
对于机器模型而言,针对特定的市场,到更多维的数据,设计合适的因子特征工程。今天我把bigquant里预设的几个因子,搁到我们的模型里试试。
features = [
'return_20', # 20日收益
'return_5', # 5日收益
'return_10', # 10日收益
'avg_amount_0/avg_amount_5', # 当日/5日平均交易额
'avg_amount_5/avg_amount_20', # 5日/20日平均交易额
'rank_avg_amount_0/rank_avg_amount_5', # 当日/5日平均交易额排名
'rank_avg_amount_5/rank_avg_amount_10', # 5日/10日平均交易额排名
'rank_return_0', # 当日收益
'rank_return_5', # 5日收益
'rank_return_10', # 10日收益
'rank_return_0/rank_return_5', # 当日/5日收益排名
'rank_return_5/rank_return_10', # 5日/10日收益排名
]
N天收益,我们有表达式:close/shift(close,N) -1
avg函数同均值,就是mean(series,N)。


def mean(se, N): return rolling(se, N, 'mean')def avg(se, N): return rolling(se, N, 'mean')
rank函数是计算截面排序。
def rank(se: pd.Series): rank_result = se.groupby('date').rank(pct=True) return rank_result
ts_rank是计算序列排序:
def ts_rank(se, N): def rank_fn(x): if np.isnan(x[-1]): return np.nan x1 = x[~np.isnan(x)] if x1.shape[0] == 0: return np.nan return percentileofscore(x1, x1[-1]) / len(x1) return se.rolling(N, min_periods=1).apply(rank_fn, raw=True)
特别是rank的这函数,我相信是有道理的。因为我们用的机器模型是lgbRanker,不预测绝对收益,而是相对排序。这时候因子的设计里,相对之间的位置关键就很重要,而不是各自无关联的截面数据。当日收益排名,5日收益排名。短周期排名/长周期排名=排名的变化。
改造之后的函数集:
区别在于哪里呢,这里可费了一翻工夫,之前我们是基于每个symbol的dataframe来计算的,但rank要计算日内的排序,需要把所有symbols的数据搁到一起来计算。
而且rank(avg(return_5)这样的函数是先算symbol的5日收益率均值,然后再symbol间进行排序。
我们需要对之前的“因子表达式”全面改造:
import numpy as npimport pandas as pddef shift(se: pd.Series, N): return se.groupby('symbol').shift(N)def log(se: pd.Series): return se.groupby('symbol').apply(np.log)def rolling(se, N, func): ind = getattr(se.rolling(window=N), func)() return inddef avg(se, N): se = se.groupby('symbol', group_keys=False).apply(rolling, N, 'mean') return sedef sum(se: pd.Series, N): se = se.groupby('symbol', group_keys=False).apply(rolling, N, 'sum') return sedef qcut(se: pd.Series, N): quantiles = [step / 100 for step in range(0, 100, int(100 / N))] if len(quantiles) <= N: quantiles.append(1) # labels = pd.qcut(se, quantiles, labels=range(0, N)).astype('float') labels = se.groupby('symbol', group_keys=False).apply( lambda se: pd.qcut(se, quantiles, labels=range(0, N)).astype('float')) return labels# index.name = 'date',默认都是序列内部,序列间的需要合并df后来计算。def rank(se: pd.Series): rank_result = se.groupby('date').rank(pct=True) return rank_result
loader里的计算逻辑更加简单了:
这里有一个细节,我们需要先把dataframe变成symbol,date双索引,然后进行groupby的计算,然后再reset_index还原回来即可。
def load(self, fields=None, names=None): dfs = self._load_dfs() if not fields or not names or len(fields) != len(names): return self._concat_dfs(dfs) else: df = self._concat_dfs(dfs) df.set_index(['symbol', df.index], inplace=True) for field, name in tqdm(zip(fields, names)): df[name] = calc_expr(df, field) df.reset_index(level='symbol',inplace=True) return df
调用:
if __name__ == '__main__': from engine.datafeed.dataloader import CSVDataloader from engine.config import DATA_INDEX symbols = ['000813.CSI', '000819.SH'] loader = CSVDataloader(DATA_INDEX.resolve(), symbols, start_date="20190101") df = loader.load(fields=['close/shift(close,20)-1', 'rank(roc_20)'], names=['roc_20','rank_roc_20']) print(df)
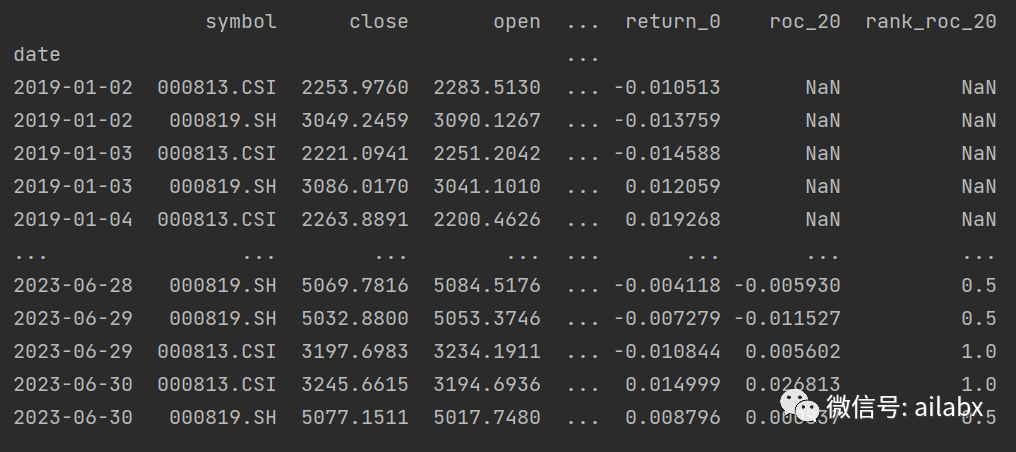
我们的dataset:
def parse_config_to_fields(): fields = [] names = [] windows = [2, 5, 10, 20] fields += ['close/shift(close,%d) - 1' % d for d in windows] names += ['roc_%d' % d for d in windows] fields += ['avg(volume,1)/avg(volume,5)'] names += ['avg_amount_1_avg_amount_5'] fields += ['avg(volume,5)/avg(volume,20)'] names += ['avg_amount_5_avg_amount_20'] fields += ['rank(avg(volume,1))/rank(avg(volume,5))'] names += ['avg_amount_1_avg_amount_5'] fields += ['avg(volume,5)/avg(volume,20)'] names += ['avg_amount_5_avg_amount_20'] windows = [2, 5, 10] fields += ['rank(roc_%d)' % d for d in windows] names += ['rank_roc_%d' % d for d in windows] fields += ['rank(roc_2)/rank(roc_5)'] names += ['rank_roc_2_rank_roc_5'] fields += ['rank(roc_5)/rank(roc_10)'] names += ['rank_roc_5_rank_roc_10'] return fields, names
要讲讲AIGC了,我们还是专注在金融+AIGC上。
昨天LGBRanker排序算法重构,29个行业轮动滚动回测长期年化11.1%(代码与数据下载)提及其实很多人,只是拿着chatGPT的api到处用,觉得自己好像跟上的脚步,这是远远不够的。
但普通人与创业公司,要从头训练大模型,也不务实。有没能中间态呢,普通人或小团队如何低成本的拥抱这个领域呢,这是本文要探讨的话题。
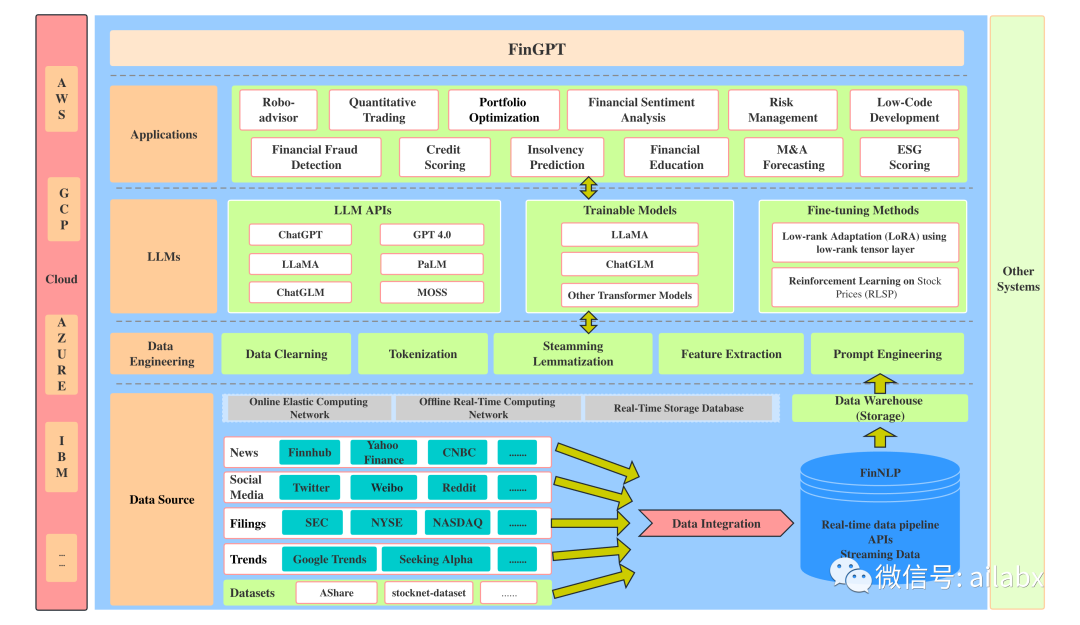
1、数据,主要是文本数据,通过实时的管道进入数据仓库。
2、数据清洗,自然语言处理,token化,prompt工程。
3、使用大模型的api、微调模型。
4、上层应用:智能投研、智能投顾等
小公司或者个人,又怎么能够利用这些开源的大模型,在自己的数据上继续训练,从而应用于自己的业务场景?有没有低成本的方法微调大模型?
答案是有的。目前主流的方法包括2019年 Houlsby N 等人提出的 Adapter Tuning,2021年微软提出的 LORA,斯坦福提出的 Prefix-Tuning,谷歌提出的 Prompt Tuning,2022年清华提出的 P-tuning v2。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104085
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!