
一 论文概要
表格类数据处理是指针对二维表格形式的数据处理任务,传统机器学习所针对的分类、聚类、回归等都是这种形式的数据处理。该类数据也常见于各类算法任务和机器学习竞赛,如Kaggle比赛中。在表格数据任务中,最重要且最繁琐的一项工作就是进行特征生成,传统的手工特征生成一般会占用整个项目的80%以上的时间。本文提出的OpenFE是一套自动化的特征生成工具,不仅可以将机器学习专家从繁重的手工特征生成任务中解放出来,还能自动生成与专家手动生成相媲美的特征。OpenFE通过两个组件实现自动特征生成:(1)提出了一种新的特征提升方法,用于精确估计候选特征的增量性能。(2)特征评分框架,用于通过连续的特征二等分和特征重要性归属从大量候选中检索有效特征。实验表明,OpenFE优于现有的基准方法,在一项Kaggle竞赛中,OpenFE使用简单的基线模型生成的功能可以击败99. 3%的专业参赛者。OpenFE生成的特征所带来的性能提升与竞赛优胜者相当,甚至更高,这首次证明了自动化特征生成与机器学习专家的竞争力。
二 问题背景
在将机器学习方法应用于表格数据时,特征生成是一项重要而具有挑战性的任务。表格数据中的每一行代表一个实例,每一列对应一个不同的特征,在工业应用和机器学习竞赛中无处不在。众所周知,特征的质量对表格数据的学习性能具有显著影响。特征生成的目的是将基本特征转化为信息量更大的特征 ,以更好地描述数据并提高下游算法的学习性能。例如,股票市盈率(P/E比率)的计算公式为(股价)/(每股收益),它是从财务报表中的基本特征”股价”和”每股收益”中得出的,它向投资者说明了一家公司的价值。在实践中,数据科学家通常使用他们的领域知识以试错的方式找到有用的特征变换,但这需要大量的人力和专业知识。
由于手动特征生成耗时且需要领域专家知识,因此自动特征生成成为自动机器学习中的一个重要的研究主题。自动化特征生成中最流行的框架是扩展和缩减,首先扩展生成大量候选特征,然后消除冗余特征。在实践中存在两个挑战:
-
在许多工业应用中,候选特征的数量通常是巨大的,计算所有候选特征不仅计算昂贵,而且由于需要大量存储器而不可行。 -
第二个挑战是如何高效准确地估计新功能的增量性能,即一个新的候选特性有多大的性能改进。大多数现有方法依赖于统计检验来确定是否应纳入新功能。然而,统计学显著性特征并不总是转化为良好的预测因素,仅对于群体中的一小组实例,特征可能与目标显著相关,从而导致群体中的预测较差。即使新特征与目标显著相关,该新特征的有效性也可以已被基本特征集合所包含。
三 本文贡献
本文提出了一种功能强大的特征自动生成算法OpenFE,它能有效地生成有用的特征,提高模型学习性能。OpenFE针对重要特征与好的预测器之间的差距,提出了一种特征提升方法,直接估计基本特征集之外的新特征的预测能力。由于相对于大量候选特征有效特征通常是稀疏的,OpenFE使用了一个两阶段的特征评估框架。在第一阶段,OpenFE通过一个连续的特征剪枝算法,动态地分配计算资源到有希望的特征上来快速地去除冗余的候选特征;在第二阶段, OpenFE使用了一种特征重要性归因方法, 根据其对学习性能改善的贡献对剩余的候选特征进行排序,进一步去除冗余的候选特征。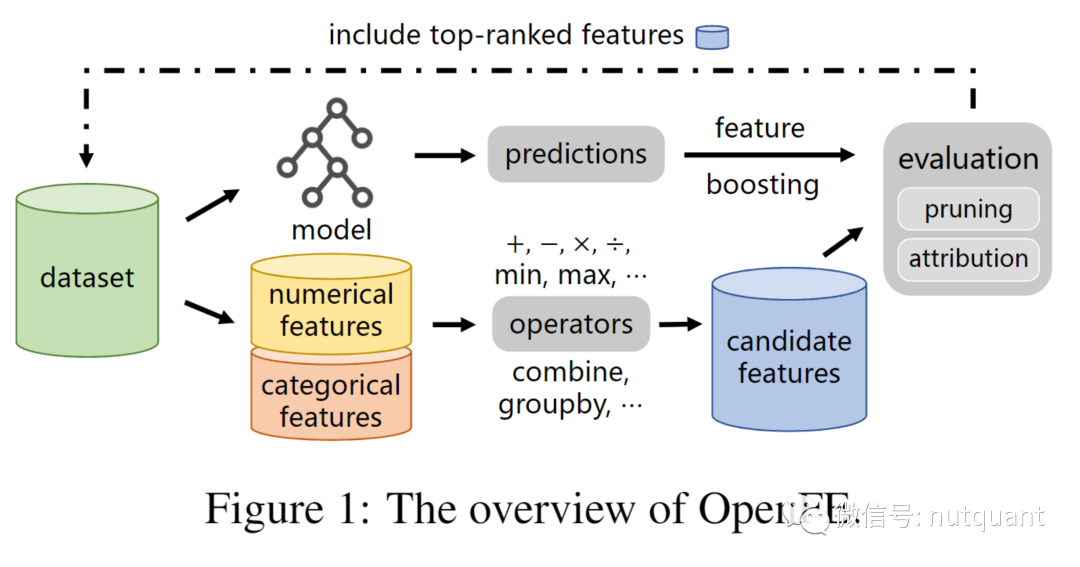

四 本文方法
特征生成任务定义
对于给定的训练数据集D,将其分为子训练集和验证集。假设D由一个特征集T+S组成,其中T是基本特征集,S是生成的特征集,使用学习算法L来学习模型(,),并在验证集上评估模型性能,较大的值表示更好的性能。特征生成问题正式定义如下: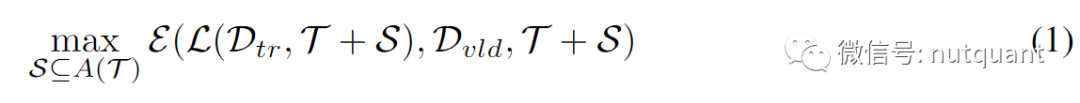
其中()是从基本特征集生成的所有可能候选特征的集合。特征生成的目标是从()中找到最大化评估度量的特征集S。通过用于变换基本特征的算子集来确定A(T),算子集包括一元运算符,如log、sigmoid、square和二进制运算符,如×、÷、min、max、GroupBy等。
图1中展示了OpenFE的基本架构。OpenFE框架包括特征自动扩展和自动缩减两部分。
扩展部分:首先将所有基本特征分类为数字特征和分类特征,然后通过使用运算符枚举基本特征的所有一阶变换来创建候选特征池,其中每个变换使用一个运算符。
缩减部分:自动匹配特征生成的挑战通常在于扩展后的重新生成,即如何高效消除冗余候选特征。OpenFE使用了一个两阶段评估框架以快速减少候选特征的数量。最后在基本特征集中包括排名靠前的候选特征。通过采用贪婪的方法,并重复上述步骤生成高阶特征。
算法1展示了OpenFE的伪代码实现,输入数据集,基本特征集和算子集,输出生成的特征集合。
上述过程中存在两个关键挑战:
-
第一个挑战是准确地估计新特征的增量性能,即新特性添加到基本特性集后可以提供多大的性能改进。标准的评估过程是包括将新特征包含在基本特征集中、重新训练机器学习模型以及观察验证Loss的变化,但是这种方法不仅慢,还需要耗费大量计算资源。 -
第二个挑战是如何利用有限的资源计算和评估大量候选特征。因为候选特征集合可能是巨大的,但是有效的特征是稀疏的,对每个特征进行完整的效果评估会带来大量的时间资源和计算资源开销。
针对第一个挑战,OpenFE提出了类似gradient boosting的feature boosting方法进行解决。当衡量每一个候选特征的效果的时候,不重新训练模型,而是用类似gradient boosting的方式来快速衡量候选特征的增量贡献。以GBDT算法为例,先用已有的特征集训练一个GBDT模型,得到一个预测和预测的效果 。对于一个新的特征, 把作为GBDT的初始预测,用新特征进行模型训练,得到另一个预测和预测效果,预测效果上的提升可以看作新特征带来的增量效果。使用这种方法不需要重新在所有特征上训练模型,只需要在一部分新特征上训练模型,速度非常快,训练的模型效果也接近重新训练的效果。
针对第二个挑战,OpenFE使用了一个两阶段的特征筛选结构来降低资源开销。第一个阶段的目标是快速粗筛,快速地去掉显然没有效果的新特征,第一阶段筛选用到了multi-armed bandit里面的successive halving算法,把数据集分为多个数据块,一开始只用一个数据块来计算和评估所有新特征,通过评估结果去掉后一半的新特征(halving),把用到的数据块×2,然后重复这个步骤。由于这个阶段的目标是粗筛,因子只利用了feature boosting的方式衡量了单个新特征自身的增量效果,没有考虑特征之间交互带来的影响。第二阶段的精筛进一步考虑了特征之间交互的影响,把第一阶段里剩下的候选特征和已有的特征拼在一起,通过feature boosting的方式训练一个新模型,然后通过feature importance attribution的方式来看看每个新特征对于模型loss下降的贡献程度的大小,通过这个贡献程度对于候选特征排序,最后把排序靠前的候选特征加入我们的特征集合。
算法2和算法3是两阶段的特征筛选结构的伪代码实现。

五 实验分析
数据集
实验部分使用了七个公共数据集,包括两个回归数据集、三个二元分类数据集和两个多类分类数据集。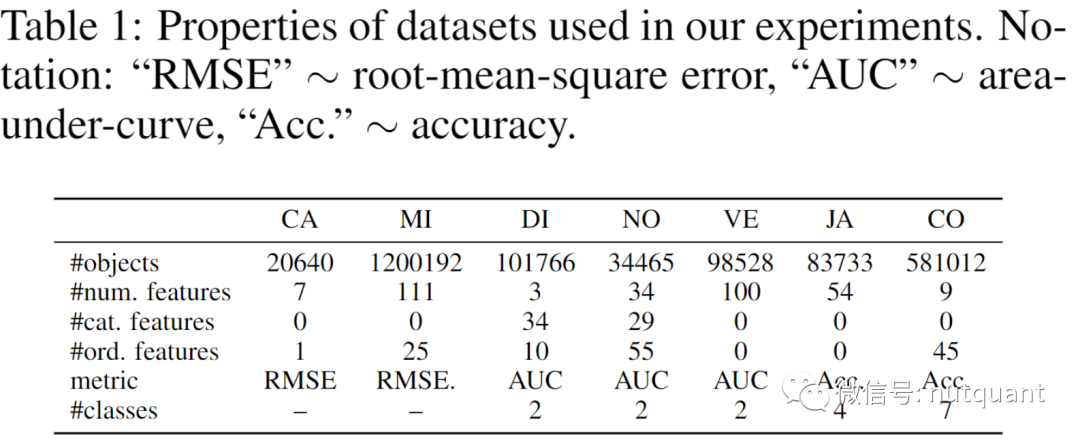
基线方法
比较的基线方法包括:Base(无特征生成的基本特征集)、FCTree、SAFE、AutoFeature、Au-toCross,DCV-V2 NN。大多数自动化特征工程方法都没有开源代码, 本文作者根据论文描述复现了部分方法。
实验结果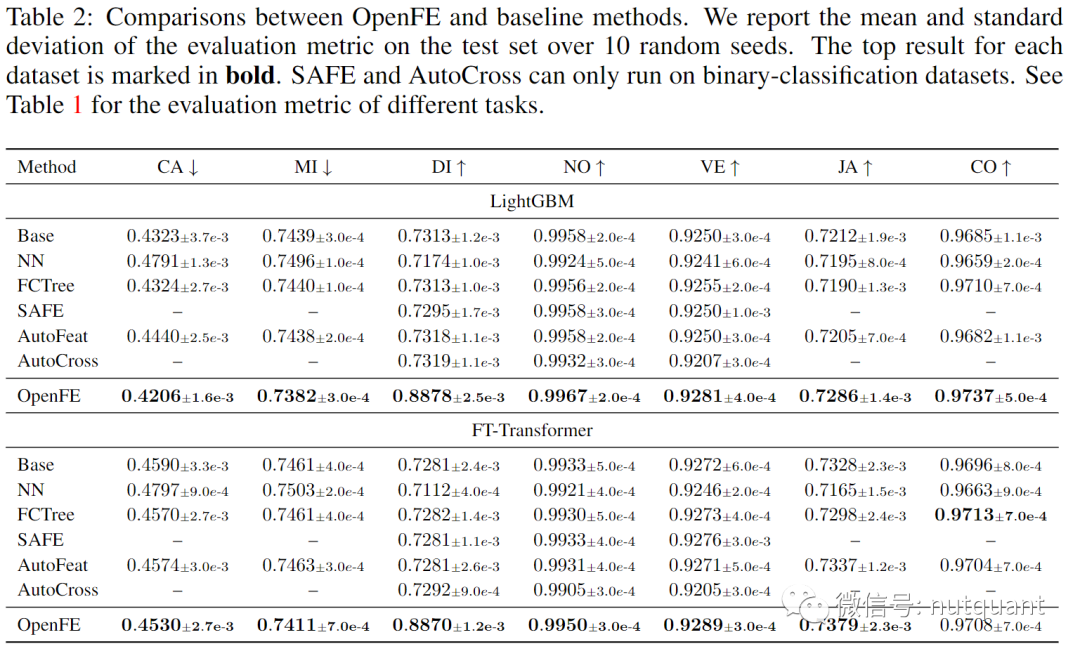
上面的表2展示了OpenFE和基线方法之间的比较。实验使用了10个随机种子在测试集的评估度量的平均值和标准差。论文使用两种标准的学习算法来评估不同方法生成的新特征的有效性。对于GBDT使用了LightGBM实现。对于神经网络,选择FT-Transformer实现。可以从结果中可以看到,OpenFE方法的表现非常优秀。在近乎所有任务上都取得了最优效果。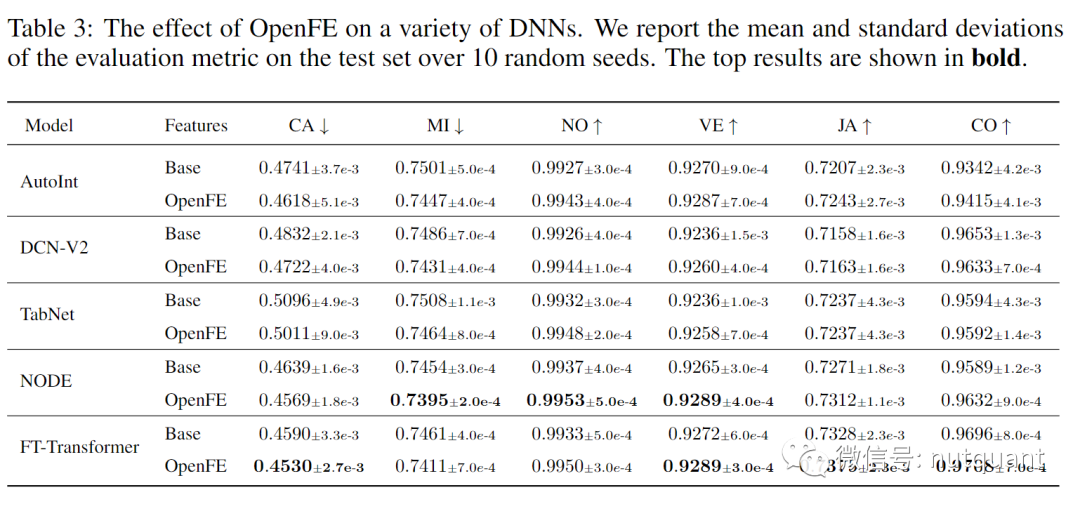
表3展示了OpenFE对各种DNN模型。OpenFE生成的特征在大多数情况可以下大大增强不同模型的性能。即使对于能够学习特征交互的AutoInt和DCN-V2模型,生成的特征也可以进一步提高模型性能。尽管OpenFE依靠GBDT来衡量新特性的性能,但生成的特性对各种DNN方法也是有效的。
表4展示了两项Kaggle竞赛的结果,第一个Kaggle竞赛是IEEE-CIS欺诈检测,其目标是预测在线交易是否欺诈。这场比赛是Kag-gle上规模最大、竞争最激烈的表格数据比赛之一,共有6351支数据科学团队参加。比赛的第一名团队公开了他们在比赛结束后生成的功能,我们称之为expert。这场比赛严重依赖于特征生成,在私人排行榜上6351支队伍中,XGBoost的基线模型没有功能生成,排名为2286,使用expert团队生成特征的基线模型排名为76/6351,而使用OpenFE生成特征的基线模型排名为42/6351,这表明OpenFE生成的特征优于expert团队生成的特征。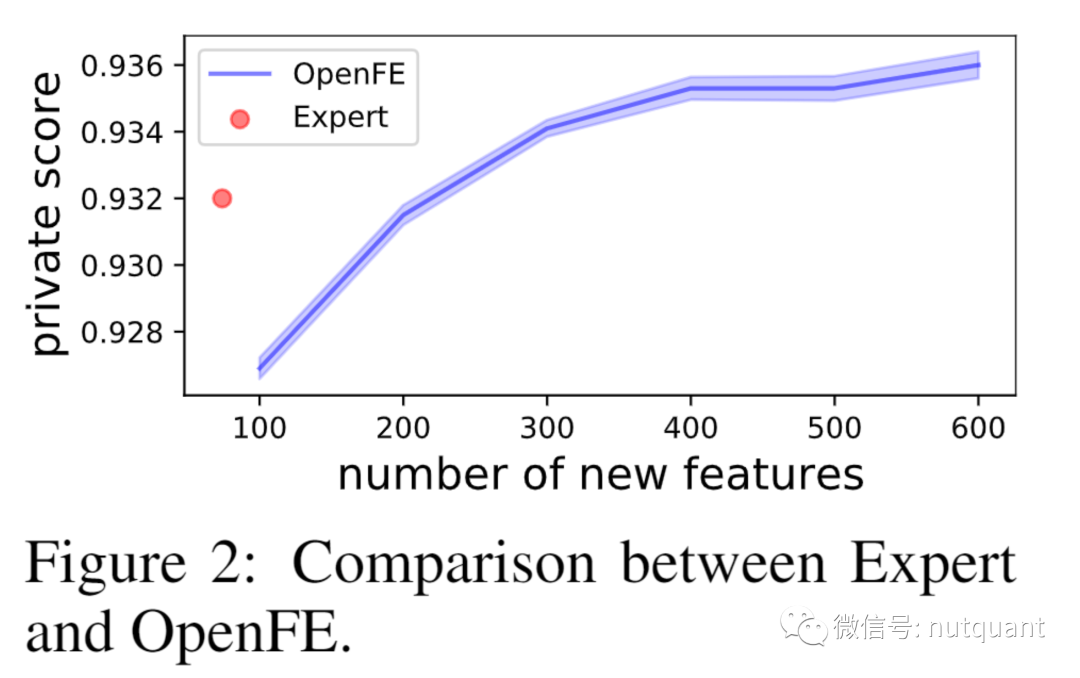
图2展对比了特征数量对模型效果的影响。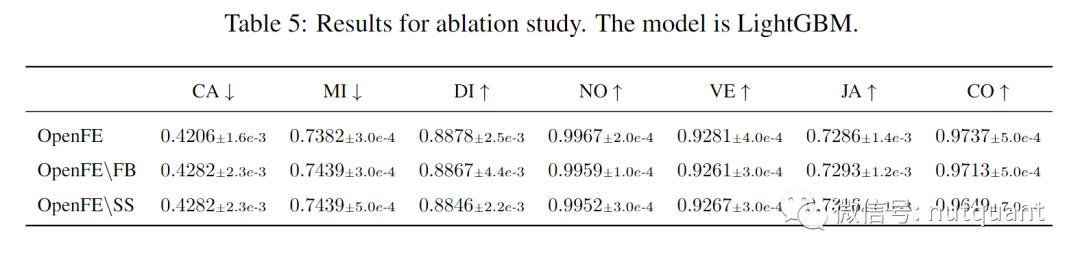
表5进行了消融实验,实验结果表明:1)特征增强显著提高了结果。2) 直接对数据进行二次采样通常会影响性能。
六 总结展望
OpenFE是一个功能强大的自动特征生成工具,能够有效地生成有用的特征,提高表格数据的学习性能。大量实验表明,OpenFE在7个基准数据集上实现了SOTA,在特征生成方面与人类专家具有竞争力。OpenFE不仅提供了一个开源高效的自动特征生成工具,也提供了一套研究基线,可以促使自动特征生成方法的研究。
后续研究展望:
-
当前的算子集是最常用的一些计算,可以结合领域进行扩展增加,以获得更好的效果,例如扩展到时序数据的任务上; -
虽然OpenFE已经通过多种方法降低计算资源的需求,但是计算资源的需求是和数据量和基础特征数量成正比关系的,仍然存在计算资源不足的情况(笔者在100个基础特征的数据集上实验出现了内存不足的问题),可以考虑进一步进行优化,通过牺牲时间或性能来避免类似的问题; -
OpenFE中的特征筛选方法可以独立扩展出来用于进行基础特征挑选。例如: 在股票特征集ALPHA 360上进行有效特征筛选,减少冗余特征,避免模型过拟合。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111082
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!