
AI量化实验室的初心和愿景,我想更新一下:
“用前沿技术,让复杂的金融投资更简单”。
之前特别着急产品化,平台化,后来仔细想来,与咱们初心不符。
我们要跟踪最新的技术,让AI来解决金融投资的问题,这是一个“无止尽”,但“很有意义”的事情。
停留在ETF大类资产配置,或者趋势轮动,当然也很有价值,或者说这是一个“舒适区”。——但是我们还是要继续挑战。
投资没有圣杯,正因为没有圣杯,它才神秘和好玩。
它不像物理学或数字,有清晰的逻辑,有明确的答案等我们去发现,它建构于人性的博弈,宏观,甚至地缘冲突都会影响其表现。
我们从gplearn入手,之前写过不少了。
可以重温下:
gplearn因子挖掘:分钟级数据效果还是非常好的:年化81%,最大回撤10%。(quantlab3.1源代码+数据下载)
未来几年,咱们来系统学习一下:
gplearn的实现参考了sklearn的接口,如果你熟悉sklearn的使用,会感觉 很熟悉。
gplearn有三个接口:分类,回归和变形。
我们来看一个回归的使用例子:
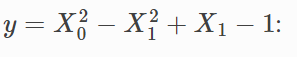

这个函数绘制出来是下面这个样子:
import numpy as np import matplotlib.pyplot as plt from gplearn.genetic import SymbolicRegressor from gplearn.utils import check_random_state from sklearn.ensemble import RandomForestRegressor from sklearn.tree import DecisionTreeRegressor x0 = np.arange(-1, 1, 1/10.) x1 = np.arange(-1, 1, 1/10.) x0, x1 = np.meshgrid(x0, x1) y_truth = x0**2 - x1**2 + x1 - 1 ax = plt.figure().add_subplot(projection='3d') ax.set_xlim(-1, 1) ax.set_ylim(-1, 1) surf = ax.plot_surface(x0, x1, y_truth, rstride=1, cstride=1, color='green', alpha=0.5) plt.show()
假设我们事先并不知道这个函数表达式,我们的目标,是通过一组采样点,把这个y=f(x)要“还原出来”。这就是gplearn遗传算法的“符号学习”。
其实像随机森林或者决策树,本身也是对y=f(x)建模,只不过它的参数是藏在模型里,没有符号化。
数据采样,生成训练集和测试集:
rng = check_random_state(0) # Training samples X_train = rng.uniform(-1, 1, 100).reshape(50, 2) y_train = X_train[:, 0]**2 - X_train[:, 1]**2 + X_train[:, 1] - 1 # print(X_train, y_train) # Testing samples X_test = rng.uniform(-1, 1, 100).reshape(50, 2) y_test = X_test[:, 0]**2 - X_test[:, 1]**2 + X_test[:, 1] - 1
然后我们分别使用gplearn, 随机森林和决策树,对训练集建模:
est_gp = SymbolicRegressor(population_size=5000, generations=20, stopping_criteria=0.01, p_crossover=0.7, p_subtree_mutation=0.1, p_hoist_mutation=0.05, p_point_mutation=0.1, max_samples=0.9, verbose=1, parsimony_coefficient=0.01, random_state=0) est_gp.fit(X_train, y_train) print(est_gp._program) est_tree = DecisionTreeRegressor() est_tree.fit(X_train, y_train) est_rf = RandomForestRegressor() est_rf.fit(X_train, y_train)
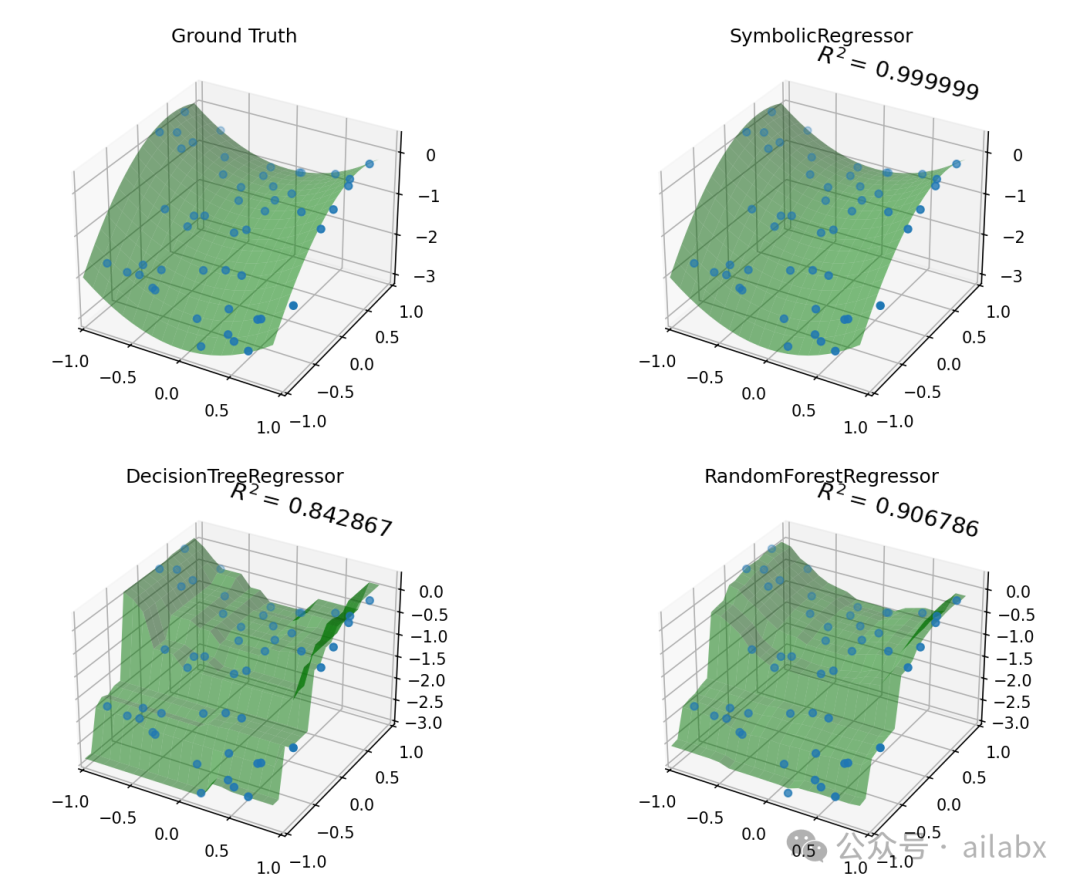
以下是gplearn regressor建模过程,我们使用est_gp._program,打印出最终的公式:
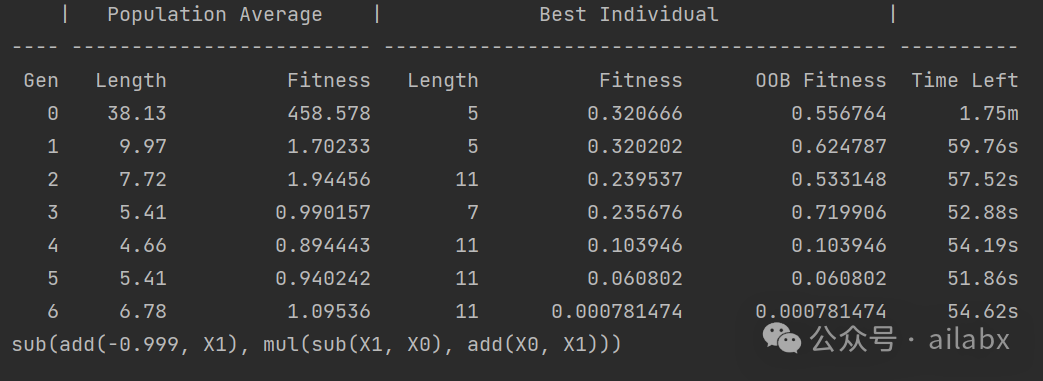
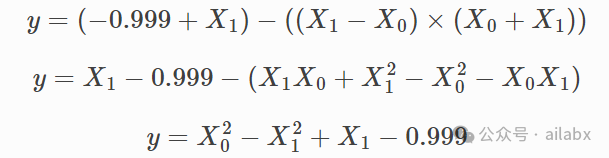
符号表达式与我们日常的表达可能不一样,按上述转化一下,就可以看出来,拟合得很好。
我们看一下符号拟合与机器学习建模的差别:
gplearn基本是99%还原了原函数,而机器学习则有不小的“偏差”:
y_gp = est_gp.predict(np.c_[x0.ravel(), x1.ravel()]).reshape(x0.shape) score_gp = est_gp.score(X_test, y_test) y_tree = est_tree.predict(np.c_[x0.ravel(), x1.ravel()]).reshape(x0.shape) score_tree = est_tree.score(X_test, y_test) y_rf = est_rf.predict(np.c_[x0.ravel(), x1.ravel()]).reshape(x0.shape) score_rf = est_rf.score(X_test, y_test) fig = plt.figure(figsize=(12, 10)) for i, (y, score, title) in enumerate([(y_truth, None, "Ground Truth"), (y_gp, score_gp, "SymbolicRegressor"), (y_tree, score_tree, "DecisionTreeRegressor"), (y_rf, score_rf, "RandomForestRegressor")]): ax = fig.add_subplot(2, 2, i+1, projection='3d') ax.set_xlim(-1, 1) ax.set_ylim(-1, 1) surf = ax.plot_surface(x0, x1, y, rstride=1, cstride=1, color='green', alpha=0.5) points = ax.scatter(X_train[:, 0], X_train[:, 1], y_train) if score is not None: score = ax.text(-.7, 1, .2, "$R^2 =\/ %.6f$" % score, 'x', fontsize=14) plt.title(title) plt.show()
上述代码在如下位置,代码统一于周五,在星球更新:
再来看一个Transformer的例子:
使用sklearn的diabetes数据集,使用Ridge岭回归建模,训练集是前300条,后面为测试集。
import numpy as np from gplearn.genetic import SymbolicTransformer from gplearn.utils import check_random_state from sklearn.datasets import load_diabetes from sklearn.linear_model import Ridge rng = check_random_state(0) diabetes = load_diabetes() perm = rng.permutation(diabetes.target.size) diabetes.data = diabetes.data[perm] diabetes.target = diabetes.target[perm] est = Ridge() est.fit(diabetes.data[:300, :], diabetes.target[:300]) print(est.score(diabetes.data[300:, :], diabetes.target[300:]))
原始特征的条件下,测试集的准确率为:43%。

我们合适gplearn的Transformer对数据进行”变形“(特征工程),把新特征添加进去后,再使用Ridge岭回归,
function_set = ['add', 'sub', 'mul', 'div', 'sqrt', 'log', 'abs', 'neg', 'inv', 'max', 'min'] gp = SymbolicTransformer(generations=20, population_size=2000, hall_of_fame=100, n_components=10, function_set=function_set, parsimony_coefficient=0.0005, max_samples=0.9, verbose=1, random_state=0, n_jobs=3) gp.fit(diabetes.data[:300, :], diabetes.target[:300]) gp_features = gp.transform(diabetes.data) # 把新特征加到源数据中 new_diabetes = np.hstack((diabetes.data, gp_features)) est = Ridge() est.fit(new_diabetes[:300, :], diabetes.target[:300]) print(est.score(new_diabetes[300:, :], diabetes.target[300:]))
最后简单说一下classfier:
区别在于y是离散标签还是连续标签,离散就是分类,连续就是回归。
from gplearn.genetic import SymbolicClassifier from gplearn.utils import check_random_state from sklearn.datasets import load_breast_cancer from sklearn.metrics import roc_auc_score rng = check_random_state(0) cancer = load_breast_cancer() perm = rng.permutation(cancer.target.size) cancer.data = cancer.data[perm] cancer.target = cancer.target[perm] est = SymbolicClassifier(parsimony_coefficient=.01, feature_names=cancer.feature_names, random_state=1) est.fit(cancer.data[:400], cancer.target[:400]) y_true = cancer.target[400:] y_score = est.predict_proba(cancer.data[400:])[:,1] print(roc_auc_score(y_true, y_score))
预测结果如下所示:

三个函数其实背后的fit逻辑是一样的,只是针对不同的数据集,对外提供一些差异化的接口罢了。
我们更关注的是gplearn如何应用于AI量化的因子挖掘过程。
因子挖掘,本质上就是把原始数据看成是初始特征,然后对特征进行非线性的变换的”特征工程“,因此,使用的是transformer这个函数:
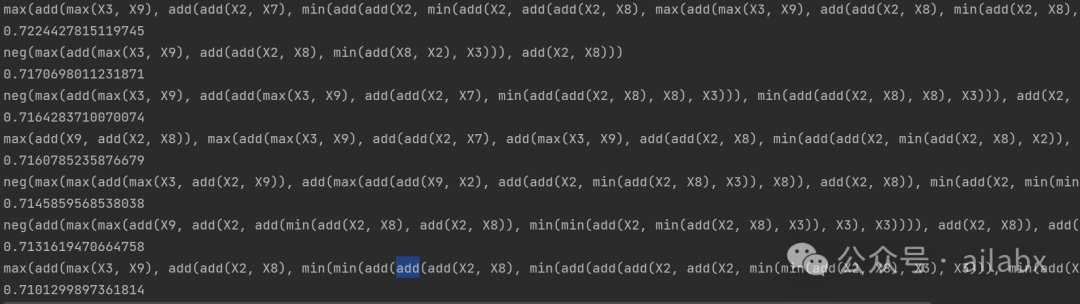
gp.fit(diabetes.data[:300, :], diabetes.target[:300]) for p in gp._best_programs: print(p) print(p.raw_fitness_)
上述代码就可以把最终符合条件的因子——新的特征打印出来,以及它们的fitness适应度:
然后还有两件事,我们可以做:一是修改fitness适应度函数,二是扩展自定义的函数。
自定义一个时间序列函数,比如shift,注意,这里常数是无法做为参数的,所以,只能固化下来,比如shift(se, 5)
def _shift_5(se): window = 5 values = pd.Series(se).shift(window).values values = np.nan_to_num(values) return values
然后添加到function set里即可:
shift_5 = make_function(function=_shift_5, name='shift_5', arity=1) function_set += [shift_5]
明天咱们继续扩展函数集,以及构建自己的fitness。
吾日三省吾身
心气很重要,意志力,或者说希望。
在星球的介绍中,我结尾的一句话是:
七年之约,只是开始。
践行长期主义。
万物之中,希望至美。
刚才我专门查了一下,传奇投机大师,利弗莫尔为何自杀。很多人误以为是投机失败,其实大师晚年经济状况还不错。是多年多次婚姻失败,让他抑郁,而叠加投机失利事件,让他信仰崩溃,因而举枪自杀。
希望,确实是人类头脑机制里产生的最最美好的东西。
因为有希望,人可以承受很多痛苦,延迟满足。
一旦无欲无求,心气散了,人如同行尸走肉,提不起精神。
人间到底值得不值得,人生有没有意义?
反正你只活一次,大胆一点,去体验,去经历,去尝试。
找到自己喜欢做的事情,喜欢做事情的方式:
比如: 自由,探索,新奇,应用。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103524
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!