
一 本文概要
在本文中,我们使用LGBMRanker算法对沪深300、中证500和中证1000的成份股进行排序学习。我们构建了基于价量数据的选股模型,并进行了回测。回测结果显示,从2015年11月至2023年8月底,该策略的累计绝对收益率为167.31%,超过了等权基准的累计超额收益率为160.16%。年化收益率为13.28%,超额年化收益率为12.40%。
二 排序算法介绍
排序学习(Learning to Rank,LTR)是一种机器学习方法,用于解决排序问题。它主要关注的是多个对象之间的相对排序关系,而不是单个对象的分类或回归问题。排序学习通过在数据集上进行机器学习算法的训练,构建出排序模型。这个模型可以根据数据的相关性、重要性等衡量指标对数据进行排序,以满足用户的需求。
与传统的分类和回归模型相比,排序学习有一些显著的不同之处。首先,排序学习关注的是多个对象之间的相对排序关系,而不是单个对象的分类或回归问题。其次,由于排序学习需要处理多个对象的排序信息,所以排序学习模型通常更加复杂,需要考虑对象之间的交互信息和排序关系。在排序学习中,训练集以(q,D)的形式输入模型,其中 q 是查询,D 是一组文档。对于每个查询 q,我们使用这些文档作为模型的参数,并让模型对它们进行排序。然后,通过比较真实排序和预测排序的结果,衡量排序效果,并通过优化迭代来提升排序效果。与传统的分类和回归任务不同,排序学习使用的评估指标也不同。在排序学习中,常用的评估指标包括归一化折损累积增益(Normalized Discounted Cumulative Gain,NDCG)。NDCG 用于衡量模型在对象排序上的性能,它考虑了排序的相关性和位置信息。
RankNet和LambdaRank是两个经典的排序学习算法,它们都基于神经网络,并用于解决排序问题。
RankNet
RankNet是由Microsoft Research开发的一种排序学习算法。它使用神经网络来建模排序模型,并通过比较样本对的相对排序关系来进行训练。
在RankNet中,算法的输入是一对样本(比如两个文档),神经网络通过前向传播计算出每个样本的预测排序概率。这些概率可以表示为样本被认为是更相关的概率。然后,RankNet使用交叉熵损失函数来度量预测排序和真实排序之间的差异。训练过程中,RankNet通过不断迭代更新神经网络的参数,使得预测排序与真实排序之间的差异最小化。通过这种方式,RankNet可以学习到样本之间的排序关系,并输出一个用于排序的模型。
LambdaRank
LambdaRank是由Microsoft Research提出的一种优化排序模型的算法。它在RankNet的基础上引入了Lambda值的概念,进一步优化排序效果。
在LambdaRank中,Lambda值用于表示两个样本的相对重要性,它是根据真实排序和预测排序之间的差异计算得出的。Lambda值的计算可以通过比较交叉熵损失函数的梯度来实现。训练过程中,LambdaRank首先计算每对样本之间的梯度和Lambda值,然后使用这些值来调整梯度的权重,以便模型更好地学习样本之间的排序关系。通过不断迭代优化,LambdaRank可以提升排序模型的性能。
三 排序学习选股模型
3.1 LGBMRanker介绍
LGBM(LightGBM)是一种机器学习算法,它是一种高效的梯度提升决策树(Gradient Boosting Decision Tree, GBDT)算法。由Microsoft团队于2016年提出并开源。LGBM在数据科学和机器学习领域广泛应用,因为它具有出色的性能和高效的训练速度。LGBM采用了多种优化技术来提升模型性能并降低过拟合的风险。其中包括基于Histogram的决策树算法、基于梯度的单侧采样(GOSS)和排他性特征捆绑等。这些技术使得LGBM在训练过程中具有高度的并行性和低内存消耗。
LGBMRanker是基于LGBM的一种排序学习模型,专门用于处理排序学习任务。它在LGBM模型的基础上进行了扩展和定制,增加了排序相关的损失函数和评估指标,以更好地满足排序学习任务的需求。
3.2 选股模型介绍
在选股模型设计中,股票池的构建选择了沪深300、中证500和中证1000的历史成份股作为备选股票池,以保证样本的稳定性和流动性。特征选择方面,选取了价量数据作为模型特征的主要组成部分,并使用不同的算子进行特征工程,如滚动求和、滚动求差分、滚动求分位数等。标签选择方面,根据个股未来一个月的月度涨跌幅,将涨跌幅从高到低分为30组,数字越大表示涨跌幅越高,个股表现越好。这样的标签设计可以帮助模型更好地理解样本之间的相对排序关系。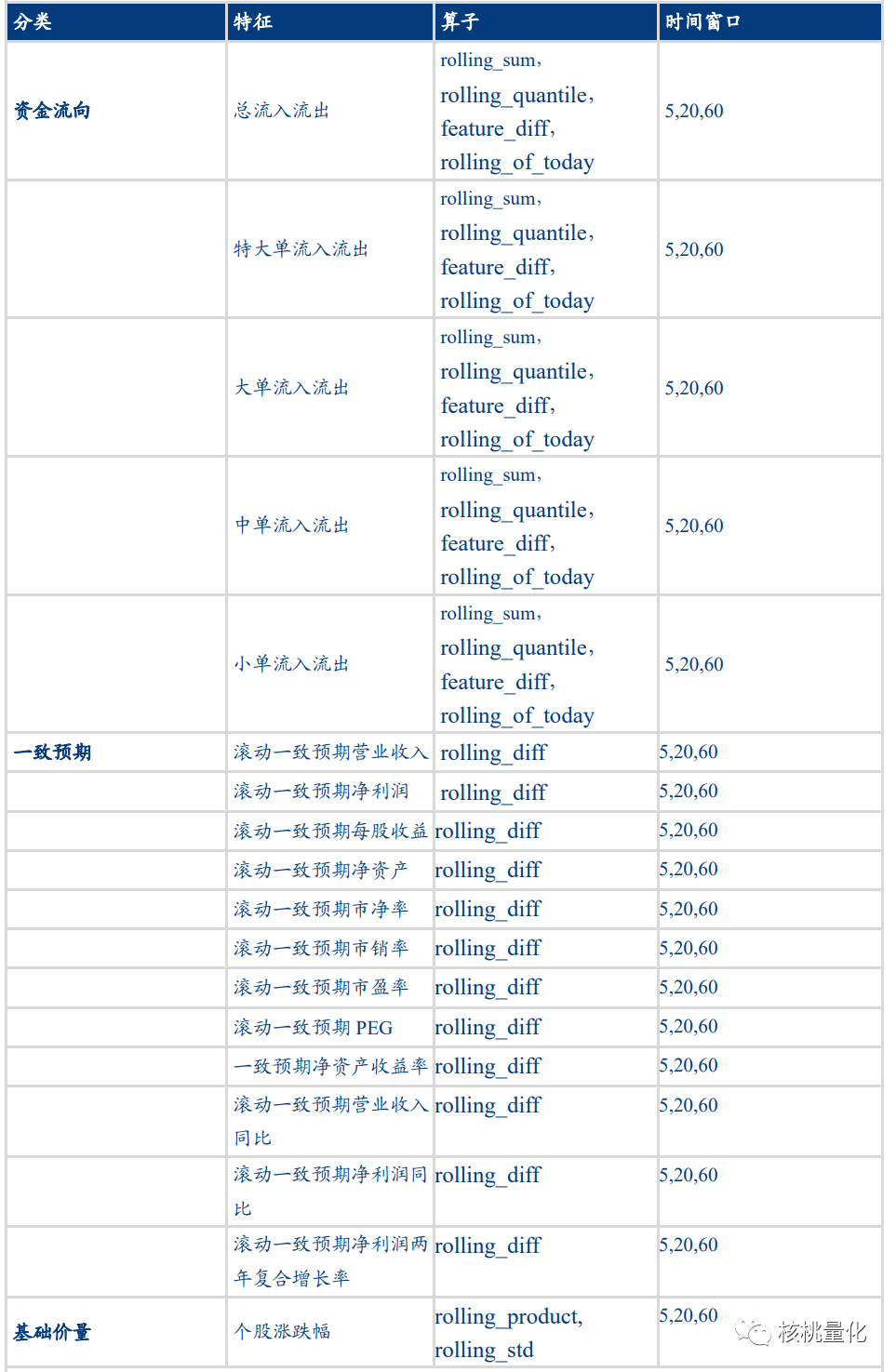
训练方法采用滚动训练法,动态地调整模型的超参数。在每个时点,使用过去12个月的数据作为训练集,将最近3个月的数据作为验证集,找到当前时点下的最优超参数。然后基于最优超参数对未来时点进行预测,并在下一个时点重新计算最优超参数。这种滚动训练法可以根据市场情况和模型性能动态地调整超参数,以保证模型在不同时期的时效性和有效性。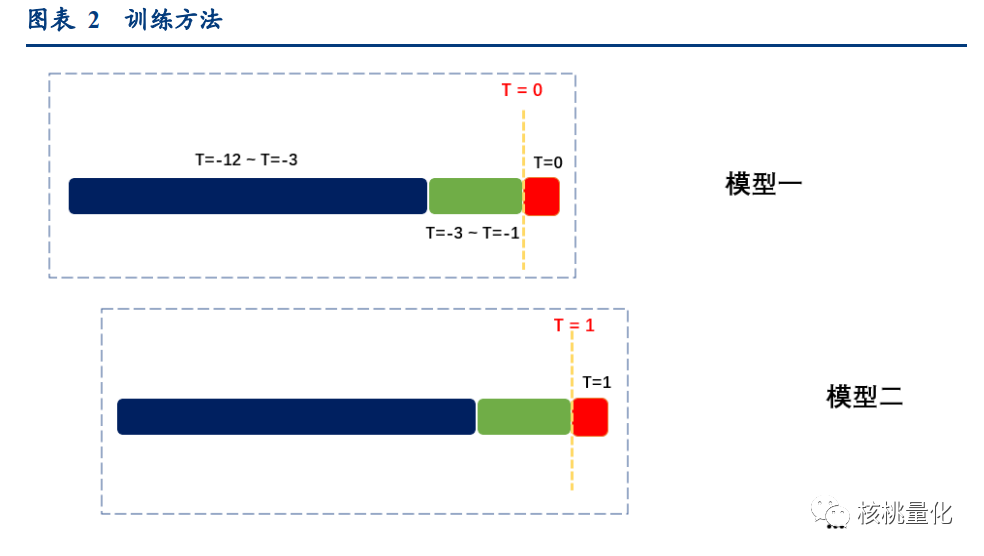
3.3 模型回测
根据上述的模型设计方法,我们可以将每月得到的个股信号进行筛选,选取前50个股票构建投资组合,并进行回测。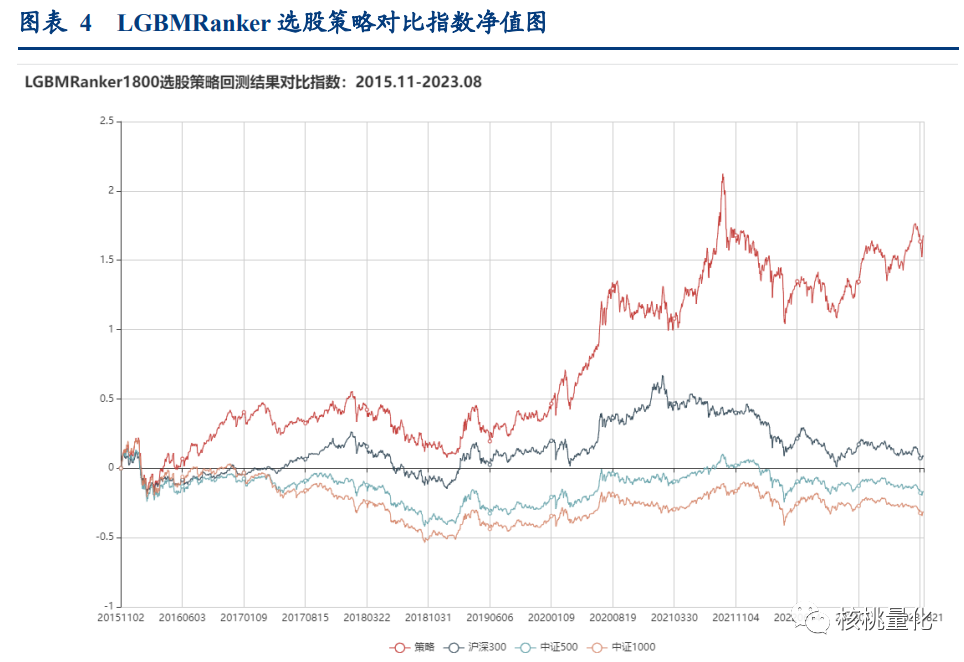


四 总结展望
通过本文中的排序学习策略回测结果,我们可以看到基于LGBMRanker算法的选股模型在沪深300、中证500和中证1000的成份股上取得了良好的表现。策略在过去的回测期间展现出了较高的累计绝对收益率、年化收益率和超额收益率,以及相对较低的最大回撤。胜率方面,策略在多个比较对象中显示出了出色的年胜率和月胜率。
排序学习在量化投资中展示出了巨大的潜力,这一方法能够帮助投资者更好地理解和利用大量的市场数据,从而做出更明智的投资决策。未来的研究和实践将进一步推动排序学习的发展,为投资者提供更多有效的工具和方法来获取稳定的投资回报。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111012
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!


![[通达信指标]搜藏的一款价量关系公式](https://95sca.cn/2024/08/07/GSFy1ICVL6k64Aw1722996537.0879686.jpg?imageMogr2/thumbnail/!480x300r|imageMogr2/gravity/center/crop/480x300)


