
介绍
数据集
import pandas as pdimport numpy as npimport reimport matplotlib.pyplot as plt
toxic_comments = pd.read_csv("/comments.csv")
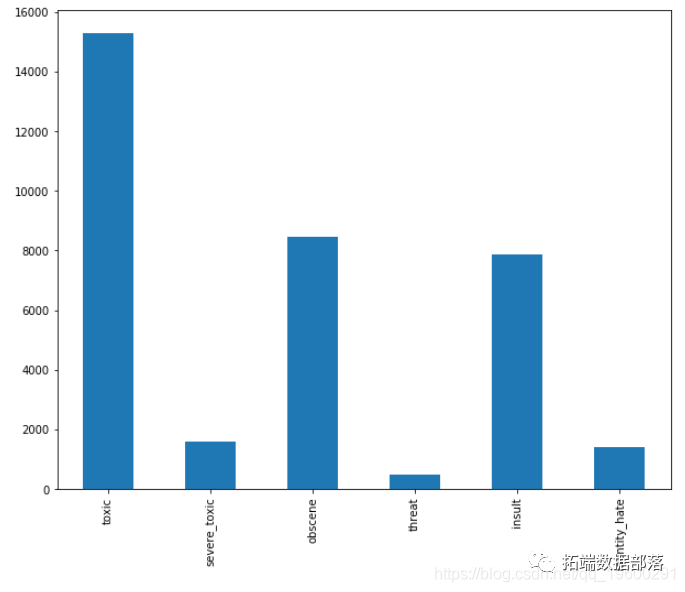
print(toxic_comments.shape)toxic_comments.head()
(159571,8)

filter = toxic_comments["comment_text"] != ""
toxic_comments = toxic_comments[filter]toxic_comments = toxic_comments.dropna()
print(toxic_comments["comment_text"][168])
You should be fired, you're a moronic wimp who is too lazy to do research. It makes me sick that people like you exist in this world.
print("Toxic:" + str(toxic_comments["toxic"][168]))print("Severe_toxic:" + str(toxic_comments["severe_toxic"][168]))print("Obscene:" + str(toxic_comments["obscene"][168]))print("Threat:" + str(toxic_comments["threat"][168]))print("Insult:" + str(toxic_comments["insult"][168]))print("Identity_hate:" + str(toxic_comments["identity_hate"][168]))
Toxic:1
Severe_toxic:0
Obscene:0
Threat:0
Insult:1
Identity_hate:0
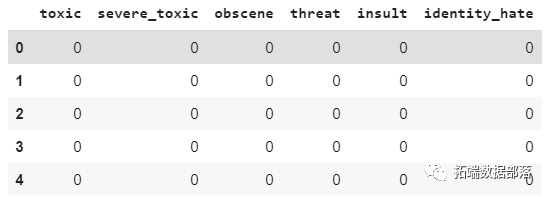
toxic_comments_labels = toxic_comments[["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]]toxic_comments_labels.head()
创建多标签文本分类模型
这里我们不需要执行任何一键编码,因为我们的输出标签已经是一键编码矢量的形式。
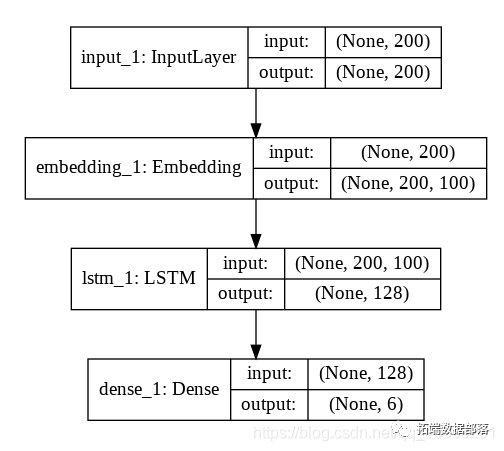
LSTM_Layer_1 = LSTM(128)(embedding_layer)dense_layer_1 = Dense(6, activation='sigmoid')(LSTM_Layer_1)model = Model()
print(model.summary())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 200) 0_________________________________________________________________
embedding_1 (Embedding) (None, 200, 100) 14824300_________________________________________________________________
lstm_1 (LSTM) (None, 128) 117248_________________________________________________________________
dense_1 (Dense) (None, 6) 774
=================================================================Total params: 14,942,322Trainable params: 118,022Non-trainable params: 14,824,300
plot_model(model, to_file='model_plot4a.png', show_shapes=True, show_layer_names=True)
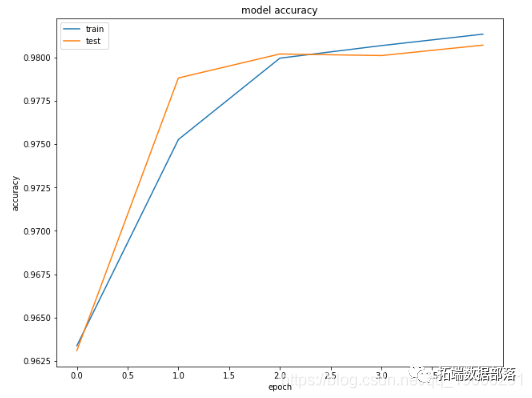
可以用更多的时间训练模型,看看结果是好是坏。
rain on 102124 samples, validate on 25532 samples
Epoch 1/5
[==============================] - 245s 2ms/step - loss: 0.1437 - acc: 0.9634 - val_loss: 0.1361 - val_acc: 0.9631
Epoch 2/5
[==============================] - 245s 2ms/step - loss: 0.0763 - acc: 0.9753 - val_loss: 0.0621 - val_acc: 0.9788
Epoch 3/5
[==============================] - 243s 2ms/step - loss: 0.0588 - acc: 0.9800 - val_loss: 0.0578 - val_acc: 0.9802
Epoch 4/5
[==============================] - 246s 2ms/step - loss: 0.0559 - acc: 0.9807 - val_loss: 0.0571 - val_acc: 0.9801
Epoch 5/5
[==============================] - 245s 2ms/step - loss: 0.0528 - acc: 0.9813 - val_loss: 0.0554 - val_acc: 0.9807
print("Test Score:", score[0])print("Test Accuracy:", score[1])
[==============================] - 108s 3ms/step
Test Score: 0.054090796736467786
Test Accuracy: 0.9810642735274182
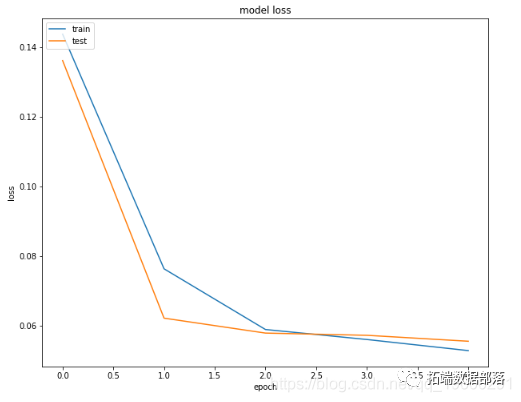
plt.title('model loss')plt.ylabel('loss')plt.xlabel('epoch')plt.legend(['train','test'], loc='upper left')plt.show()
def preprocess_text(sen):
# 删除标点符号和数字
# 单字符删除
# 删除多个空格
sentence = re.sub(r'\s+', ' ', sentence)return sentence
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
X_train = pad_sequences(X_train, padding='post', maxlen=maxlen)X_test = pad_sequences(X_test, padding='post', maxlen=maxlen)
embedding_matrix = zeros((vocab_size, 100))
print(model.summary())
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 200) 0
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 200, 100) 14824300 input_1[0][0]
__________________________________________________________________________________________________
lstm_1 (LSTM) (None, 128) 117248 embedding_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1) 129 lstm_1[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 129 lstm_1[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 1) 129 lstm_1[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 1) 129 lstm_1[0][0]
__________________________________________________________________________________________________
dense_5 (Dense) (None, 1) 129 lstm_1[0][0]
__________________________________________________________________________________________________
dense_6 (Dense) (None, 1) 129 lstm_1[0][0]
==================================================================================================
Total params: 14,942,322
Trainable params: 118,022
Non-trainable params: 14,824,300
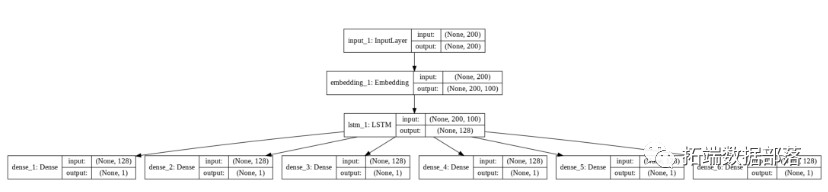
plot_model(model, to_file='model_plot4b.png', show_shapes=True, show_layer_names=True)
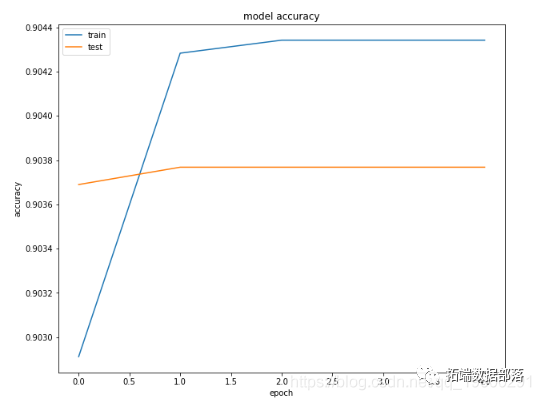
history = model.fit(x=X_train, y=[y1_train, y2_train, y3_train, y4_train, y5_train, y6_train], batch_size=8192, epochs=5, verbose=1, validation_split=0.2)
Train on 102124 samples, validate on 25532 samples
Epoch 1/5
[==============================] - 24s 239us/step - loss: 3.5116 - dense_1_loss: 0.6017 - dense_2_loss: 0.5806 - dense_3_loss: 0.6150 - dense_4_loss: 0.5585 - dense_5_loss: 0.5828 - dense_6_loss: 0.5730 - dense_1_acc: 0.9029 - dense_2_acc: 0.9842 - dense_3_acc: 0.9444 - dense_4_acc: 0.9934 - dense_5_acc: 0.9508 - dense_6_acc: 0.9870 - val_loss: 1.0369 - val_dense_1_loss: 0.3290 - val_dense_2_loss: 0.0983 - val_dense_3_loss: 0.2571 - val_dense_4_loss: 0.0595 - val_dense_5_loss: 0.1972 - val_dense_6_loss: 0.0959 - val_dense_1_acc: 0.9037 - val_dense_2_acc: 0.9901 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9966 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9901
Epoch 2/5
[==============================] - 20s 197us/step - loss: 0.9084 - dense_1_loss: 0.3324 - dense_2_loss: 0.0679 - dense_3_loss: 0.2172 - dense_4_loss: 0.0338 - dense_5_loss: 0.1983 - dense_6_loss: 0.0589 - dense_1_acc: 0.9043 - dense_2_acc: 0.9899 - dense_3_acc: 0.9474 - dense_4_acc: 0.9968 - dense_5_acc: 0.9510 - dense_6_acc: 0.9915 - val_loss: 0.8616 - val_dense_1_loss: 0.3164 - val_dense_2_loss: 0.0555 - val_dense_3_loss: 0.2127 - val_dense_4_loss: 0.0235 - val_dense_5_loss: 0.1981 - val_dense_6_loss: 0.0554 - val_dense_1_acc: 0.9038 - val_dense_2_acc: 0.9900 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9965 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9900
Epoch 3/5
[==============================] - 20s 199us/step - loss: 0.8513 - dense_1_loss: 0.3179 - dense_2_loss: 0.0566 - dense_3_loss: 0.2103 - dense_4_loss: 0.0216 - dense_5_loss: 0.1960 - dense_6_loss: 0.0490 - dense_1_acc: 0.9043 - dense_2_acc: 0.9899 - dense_3_acc: 0.9474 - dense_4_acc: 0.9968 - dense_5_acc: 0.9510 - dense_6_acc: 0.9915 - val_loss: 0.8552 - val_dense_1_loss: 0.3158 - val_dense_2_loss: 0.0566 - val_dense_3_loss: 0.2074 - val_dense_4_loss: 0.0225 - val_dense_5_loss: 0.1960 - val_dense_6_loss: 0.0568 - val_dense_1_acc: 0.9038 - val_dense_2_acc: 0.9900 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9965 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9900
Epoch 4/5
[==============================] - 20s 198us/step - loss: 0.8442 - dense_1_loss: 0.3153 - dense_2_loss: 0.0570 - dense_3_loss: 0.2061 - dense_4_loss: 0.0213 - dense_5_loss: 0.1952 - dense_6_loss: 0.0493 - dense_1_acc: 0.9043 - dense_2_acc: 0.9899 - dense_3_acc: 0.9474 - dense_4_acc: 0.9968 - dense_5_acc: 0.9510 - dense_6_acc: 0.9915 - val_loss: 0.8527 - val_dense_1_loss: 0.3156 - val_dense_2_loss: 0.0558 - val_dense_3_loss: 0.2074 - val_dense_4_loss: 0.0226 - val_dense_5_loss: 0.1951 - val_dense_6_loss: 0.0561 - val_dense_1_acc: 0.9038 - val_dense_2_acc: 0.9900 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9965 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9900
Epoch 5/5
[==============================] - 20s 197us/step - loss: 0.8410 - dense_1_loss: 0.3146 - dense_2_loss: 0.0561 - dense_3_loss: 0.2055 - dense_4_loss: 0.0213 - dense_5_loss: 0.1948 - dense_6_loss: 0.0486 - dense_1_acc: 0.9043 - dense_2_acc: 0.9899 - dense_3_acc: 0.9474 - dense_4_acc: 0.9968 - dense_5_acc: 0.9510 - dense_6_acc: 0.9915 - val_loss: 0.8501 - val_dense_1_loss: 0.3153 - val_dense_2_loss: 0.0553 - val_dense_3_loss: 0.2069 - val_dense_4_loss: 0.0226 - val_dense_5_loss: 0.1948 - val_dense_6_loss: 0.0553 - val_dense_1_acc: 0.9038 - val_dense_2_acc: 0.9900 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9965 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9900
print("Test Score:", score[0])print("Test Accuracy:", score[1])
[==============================] - 111s 3ms/step
Test Score: 0.8471985269747015
Test Accuracy: 0.31425264998511726
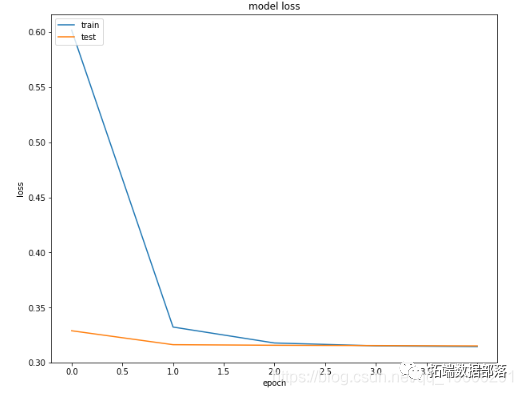
plt.title('model loss')plt.ylabel('loss')plt.xlabel('epoch')plt.legend(['train','test'], loc='upper left')plt.show()
结论
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/109520
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





