
Quantlab3.3(这个版本兼容2.x主体,更简洁,性能更高,代码更易读,总之,建议大家尽快更新):
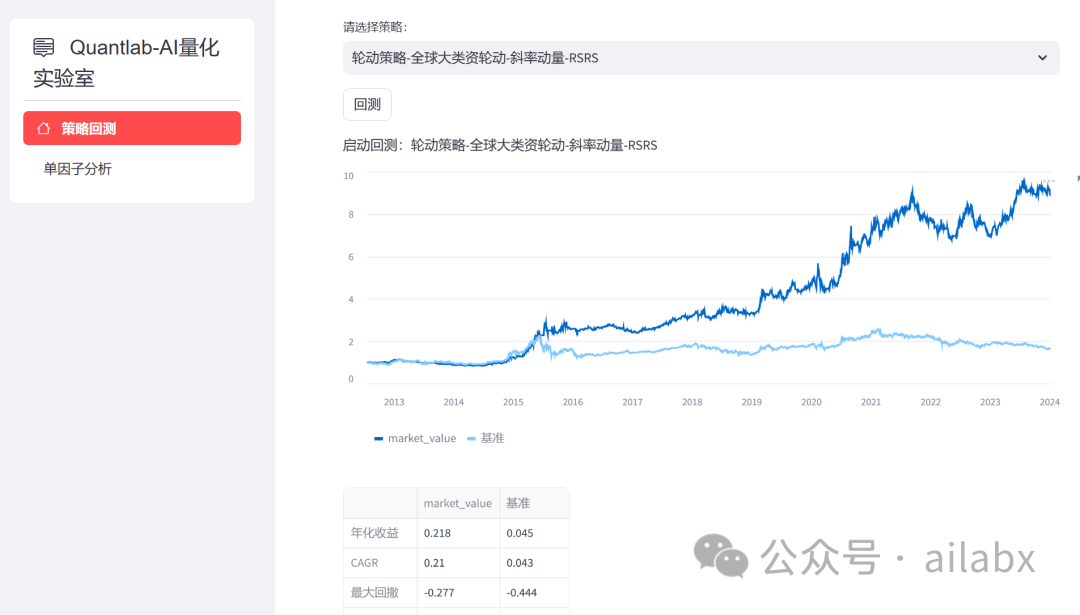
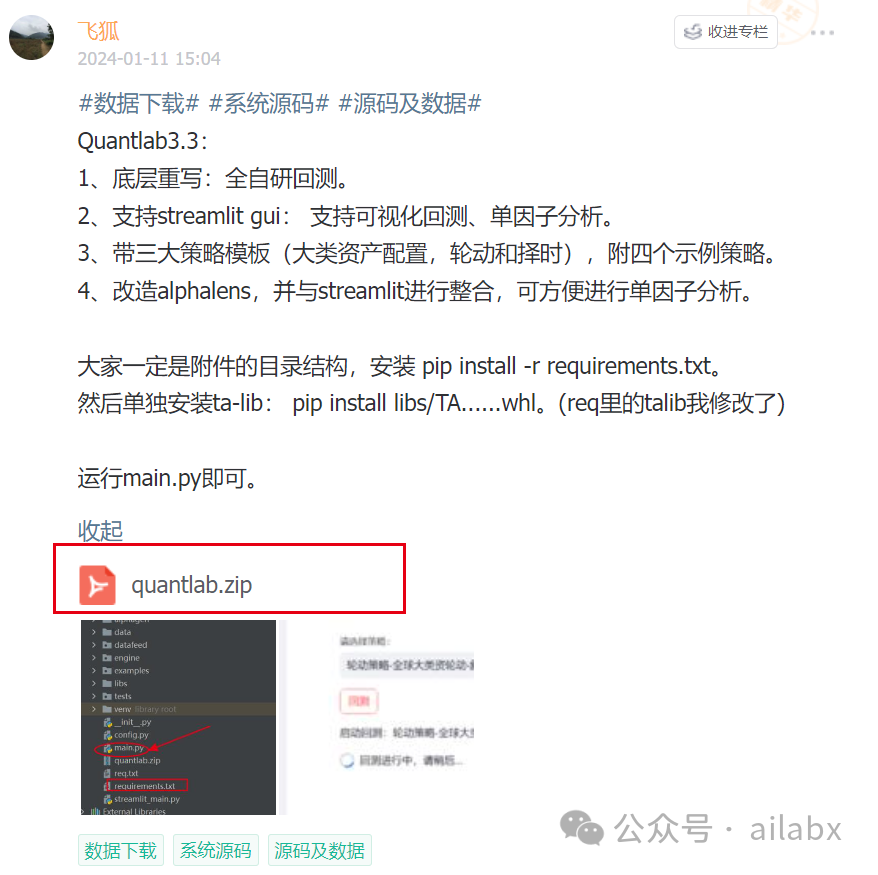
先上图——策略回测:

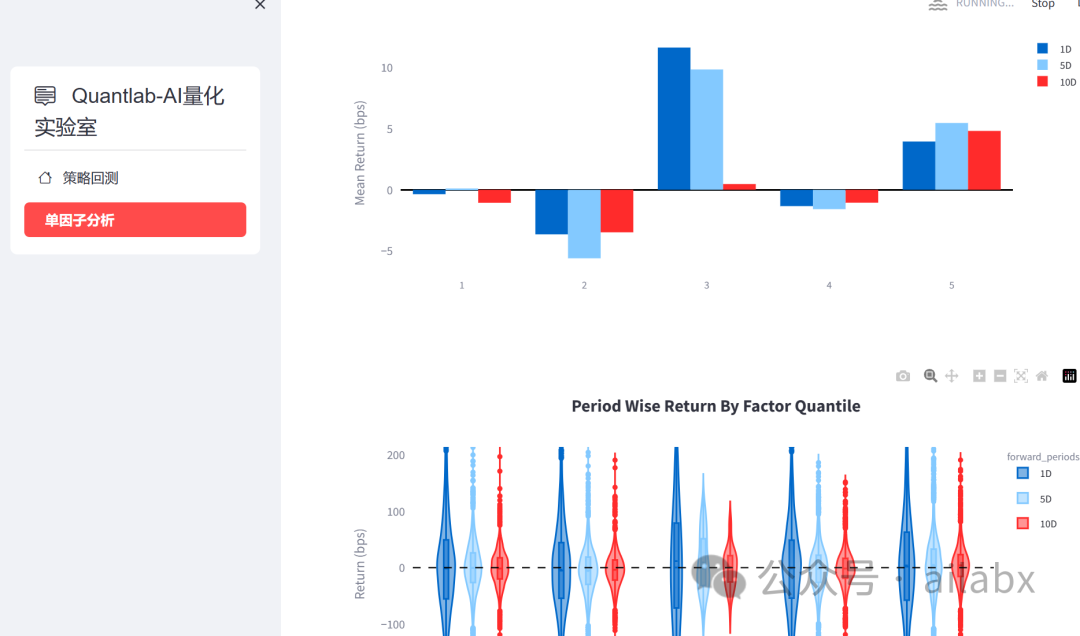
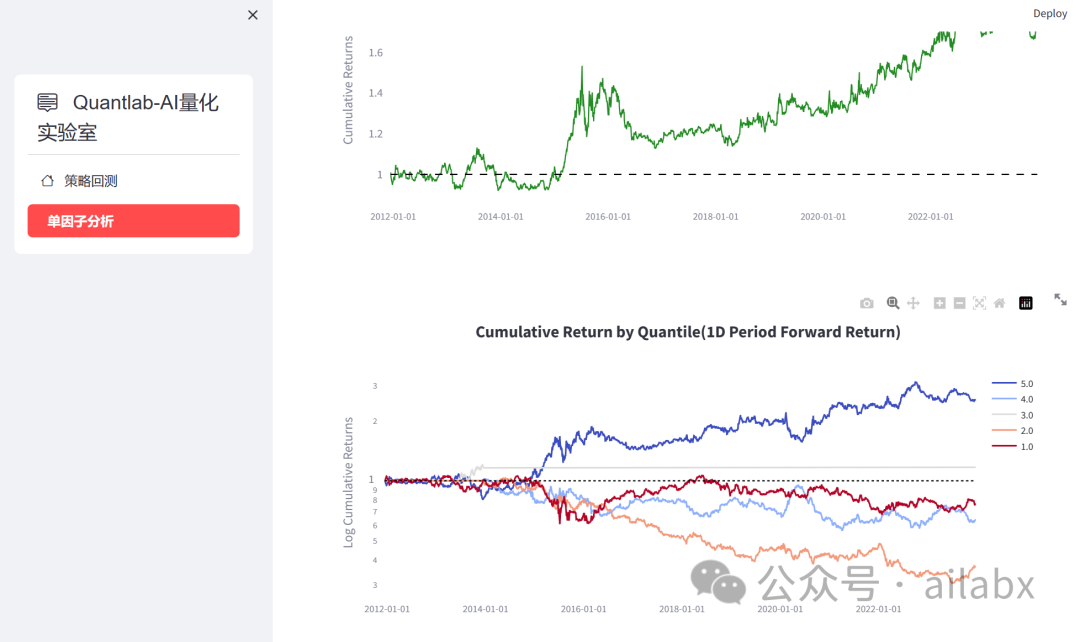
单因子分析(Alphalens-reloaded+streamlit整合):
1、底层重写:全自研回测。
2、支持streamlit gui:支持可视化回测、单因子分析。
3、带三大策略模板(大类资产配置,轮动和择时),附四个示例策略。
4、改造alphalens,并与streamlit进行整合,可方便进行单因子分析。
大家一定按照附件的目录结构,python3.9的环境。
安装 pip install -r requirements.txt。然后单独安装ta-lib:
pip install libs/TA_Lib-0.4.24-cp39-cp39-win_amd64.whl。
运行main.py即可。
今日计划:
1、静待花开策略。
2、stock ranker 1.0代码(lightgbm l2r)实现。
今天同样来做一个轮动策略——静待花开。
发现在一些平台,这个策略的参数需要打赏才能获得了。之前写过,在3.3我们刷新一下:
def Rolling_flower(): task = TaskRolling() task.name = '轮动策略-全球大类资轮动-静待花开' task.benchmark = '510300.SH' task.start_date = '20150115' task.symbols = [ '511220.SH', # 城投债 '512010.SH', # 医药 '518880.SH', # 黄金 '163415.SZ', # 兴全商业 '159928.SZ', # 消费 '161903.SZ', # 万家行业优选 '513100.SH' # 纳指 ] # 证券池列表 task.features = ["因子" ] task.feature_names = ["因子名"] task.rules_buy = ['买入信号'] task.rules_sell = ["卖出信号"] task.order_by = '排序因子' task.topK = 8 return task
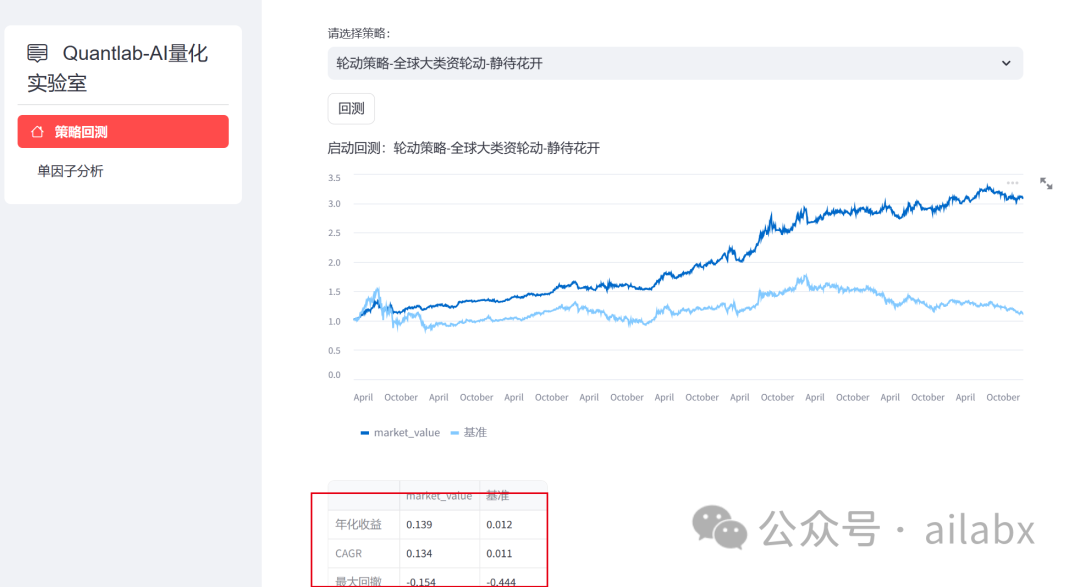
年化13.9%,回撤15%。大家前往星球下载代码体验。
第2件事情,还实现StockRanker,为后续多因子机器学习做好准备。
def train(self, x_train, y_train, q_train, model_save_path): ''' 模型的训练和保存 :param x_train: :param y_train: :param q_train: :param model_save_path: :return: ''' train_data = lgb.Dataset(x_train, label=y_train, group=q_train) params = { 'task': 'train', # 执行的任务类型 'boosting_type': 'gbrt', # 基学习器 'objective': 'lambdarank', # 排序任务(目标函数) 'metric': 'ndcg', # 度量的指标(评估函数) 'max_position': 10, # @NDCG 位置优化 'metric_freq': 1, # 每隔多少次输出一次度量结果 'train_metric': True, # 训练时就输出度量结果 'ndcg_at': [10], 'max_bin': 255, # 一个整数,表示最大的桶的数量。默认值为 255。lightgbm 会根据它来自动压缩内存。如max_bin=255 时,则lightgbm 将使用uint8 来表示特征的每一个值。 'num_iterations': 200, # 迭代次数,即生成的树的棵数 'learning_rate': 0.01, # 学习率 'num_leaves': 31, # 叶子数 # 'max_depth':6, 'tree_learner': 'serial', # 用于并行学习,‘serial’:单台机器的tree learner 'min_data_in_leaf': 30, # 一个叶子节点上包含的最少样本数量 'verbose': 2 # 显示训练时的信息 } gbm = lgb.train(params, train_data, valid_sets=[train_data]) # 这里valid_sets可同时加入train_data,val_data gbm.save_model(model_save_path)
传统排序学习的代码都比较简洁,与分类和回归不同之处在于,排序学习还需要一个qtrain的数据。这个咱们明天细说。
关于我:CFA,北大光华金融硕士,十年量化投资实战。 / CTO,全栈技术,AI大模型 。——金融圈最懂技术的男人,没有之一。
原创文章第457篇,专注“AI量化投资、个人成长与财富自由”。
“顺其自然,为所当为”。
生活中难免会遇到这样,那样的事情,人的大脑高级之处,就检讨过去,规划未来。
但过犹不及。
时间总会一天天过去,关键是你要做时间的朋友。——生活如是,工作如是,投资亦如是。
咱们“AI量化实验室“,快三年了,战术方向时常在变,技术选型随时间推移也会变,但初心不变。——长期主义,就是时间的朋友。
投资是一通半通,不必要一会ETF,一会可转债,或者加密货币,尤其之于量化更是如此。
新手强烈建议掌握ETF投资,更容易赚到钱。想迁移到期货或者加密货币,熟练之后也非常容易。
01 django如何在脚本里使用model
django的orm很好用,但它依赖工程的models。
而在金融里,我们很多时候,需要使用脚本来批量导入数据。
代码也是复杂,直接导入models肯定不行,需要在django.setup之前配置:DJANGO_SETTINS_MODULE,然后包路径指定settings.py的位置。
import os
if __name__ == '__main__': os.environ.setdefault("DJANGO_SETTINGS_MODULE", "backend.backend.settings") import django django.setup() from quant.models import FundInfo ret = FundInfo.objects.all().values('name') print(ret)
创建ETF信息基础列表:
import os from quant import mongo_utils import pandas as pd os.environ.setdefault("DJANGO_SETTINGS_MODULE", "backend.backend.settings") import django django.setup() from quant.models import FundInfo, FundTag def create_funds(): df = pd.DataFrame(list(mongo_utils.get_db()['etf_basic'].find({}))) print(df) # 遍历每一行 funds = [] for index, row in df.iterrows(): print(row['name'], row['symbol'], row['fund_type']) fund = FundInfo.objects.filter(symbol=row['symbol']) if not fund: fund = FundInfo( name=row['name'], symbol=row['symbol'] ) funds.append(fund) else: print(fund) print('已经存在') print(funds) FundInfo.objects.bulk_create(funds) if __name__ == '__main__': create_funds()
02 加上筛选标签
django的后台Admin能力还是相当强大的,扩展性也非常好。
class FundAdmin(admin.ModelAdmin): filter_horizontal = ('tags',) list_display = ('name', 'symbol') list_filter = ('tags',) search_fields = ('name', 'symbol')
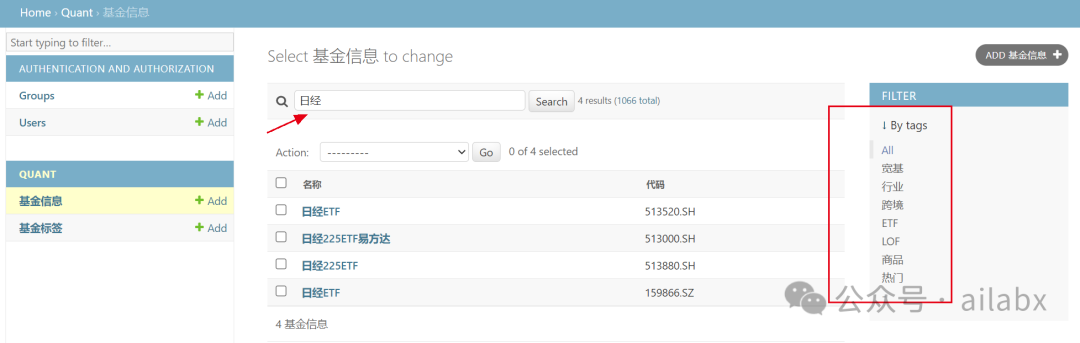
03 筛选标签与分类
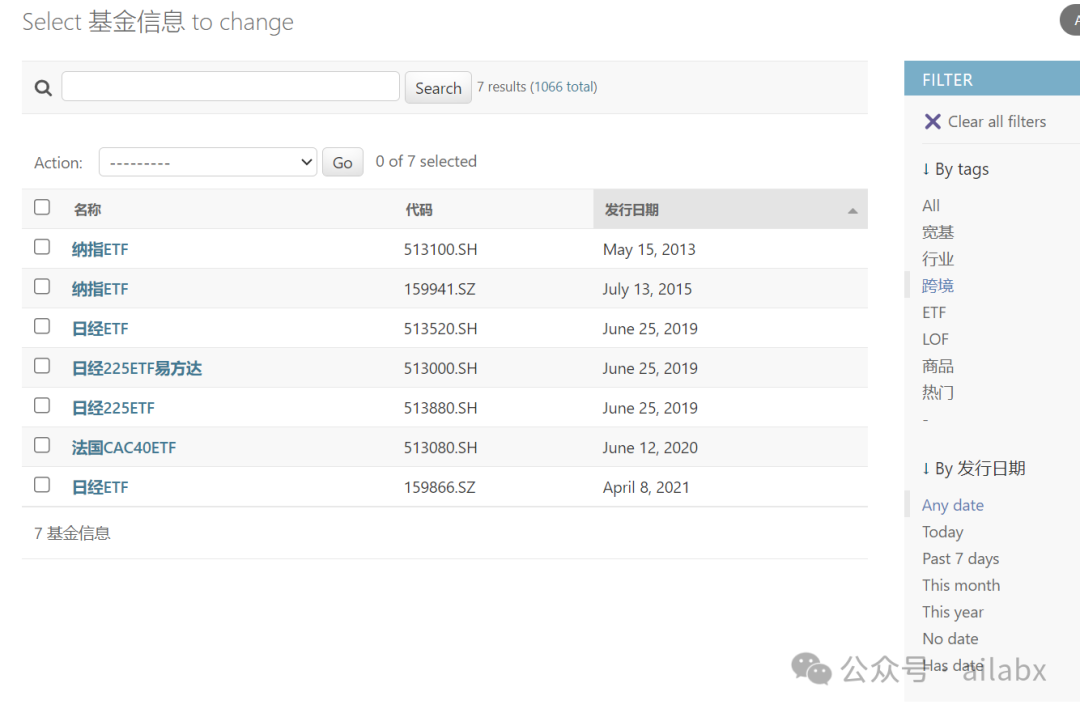
这里标签可以配置后期咱们使用过程,再来细分。
04 streamlit通过接口进行基金选择
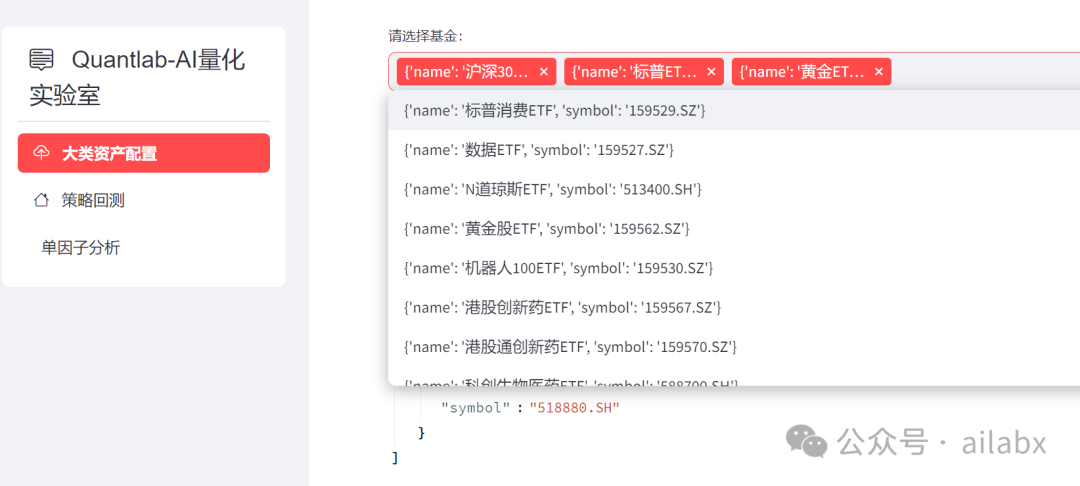
代码如下:
import streamlit as st import requests url = 'http://localhost:8000/api/funds' def select_funds(): data = requests.get(url).json() funds = st.multiselect(label='请选择基金:', options=data) st.write(funds)
完成基金选择:
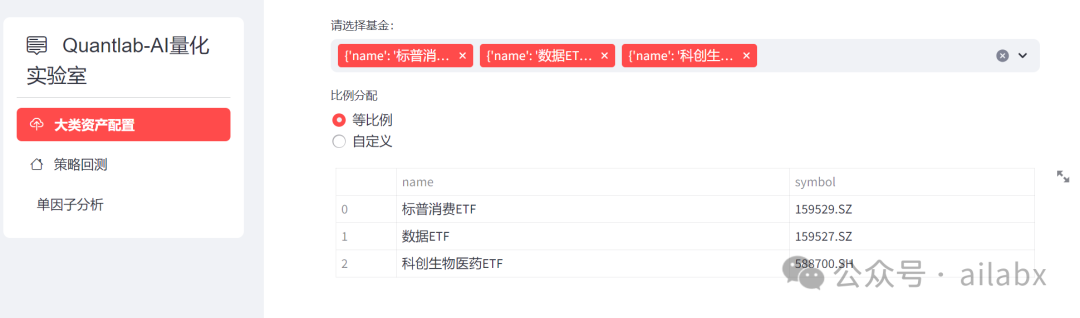
对于大类资产而言,选基是至关重要的,权重当然还可能扩展—风险平价。
明天继续,按惯例,代码会于每周五至少更新一次,包括回测系统与数据:
吾日三省吾身
说人生的意义,有点矫情,但年过不惑,却很真实。
家里老人会淡然聊起”后事“。
就像交待一个非常正常的工作。
人生即是如此,其实每个人都必然会面对。
你拥有的,辉煌,失落都终将失去,我们留下的只有体验的记忆。
都说专注当下,我们只有当下,要珍惜眼前,开开心心,到底是什么意思呢?
明天与意外,谁知道哪个会先来?
你需要为明天做长期主义,延迟满足。可是,明日何其多呢?
我现在的观点,有长期主义的打算与计划,做时间的朋友,在这个基础上——也可以,及时行乐也很重要。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103527
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!