
综合大家的意见,结合自己的一些思考,暂定如下:
1、带gui界面的私有化安装、部署的平台。
2、自带数据源,可以更新。etf、转债、A股、指数等。
3、传统规则型量化。
4、大类资产配置的绝对型收益策略。
5、AI模型驱动的多因子策略。
gui使用wxpython、streamlit结合使用。一个好的gui可以让大家写自己的策略,看结果更架方便。
数据源准备是一个比较耗时的工作,这个内置脚本来完成。
传统规则型量化,我们本身就开发了“积木式”开式回测引擎。后面要扩展到集成学习,强化学习等策略。
另外就是大类资产配置的绝对型收益策略。


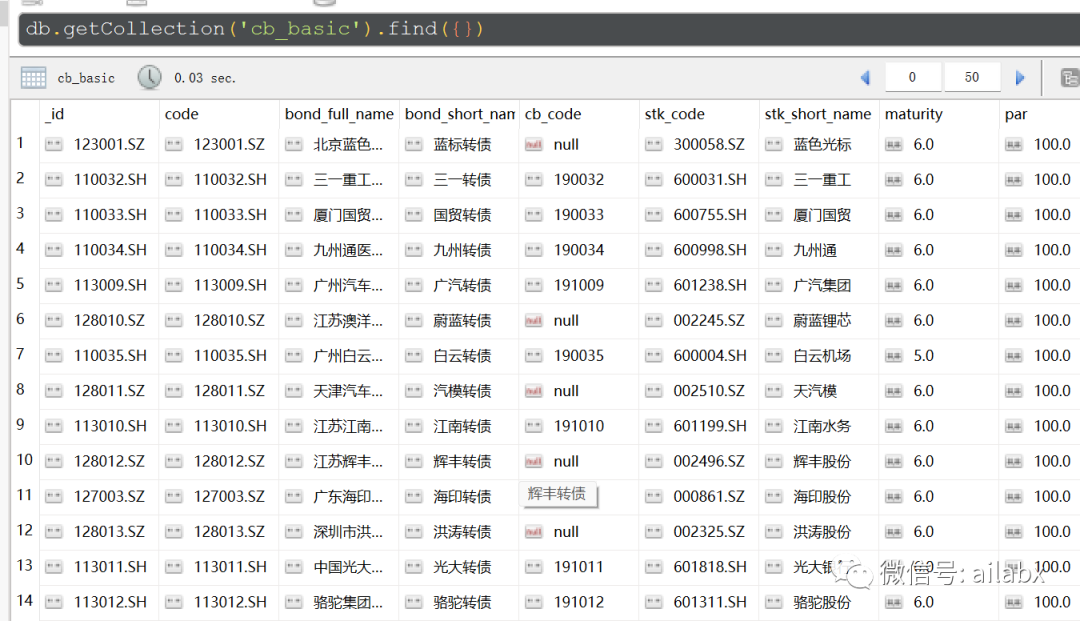
行业ETF情况:
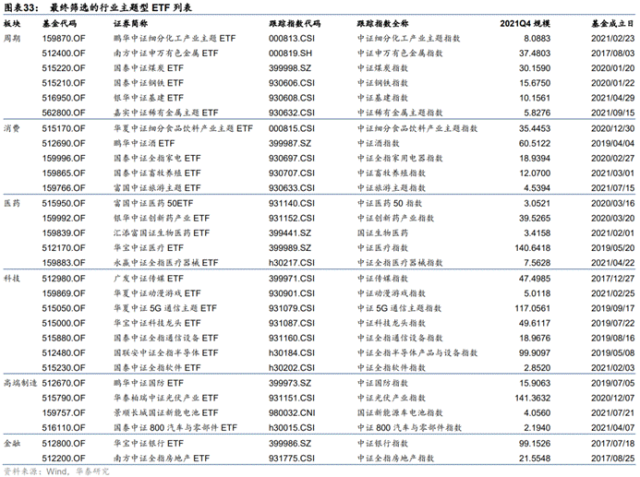
股票、黄金、国债、货币,四大类资产的风险收益情况如下:
股票,年化6%,最大回撤45%;
黄金,年化5%,最大回撤46%;
国债,年化1.7%, 最大回撤4.6%;
货币,年化2.7%,最大回撤0.4%;
货币基金的夏普比是非常高的。
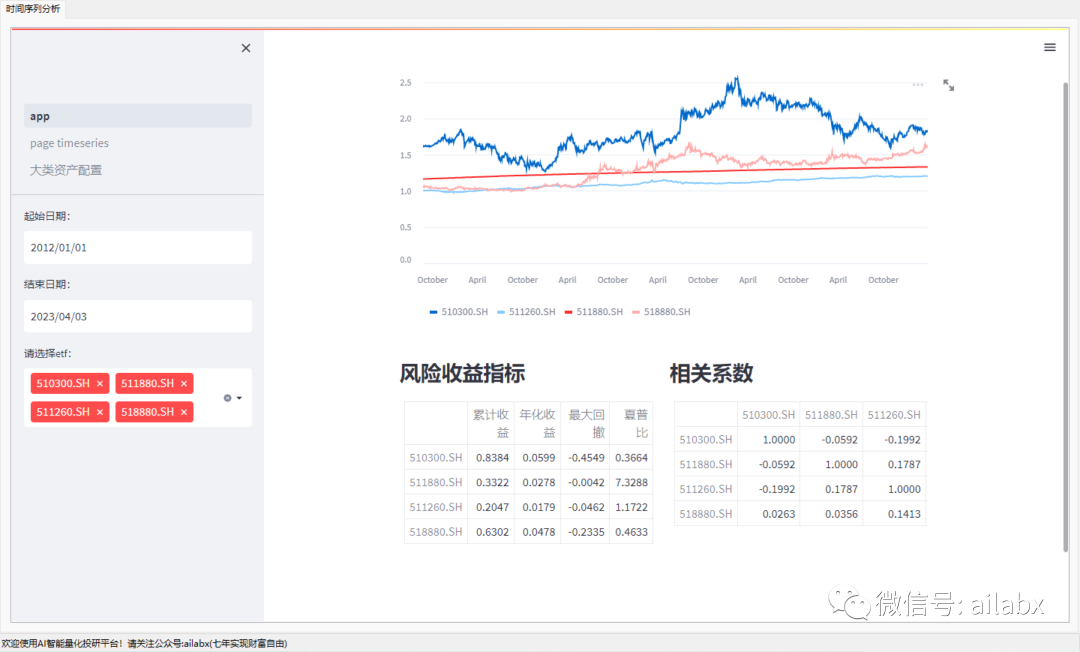
所以的投资,第一步都应该分析标的的风险收益水平,以及它们之间的相关性。
股票与黄金,货币,债券的相关性都小。
四大类之间的相关性都很小,甚至出现负相关。
这对于我们构建“绝对收益型”投资组合很有帮助。
主界面代码:
import wx from gui.mainframe import MainFrame import subprocess # '--server.port', '5002' p_restart = subprocess.Popen(['streamlit', 'run', 'app.py']) if __name__ == '__main__': app = wx.App() frm = MainFrame(None, title='AI量化投研平台') frm.Show() app.MainLoop() p_restart.kill()
分析界面代码:
from datetime import datetime import streamlit as st import pandas as pd from config import DATA_DIR_HDF5_ETF import os def load_etfs(): with pd.HDFStore(DATA_DIR_HDF5_ETF.resolve()) as store: symbols = [k.replace('/', '') for k in store.keys()] return symbols symbols = load_etfs() st.subheader('资产风险、收益分析') date_start = st.sidebar.date_input('起始日期:', datetime(2012, 1, 1)) date_start = date_start.strftime('%Y-%m-%d') date_end = st.sidebar.date_input('结束日期:', datetime.now().date()) date_end = date_end.strftime('%Y-%m-%d') sel = st.sidebar.multiselect(label='请选择etf:', options=symbols, default=symbols[0]) dfs = [] for symbol in sel: with pd.HDFStore(DATA_DIR_HDF5_ETF.resolve()) as s: df = s[symbol] se = df['close'] * df['adj_close'] se.name = symbol dfs.append(se) df_all = pd.concat(dfs, axis=1) df_returns = df_all.pct_change() df_returns = df_returns[df_returns.index >= date_start] df_returns = df_returns[df_returns.index <= date_end] df_equity = (df_returns + 1).cumprod() print(df_equity) df_equity.dropna(inplace=True) st.line_chart(df_equity) col_indicators, col_corr = st.columns(2) col_indicators.subheader('风险收益指标') from engine.data_utils import DataUtils col_indicators.table(DataUtils.calc_indicators(df_returns)) col_corr.subheader('相关系数') col_corr.table(df_returns.corr())
代码及数据请前往 星球 ——专栏下载。
昨天目标倒推法,其实是现代版本的守株待兔。提及B计划,其实是看优势与趋势,C计划看梦想。目前看来优势还真的是AI量化投资,而且这个也符合趋势。那做就是了。
我比较看好多因子的逻辑。
其实我们知道,股市预测比预测地震还难。几乎不可能。那大家在折腾啥呢。不预测也可以。因为资本市场本意就不是让你投机的,只是有人用它来投机罢了,而资本市场利用你的投机来发现价格。
市场是长期向上的,因为把资源配置在对的事情上。所以,就有了大类资产配置,定投长期向上的标的这样的偏被动的投资模式,主要是获得市场的beta。其实加上一些再平衡量,长期年化8-12%是不难的。
当然,这个长期年化,可以会伴随回撤,在熊市会有亏损。大家还是希望加上自己的主动干预。我看好多因子模型。
多因子模型本质也没是预测,而是一个概率思维,这与人生选择有点像。
好比,在一个学校里,你想选出一些年轻人进行投资,投资他们的未来。最直接的,你会“看面相”,直接看出未来20年,某位同学会成功成才。显然,这个非常难。更好的策略是,我找到成绩中等偏上的,身体也中等偏上的,品德中等往上的等等。这就是因子,我们认为好的因子,找到那些对未来有帮助作用的因子。你说一定嘛?不一定,但是在概率上,这样的人成才的可能性更大。
多因子模型有点像smart beta,比beta要高,而且可能回撤更小。但比追求所谓的alpha,你就all in某一个人,那风险会很高,当然如何成了,收益也会更高。
大资金,像风险投资也是这个逻辑,他有自己看项目的标准,但不是预测,只是认为这个创业者,团队有胜率,这个赛道有可能性就可以投,他投一个组合,有一些成功就可以的。这是风投的逻辑。本质还是多因子。
多因子是从全市场层层海选,定期再更新列表,然后持有组合。
全市场的数据比较多,可转债历史上有差不多860支。
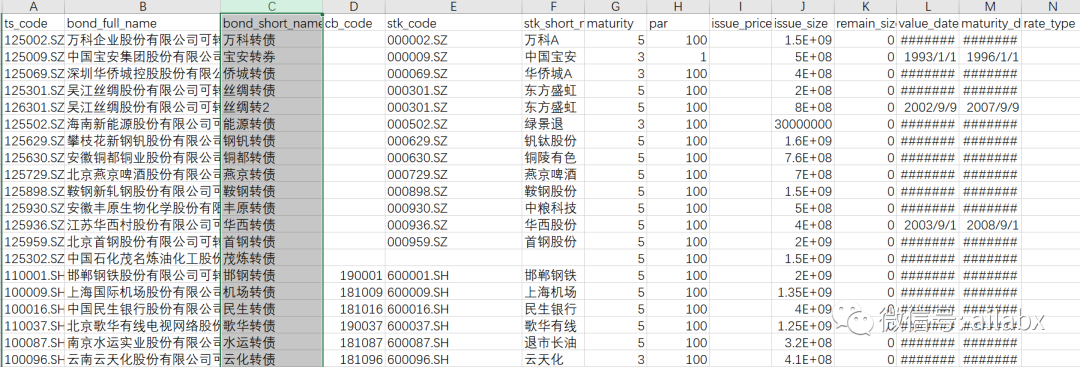
2015年以后上市的转债为760支。
from engine.algo.algos import * e = Engine() print('初始总市值', e.acc.get_total_mv()) e.run(name='可转债-多因子', algo_list=[ RunMonthly(), # 改这行代码即可 SelectTopK(K=20, order_by='double_low', b_ascending=True), WeightEqually() ]) print('最终总市值', e.acc.get_total_mv()) e.show_results(benckmarks=['sh.000832'])
我把引擎改造了一下,数据特征先计算,然后存储在all.h5的all这个key里,对于多因子这样的模型,这样的回测速度是非常快的,不用再计算特征。之前像RSRS指标这样的费时的计算也能得到解决,只计算一次即可。
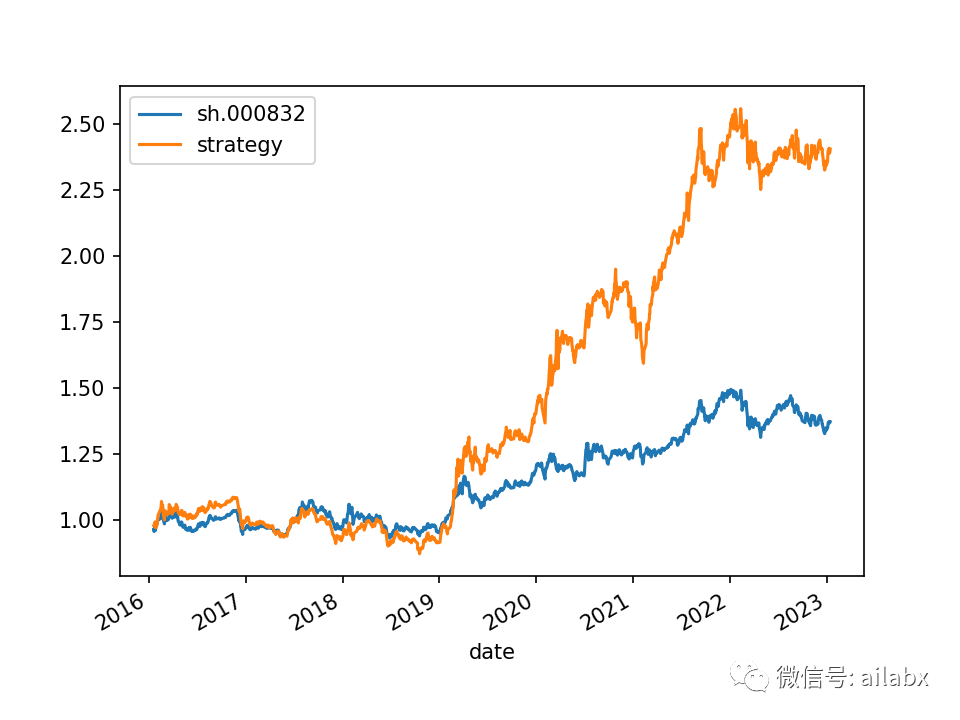
这是最传统的“双低”策略,月度再平衡,选双低值最小的前20支买入。这里没有去除“一年内到期的”。因为久期太短,期权的价值有限。
多因子版本:三个因子:转股溢价,pb分位点,净利润增速
from engine.algo.algos import * e = Engine() print('初始总市值', e.acc.get_total_mv()) e.run(name='可转债-多因子', algo_list=[ RunMonthly(), # 改这行代码即可 SelectTopK_Multi(K=20, factors=['-转股溢价','-pb_pct','dt_netprofit_yoy']), WeightEqually() ]) print('最终总市值', e.acc.get_total_mv()) e.show_results(benckmarks=['sh.000832'])
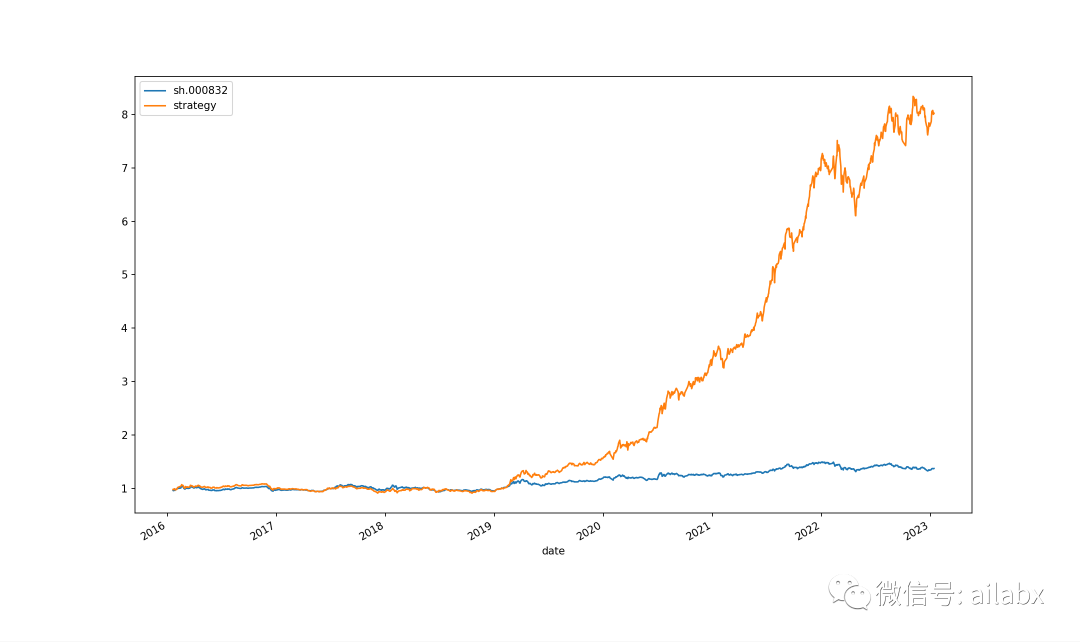
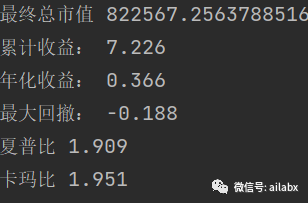
这个模型的方向是对的,且有强劲的逻辑做支撑,后续要准备实盘了!
。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104137
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!