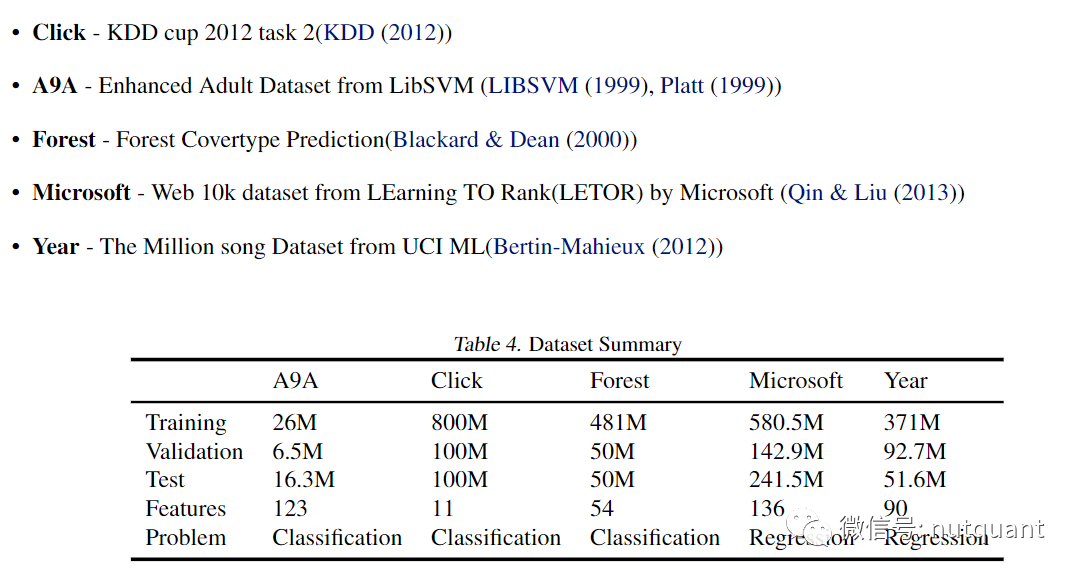
实验结果
在不同的数据集上,所有模型的表现都有所不同。但是相比于其他DL模型,GATE的表现波动性似乎更小,表现出更高的平均排名。在5个数据集中,GATE的表现优于当前SOTA(LightGBM)的3个数据集。虽然GATE可能不会在所有数据集中取得最佳表现,但它始终能够获得接近顶部的位置,显示其稳健性。与其他竞争的DL方法相比,GATE在接近最佳误差方面非常稳定,在YEAR数据集中表现尤为明显。此外,在参数量和计算效率方面,GATE也超过了其他竞争的DL模型。
六 总结分析
本文提出了一种新型的基于门控加法树集成(GATE)的表格数据深度学习架构。GATE使用受GRU启发的门控机制作为特征表示学习单元,并配备了内置的特征选择机制,将其与可微分、非线性决策树结合起来,再使用简单的自注意力进行重新加权,以建模所需的输出。在多个公共数据集上(包括分类和回归),GATE的实验验证了它不仅与诸如GBDT等方法相竞争,而且比竞争的DL方案更具参数和计算效率。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111088
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!