
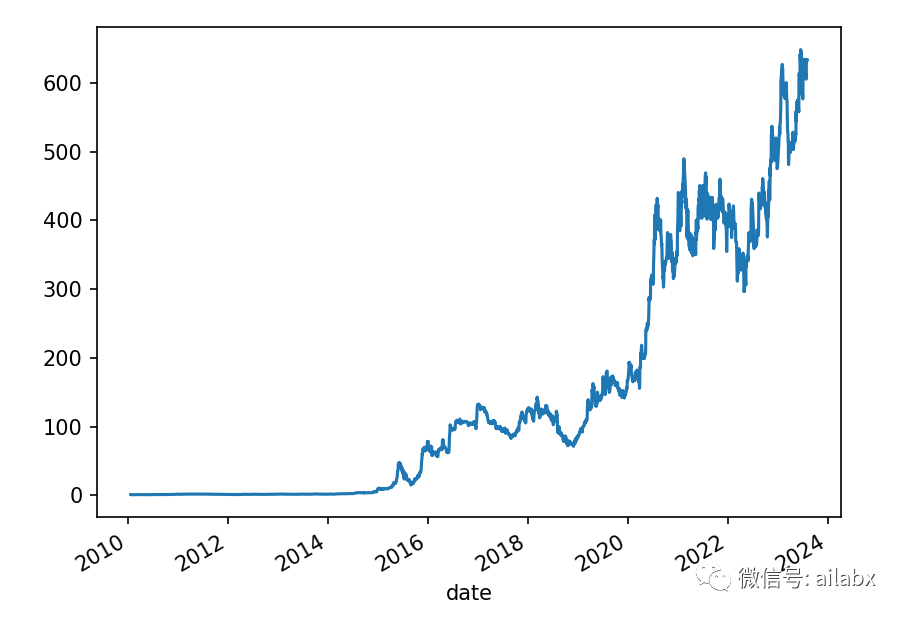
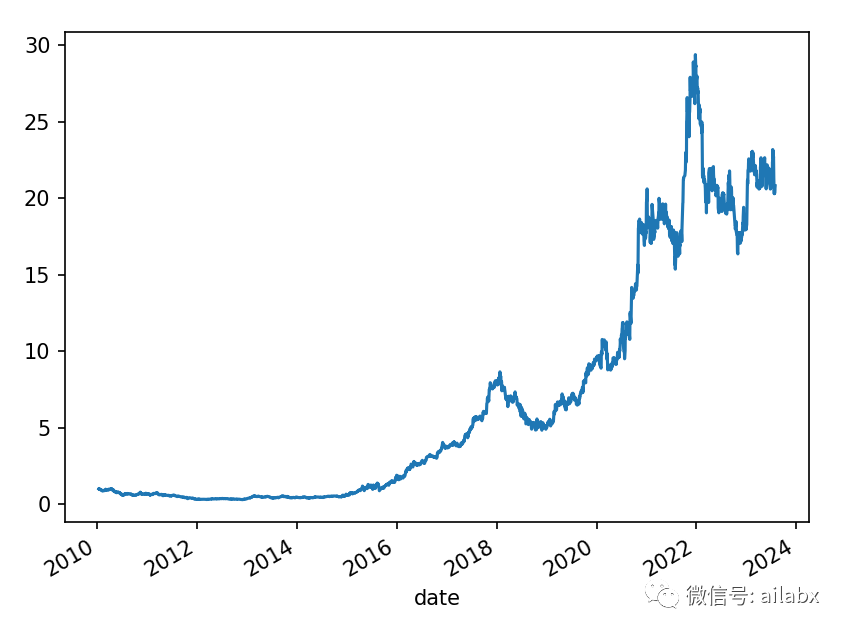
年化63.9%,夏普1.4,交易出乎意料,我们还在持续的挖掘因子,这个开局效果不错。


代码在工程这个位置:(欢迎大家找问题),代码和数据已经在星球更新:知识星球与开源项目:万物之中,希望至美
需要说明的事,没有考虑成本与滑点,只为演示因子效果,因为这还不是我们的最终策略,最终一定是一组多因子合成的效果,回撤会比这个好,才可以交付实盘验证。
import pandas as pd # 把昨天的文件包,放在ailabx/data下的hist_hs300_20230813下,使用duckdb直接访问 from engine.config import CSVS_DIR from engine.datafeed.dataloader import Duckdbloader symbols = ['000001.SZ', '000002.SZ'] loader = Duckdbloader(symbols=None, columns=['close', 'open', 'volume'], start_date="20100101") fields = ["-1 * correlation(open, volume, 10)", "close/shift(close,1)-1"] names = ["量价背离_10", 'return_0'] df = loader.load(fields=fields, names=names) df.dropna(inplace=True) print(df) from engine.env import Env from engine.algo.algo_weights import * from engine.algo.algos import * e = Env(df) e.set_algos([ #RunDays(5), # SelectBySignal(buy_rules=['ind(roc_20)>0.02'], sell_rules=['ind(roc_20)<-0.02']), SelectTopK(K=1, order_by='量价背离_10'), WeightEqually() ]) e.backtest_loop() e.show_results()
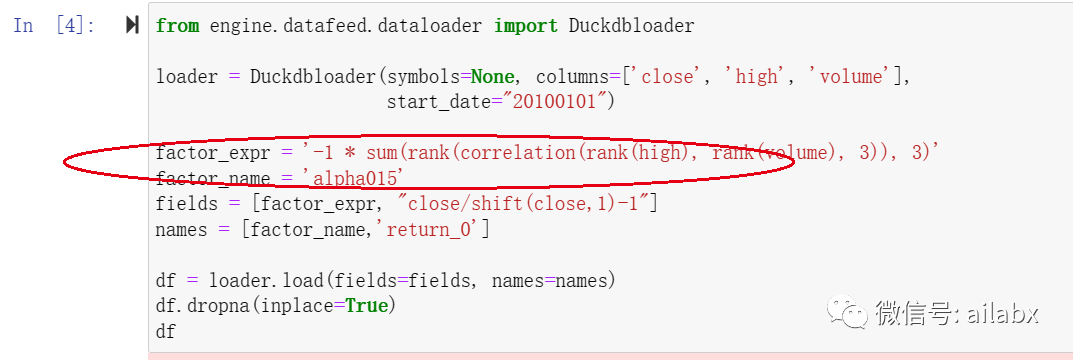
继续搞因子:Alpha015: (-1 * sum(rank(correlation(rank(high), rank(volume), 3)), 3))
涉及几个函数:sum, rank,还有昨天我们用过的correlation。
def sum(se: pd.Series, N): se = se.groupby('symbol', group_keys=False).apply(rolling, N, 'sum') return se # index.name = 'date',默认都是序列内部,序列间的需要合并df后来计算。 def rank(se: pd.Series): rank_result = se.groupby('date').rank(pct=True) return rank_result
sum是N个序列值求和,比如简单。
rank是按date来groupby,也就是某一天的截面数据计算百分位。
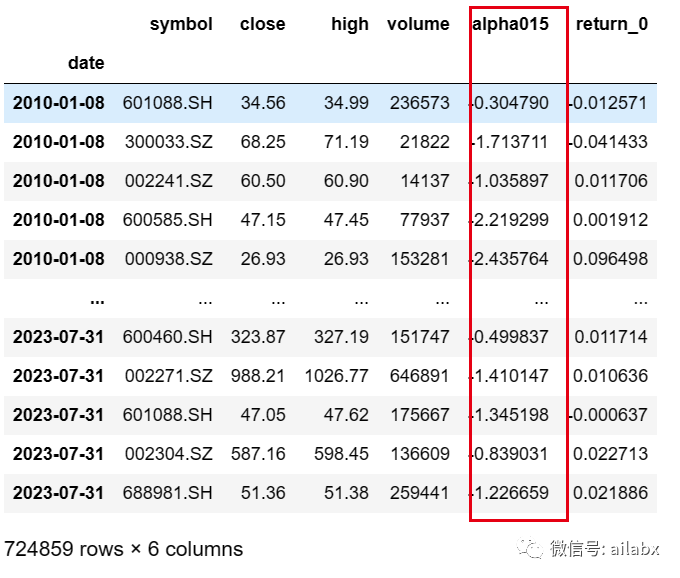
本质上说,alpha015与昨天的alpha006类似,都是“价量背离”,只是选取最高价与成交量的负相关关系,这里进行了组内的排名,求和等复杂运算。但结果显示,alpha015的ic值要差一些。
复杂就不一定就是好的。
这个单回子回测的年化收益是26%。
因子是无穷多的,因子并不是越多越好,效果差的因子合成进来,对总体结果会有影响。
我们也无法指望机器学习模型能够“自动”甚至“智能”的去拟合这个结果,导致的结果要么不拟合,要么过拟合。
一些感悟:
今天发现自己的手机号有快递,结果查询状态,没有发件人信息,只有物流的揽件信息,然后快递在运送途中,另外目的地也没有说送到哪。
有没有朋友知道这个什么情况。
之前有收到过类似的”测试件“,里边是一张类似答谢,可以扫码抽奖之类的,当然直接就给扔了。不知道是个啥。
战略聚焦。好的资源永远是稀缺,包括我们的注意力,开发力量等,有限的资源,要聚焦解决“症结性难题”。
之于AI量化投资,这个挑战在于“因子挖掘”。
因子评估,传统的IC/IR分析:qlib因子分析之alphalens源码解读
更具挑战的事情是,传统的方法依靠的是线性关系,这个被挖掘得很充分了。机器学习能不能找到高维的非线性的关系,这个存疑。另外就是找“另类数据“。
当然战略就找重要的,且可解决的。利用自己的信息优势,资源优势,整合方案优势等等,这才是一个好战略。

90万条历史记录秒出:


改造后的dataloader,我去除了CsvLoader和HdfLoader,后面统一使用DuckdbLoader,这个大家注意一下,性能要好很多。
import pandas as pd import os from datetime import datetime from loguru import logger import duckdb from tqdm import tqdm import abc from engine.config import CSVS_DIR from engine.datafeed.expr import calc_expr class Dataloader: def __init__(self, path, symbols, start_date='20100101', end_date=datetime.now().strftime('%Y%m%d')): self.symbols = symbols self.path = path self.start_date = start_date if not end_date or end_date == '': end_date = datetime.now().strftime('%Y%m%d') self.end_date = end_date @abc.abstractmethod def _load_df(self): pass def _reset_index(self, df: pd.DataFrame): trade_calendar = list(set(df.index)) trade_calendar.sort() def _ffill_df(sub_df: pd.DataFrame): df_new = sub_df.reindex(trade_calendar, method='ffill') return df_new df = df.groupby('symbol',group_keys=False).apply(lambda sub_df: _ffill_df(sub_df)) return df def load(self, fields=None, names=None): df = self._load_df() df = self._reset_index(df) if not fields or not names or len(fields) != len(names): return df else: df.set_index(['symbol', df.index], inplace=True) #print(df) for field, name in tqdm(zip(fields, names)): df[name] = calc_expr(df, field) df.reset_index(level='symbol', inplace=True) df.sort_index(inplace=True) return df class Duckdbloader(Dataloader): def __init__(self, symbols, columns, start_date='20100101', end_date=datetime.now().strftime('%Y%m%d')): super().__init__(None, symbols, start_date, end_date) self.columns = columns self.columns.extend(['symbol','date']) def _load_df(self): if self.columns: cols_str = ','.join(self.columns) #cols_str += ',' + "CAST('date' AS VARCHAR)" symbols_str = None if self.symbols and len(self.symbols): symbols = ["'{}'".format(s) for s in self.symbols] symbols_str = ",".join(symbols) query_str = """ select {} from '{}/*/*.csv' where date >= '{}' and date <= '{}' """.format(cols_str, CSVS_DIR.resolve(), self.start_date, self.end_date) if symbols_str: query_str += ' and symbol IN ({})'.format(symbols_str) df = duckdb.query( query_str ).df() df.set_index('date', inplace=True) return df if __name__ == '__main__': from engine.datafeed.dataloader import Duckdbloader loader = Duckdbloader(symbols=['000001.SZ', '000002.SZ'], columns=['close', 'open', 'volume'], start_date="20100101") fields = ["-1 * correlation(open, volume, 10)"] names = ["量价背离_10"] df = loader.load(fields=fields, names=names) df.dropna(inplace=True) print(df)
直接pip install alphalens即可。
我们找一个因子:alpha101里第6个因子,比较简单但有效:
-1 * correlation(open, volume, 10):这个因子的逻辑是”价量背离“。
近10天的开盘价与成交量呈现”负“的相关关系。

整理成alphalens需要的格式:使用pandas dataframe的pivot_table:



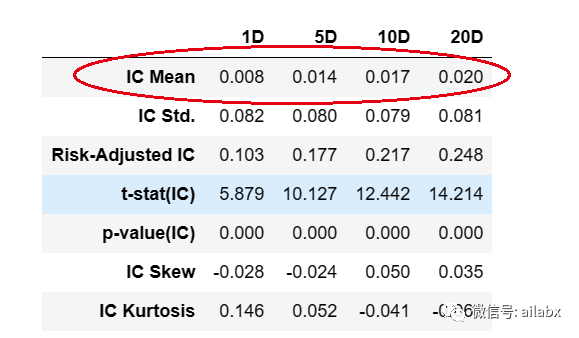
从IC/IR来看,10天/20的”预测效果“还行:


后续所有的因子列表,可能按IC/IR来排序,然后组合成一个新的有效因子!
本notebook包含的数据与代码,请前往星球更新下载:
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103989
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!