
下前面说了,学习投资从指数开始。
指数的数据比较全,不受操控。
我们优先关注几个重点的指数,宽基指数和重要行业指数,把它们的数据导入到qlib的存储中。
我们重点关注几个指数:
class Config:
def get_index_codes(self):
return [
'000300.SH',#沪深300
'000905.SH',#中证500
'399006.SZ', #创业板
'000852.SH', #中证1000
'399324.SZ', #深证红利
'000922.SH', #中证红利
'399997.SZ', #中证白酒
'399396.SZ', #食品饮料
'000013.SH',#上证企债
'000016.SH' #上证50
]
def get_global_index_codes(self):
return [
'HSI',#恒生指数
'SPX',#标普500
'GDAXI',#德国DAX
‘N225’ #日经225
]
使用tushare的代码生成器,直接可以生成如下函数,下载的数据就是dataframe。
def collect_index(code):
# 拉取数据 df = pro.index_daily(**{ "ts_code": code, "trade_date": "", "start_date": "", "end_date": "", "limit": "", "offset": "" }, fields=[ "ts_code", "trade_date", "close", "open", "high", "low", "pre_close", "change", "pct_chg", "vol", "amount" ]) return df
使用qlib的dump_bin导入,这里我们说一种,直接调用类,而不是官方方档里调脚本的方式,而且我已经内置到软件中了。
选择目录,然后引入 dump_bin里的DumpDataAll函数,配置相应的参数。
dlg = wx.DirDialog(self, u"选择要导入csv的文件目录", style=wx.DD_DEFAULT_STYLE) if dlg.ShowModal() == wx.ID_OK: path = dlg.GetPath() # 文件夹路径 from data.dump_bin import DumpDataAll DumpDataAll(csv_path=path, qlib_dir='~/.qlib/qlib_data/index_data', symbol_field_name='ts_code', include_fields=['open', 'high','low','close', 'vol', 'amount'], date_field_name='trade_date').dump() wx.MessageBox('导入完成!', '成功!')
几个核心指数的数据就完成存储了。

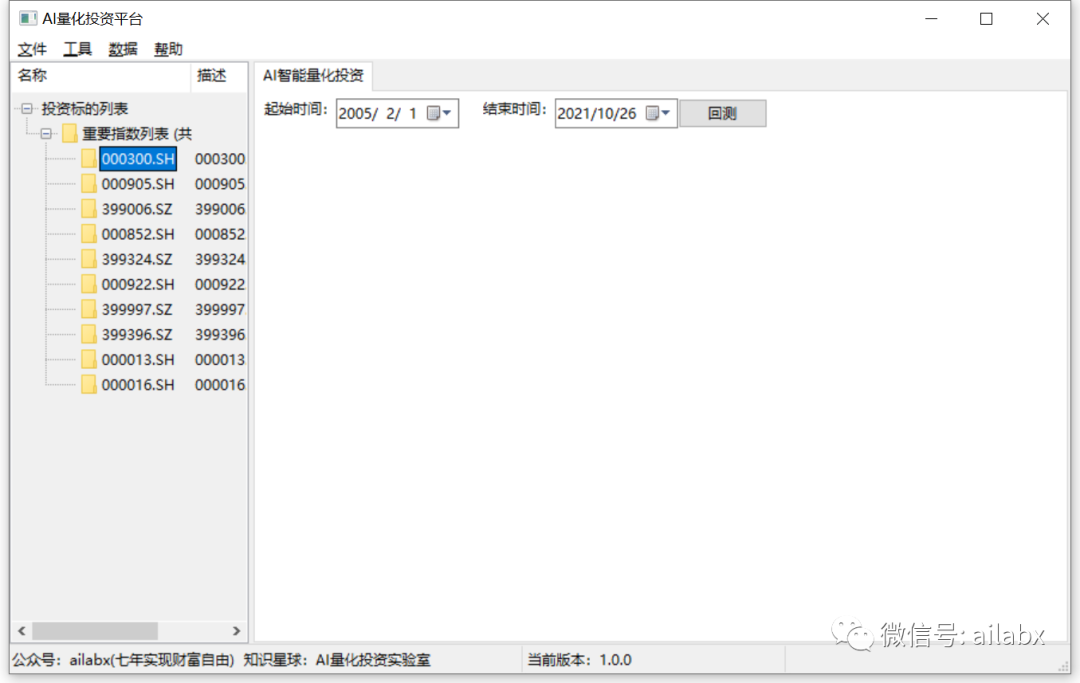
重新规划一下主窗口,分成左右两个部分,
这里需要使用一个组件是wx.SplitterWindow,只能在frame里用,而不能在panel中,这个需要特别注意。
def init_main_win(self): splitter = wx.SplitterWindow(self, -1) self.leftpanel = wx.Panel(splitter) self.rightpanel = wx.Panel(splitter) splitter.SplitVertically(self.leftpanel, self.rightpanel, 100) splitter.SetMinimumPaneSize(200) self.init_left_panel()
self.init_right_panel()
左侧的panel里引入树结构,显示指数列表:
def init_left_panel(self): self.boxH = wx.BoxSizer(wx.VERTICAL) self.leftpanel.SetSizer(self.boxH) from .widgets import AiTreeListCtrl tree = AiTreeListCtrl(self.leftpanel, cols=['名称', '描述'],root_text='指数列表') self.boxH.Add(tree,1,flag=wx.ALL|wx.EXPAND)
生成的界面如下:
准备好了数据,开始我们的量化回测。
使用qib内置的alpha360,即360个因子————对,机器学习与传统量化几条规则不一样,
上来就是几百个因子,计算特征在我的笔记本上足足5分钟。
当然qlib做了很多并行计算,以及中间过程的缓存。
如何发现有效的alpha,配置最有效的因子,这才是关键。
训练的模型是lightGBM。
def _get_model_config(self): model = { "class": "LGBModel", "module_path": "qlib.contrib.model.gbdt", "kwargs": { "loss": "mse", "colsample_bytree": 0.8879, "learning_rate": 0.0421, "subsample": 0.8789, "lambda_l1": 205.6999, "lambda_l2": 580.9768, "max_depth": 8, "num_leaves": 210, "num_threads": 20, } } return model
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104236
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!