
一 什么是特征暴露?
在监督学习中,模型通过学习输入特征与输出预测之间的关系来进行训练。然而,在实际应用中,数据的分布可能会随时间变化或其他因素发生变动。这意味着在不同的时间段或环境中,某些特征可能具有更强的预测能力,而其他特征则可能变得不那么重要甚至具有负面影响。
特征曝露(Feature exposure)是指在监督学习模型中,某个特征对于预测结果的影响程度或重要性。它反映了模型在训练过程中对于不同特征的选择和权重分配情况。特征曝露的概念旨在衡量模型对不同特征的依赖程度和平衡性。如果模型过于依赖一小部分特征,可能在短期内表现出色,但在长期内可能因为特征的失效或变化而导致性能下降。相反,一个具有较低特征曝露的模型,即对各个特征的依赖程度相对平衡,能够在不同的时期和环境中保持更为一致的性能。
二 如何衡量特征暴露?
特征暴露度被描述为衡量模型曝露与特征平衡程度的指标。这一指标考虑了模型对特征的依赖性以及特征的预测能力的变化性。通常可以使用相关系数来衡量特征暴露的程度,下面是一个使用斯皮尔曼等级相关系数来衡量特征暴露度的代码示例:
import numpy as np
from scipy.stats import spearmanr
PREDICTION_NAME = "Label"
# 算给定数据框 df 中各个特征与预测值之间的 Spearman 相关系数,返回一个特征暴露度的数组
def feature_exposures(df):
feature_names = [f for f in df.columns if f.startswith("feature")]
exposures = []
for f in feature_names:
fe = spearmanr(df[PREDICTION_NAME], df[f])[0]
exposures.append(fe)
return np.array(exposures)
# 计算给定数据框 df 中特征暴露度的最大值(绝对值)
def max_feature_exposure(df):
return np.max(np.abs(feature_exposures(df)))
# 计算给定数据框 df 中特征暴露度的均方根
def feature_exposure(df):
return np.sqrt(np.mean(np.square(feature_exposures(df))))三 通过特征暴露评估模型性能
现在我们来比较两个样本内(训练集)表现非常相似的模型在样本外(验证集)上的表现。NeuralNet8和NeuralNet19是两个神经网络模型,样本内的表现非常相似,夏普比率可以达到1.09左右。它们的样本内最大特征暴露略有不同(分别为NeuralNet8的0.257和NeuralNet19的0.325)
下图展示了两个模型在样本外(验证集)上的表现,可以看到NeuralNet8的样本外夏普比率0.7127,显著高于NeuralNet19的0.6275。证明了具有较低样本内最大特征暴露(NeuralNet8)的模型在样本外相关性和夏普比率上似乎表现更好。而且较差的模型(NeuralNet19)在样本外的最大特征暴露方面似乎较低。在评估模型时,同时观察样本内和样本外的最大特征暴露会更有帮助。。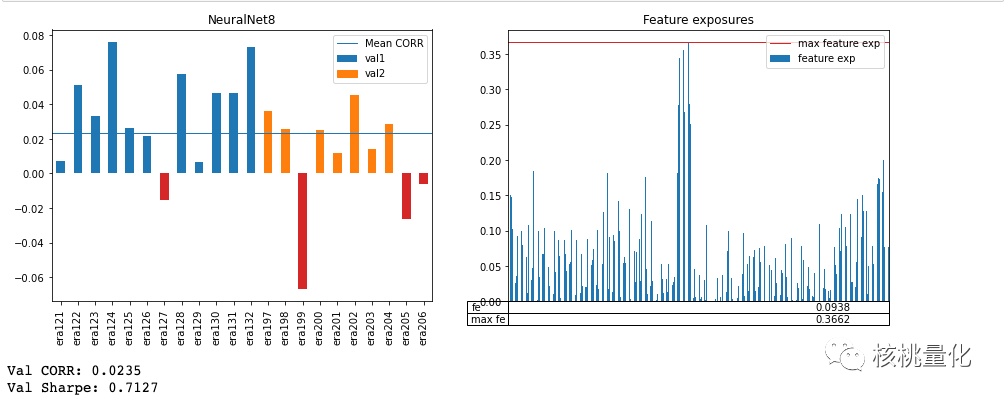

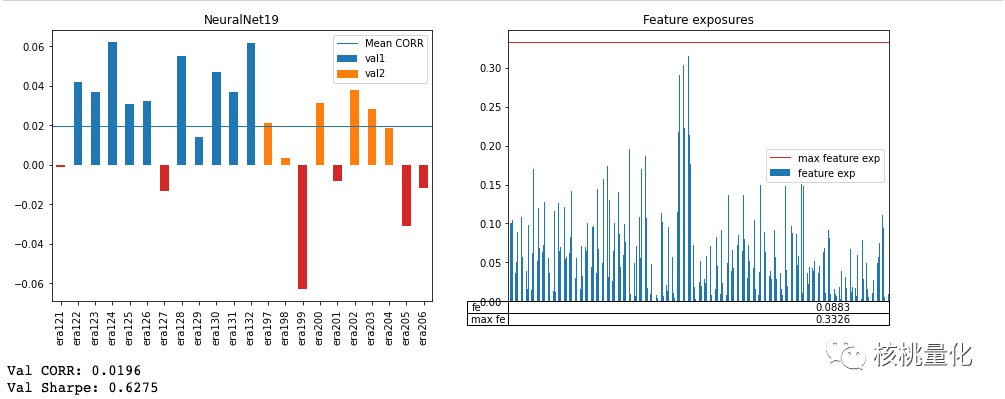
最大特征曝光和样本外性能之间的逆相关性似乎在各种类型的模型中普遍存在。为了解释这一点,下面收集了80个不同梯度提升树和神经网络模型的数据来进行可视化,可以清楚的看到样本外(验证)和样本内(训练)的最大特征曝光与样本外夏普比率之间的关系。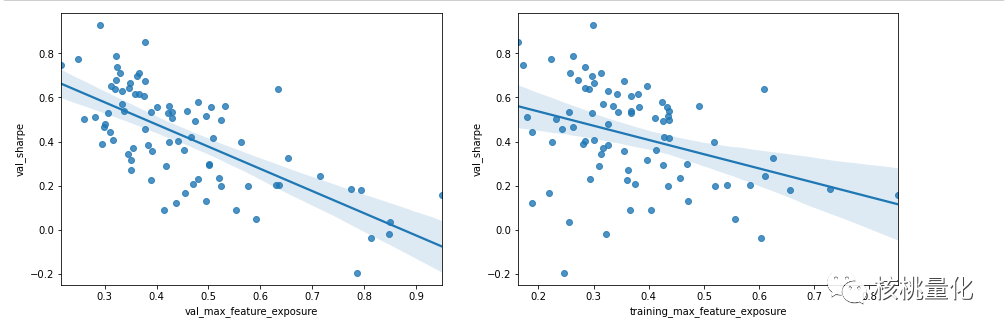
四 降低特征暴露以提升模型性能
根据之前的分析,通过减少特征暴露度,可以提高模型的泛化能力,使其在未见过的数据上表现更好。特征中和通过消除预测结果与特征之间的线性相关性,保留了非线性相关性部分,从而减少了特征的暴露。这有助于改善建模的效果,使模型更准确地捕捉到非线性因素对预测结果的影响。
特征中和的示例代码如下:
def neutralize(df, target="prediction_kazutsugi", by=None, proportion=1.0):
if by is None:
by = [x for x in df.columns if x.startswith('feature')]
scores = df[target]
exposures = df[by].values
# 添加常数列以确保序列对特征的暴露完全中性化
exposures = np.hstack((exposures, np.array([np.mean(scores)] * len(exposures)).reshape(-1, 1)))
# 计算特征矩阵的伪逆(广义逆矩阵)来获取线性模型的系数,
# 这个系数可以用来建模特征与预测值之间的线性关系。
# 将特征矩阵与系数相乘,得到了刚刚拟合的线性模型对于给定特征的预测结果。
# 使用线性模型来预测目标值,其中模型的系数反映了特征对于预测的相对重要性和方向。
scores -= proportion * (exposures @ (np.linalg.pinv(exposures) @ scores.values))
# 对输出进行标准化
return scores / scores.std()
下图对比了使用特征中和前后的模型表现,可以看到,在进行特征中和处理后,特征的暴露度和最大特征值都显著降低了(特征暴露均值从0.0850下降到0.0061,最大特征暴露值从0.2955下降到0.0153)。这意味着模型对这些特征的依赖程度减少了。验证相关性略微降低(从0.0291下降到0.0255),但样本外夏普比率却提高了(从0.9608提升到了1.2436)。夏普比率是衡量投资组合风险与回报之间关系的指标,提高的夏普比率意味着模型在风险和回报之间取得了更好的平衡。

发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/110999
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!