
01 HDF5的子集操作
大家如果熟悉我们之前的思路,知道我们后端使用mongo来存储金融数据。其实很多小私募投资公司就是这么做的。日频的数据,其实用mysql都行,而mongo的门槛最低。
有了mongo为何还需要hdf5?
mongo用于数据持久化,而hdf5用于支撑回测。尤其是针对全市场的海量选股,选基的场景,需要把全市场数据下载到本地,然后再进行因子计算,需要消耗无谓的时间。因此把数据在hdf5里做好预计算,就像机器学习的数据集一样,不需要频繁的更新。可以把因子计算好后,载入内存,以供回测或者模型训练之用。
hdf5单次写入dataframe特别简单,还要解决“增量更新”,“meta信息”两个点。
hdf5是美国超算中心开发的用于存储科学数据的自描述文件格式,与简单的二进制格式文件存储的最大区别是hdf5带有meta数据,这些元数据给出了数据的特征信息。hdf5有广泛的应用,matlab的.mat文件就是以hdf5作为保存文件的默认格式。另外hdf5支持子集分片和部分IO,就是说可以像数据库一样进行查询,返回部分数据,不需要像csv一样,把数据整体读到内存才能访问。
hdf5写入的时间,需要指定format=table,默认是fix,fix只能整体读写,优点是快,而table格式是可以支持查询子集,更加灵活。
df.to_hdf('test.h5', 'test', format='table')
print(df)
sub = pd.read_hdf('test.h5', 'test', where="index>='20190319'")
print(sub)
全市场hdf5的数据集用table格式,可以增量更新,而合成一个all大数据集后,使用fix提升加载速度。
当然从回测的角度而言,日频数据的重建代价也不算特别大,就算每天更新一次,交给定时任务也能很好的完成。
02 基于jquery的table
我们计算好每天的因子指标,需要使用一个表格把它结构化地呈现出来。需要支持按某几个维度进行排序,同时还能支持检索,分页等等。
一个简单的交易如下,这个适合于可转债列表,ETF列表,股票列表,指数列表等等,多因子多维度排序,呈现数据。
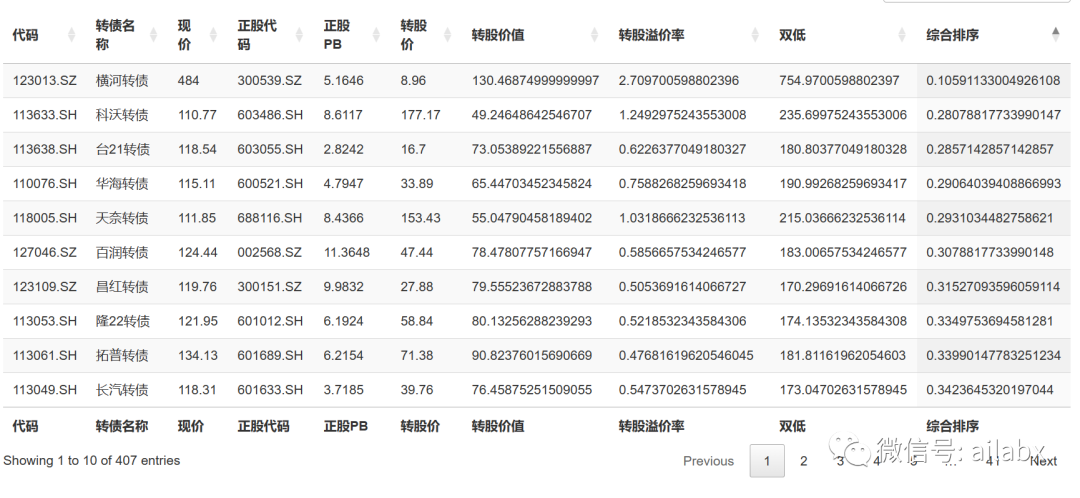

后端代码如下,支持前端ajax请求:
@api.get('bonds') def get_bonds(request): items = mongo_utils.get_db()['bonds_rank'].find({}, {'_id': 0, 'delist_date': 0}).sort('order_by', direction=pymongo.ASCENDING) items = list(items) df = pd.DataFrame(items) df.rename(columns={'pb': '正股PB', 'close': '现价', 'code': '代码', 'chg_price':'转股价', '转股溢价':'转股溢价率', 'double_low':'双低', 'order_by':'综合排序', 'stk_code': '正股代码', 'bond_short_name': '转债名称'}, inplace=True) df = df[['代码', '转债名称', '现价', '正股代码', '正股PB','转股价','转股价值','转股溢价率','双低','综合排序']] data = {} items = df.to_dict(orient='split') datas = [items['columns']] datas.extend(items['data']) data['data'] = datas return data
前端代码如下:
<script src="{% static 'DataTables-1.13.1/js/jquery.dataTables.min.js' %}"></script> <script> $(document).ready(function () { $('#bonds').DataTable({ ajax: '/api/bonds', }); }); </script>
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104163
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!