
尽期少有的加班,见过凌晨四点的北京。
昨天使用toml配置工程,模块化开发策略的门槛更低,我们引入了toml,对“积木式”策略开发,进一步简化为简单配置文件,为后续使用可视化向导配置打下基础。
1、动量计算函数
由于动量roc的计算比较常用,之前我们使用表达式:close/shift(close,N)-1,现在出发可以使用 roc(close,N)
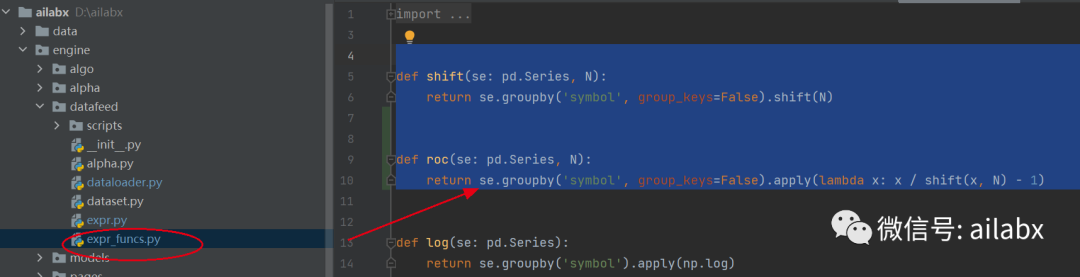
def shift(se: pd.Series, N):
return se.groupby('symbol', group_keys=False).shift(N)
def roc(se: pd.Series, N):
return se.groupby('symbol', group_keys=False).apply(lambda x: x / shift(x, N) - 1)
代码在工程如下位置:

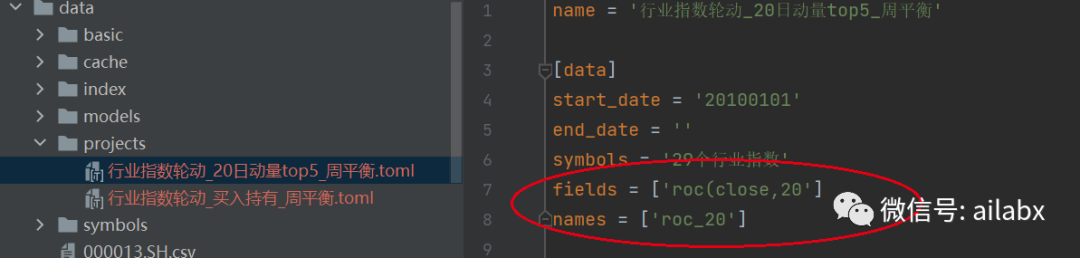
在策略配置里这么写即可:
name = '行业指数轮动_20日动量top5_周平衡' [data] start_date = '20100101' end_date = '' symbols = '29个行业指数' fields = ['roc(close,20'] names = ['roc_20']
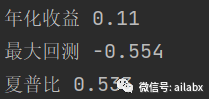
2、20日动量-周平衡-top6的策略,比昨天等权买入持有-周平衡的策略,年化收益从5%提升至11%,且回撤也在下降。
name = '行业指数轮动_20日动量top5_周平衡' [data] start_date = '20100101' end_date = '' symbols = '29个行业指数' fields = ['roc(close,20)'] names = ['roc_20'] [[algos]] name = 'RunWeekly'# 运行周期与再平衡 [[algos]] # 选股 name = 'SelectTopK' K=6 order_by='roc_20' b_ascending= false [[algos]] name = 'WeightEqually'
回测曲线也好看了很多:
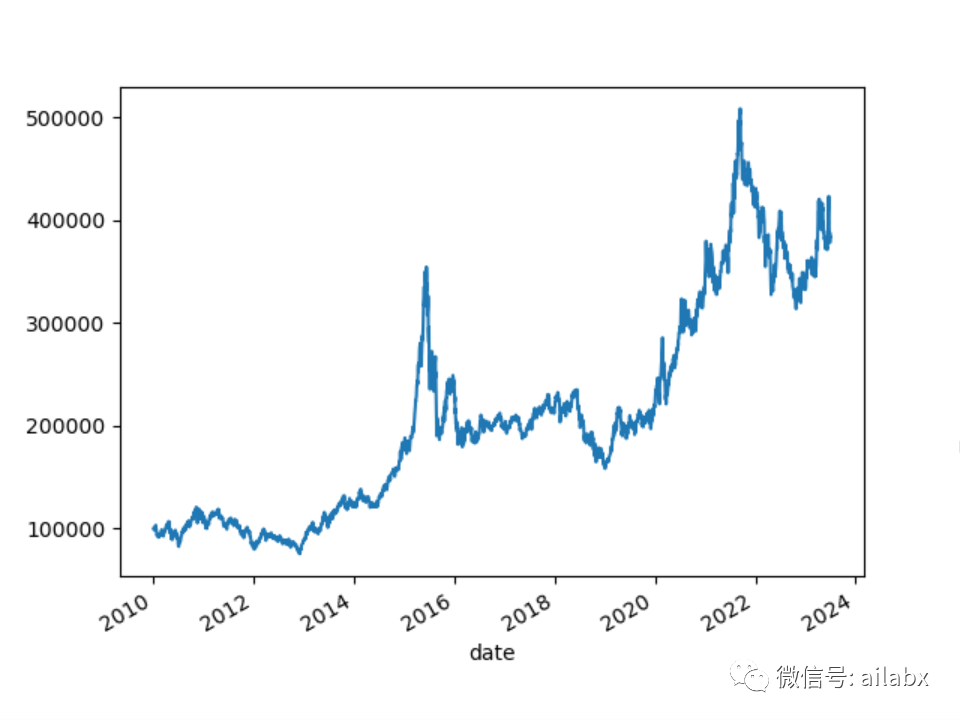
”魔改“版本一,年化提升至13.4%。
大家可以在星球群里问我,这里不多解释了。
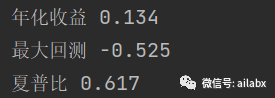
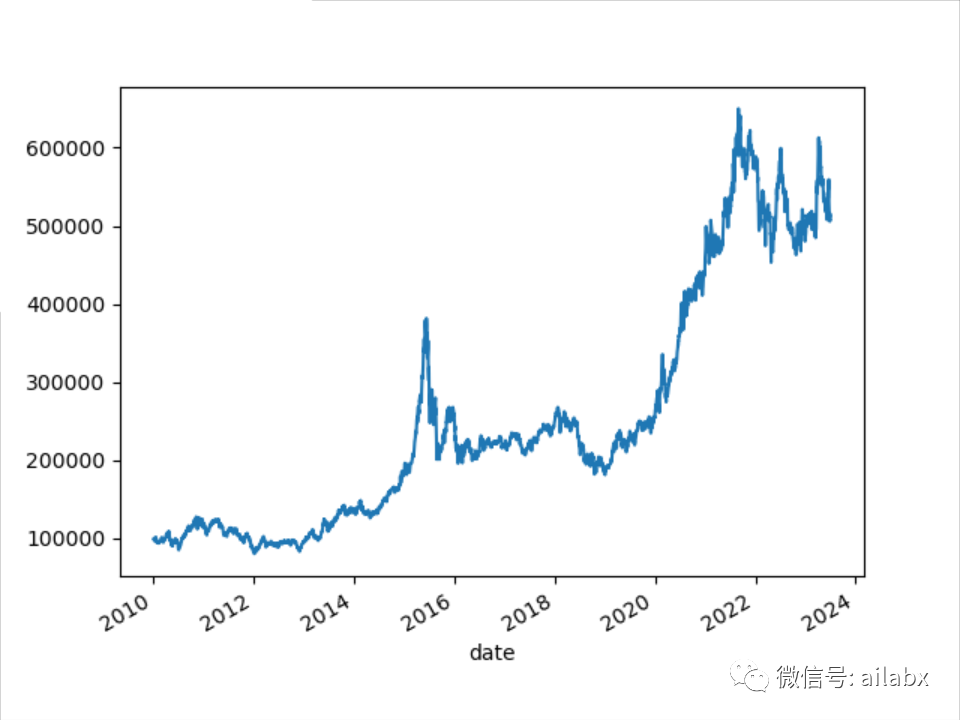
添加benchmark基准:
name = '行业指数轮动_20日动量top6_周平衡' [data] start_date = '20100101' end_date = '' symbols = '29个行业指数' benchmarks=['000300.SH','399006.SZ'] fields = ['roc(close,20)'] names = ['roc_20']
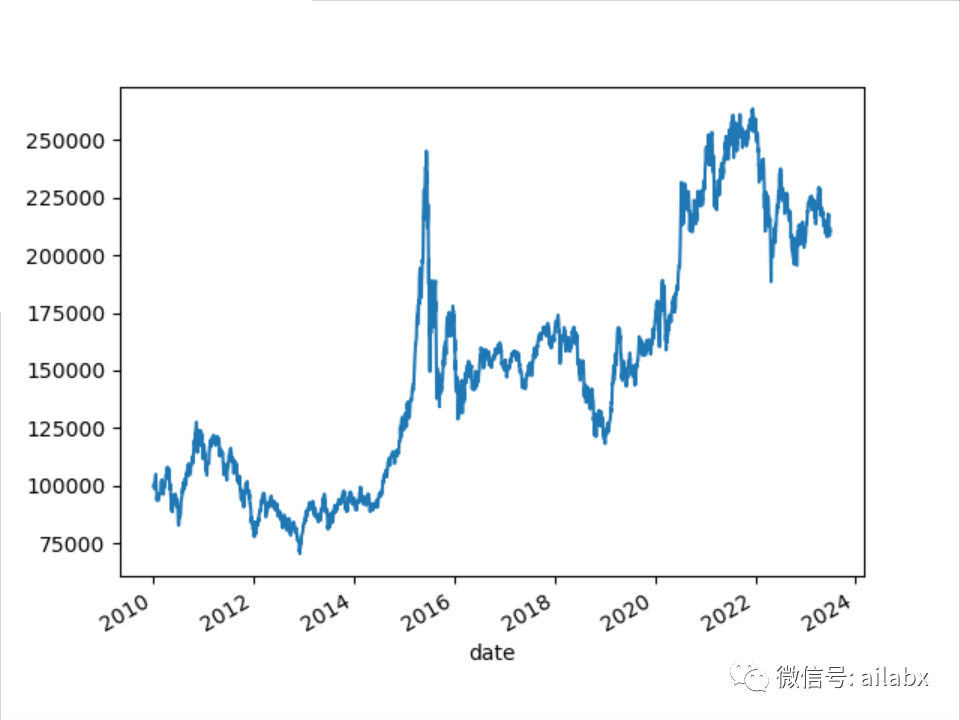
继续改进:年化提升至14.7%,夏普比0.65,远超基准的沪深300与创业板指数。
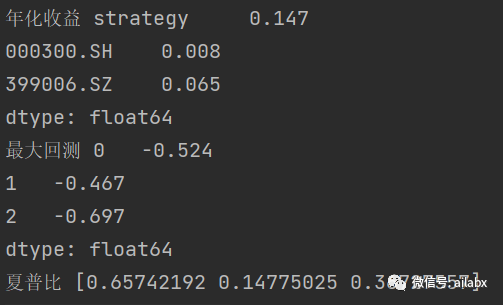
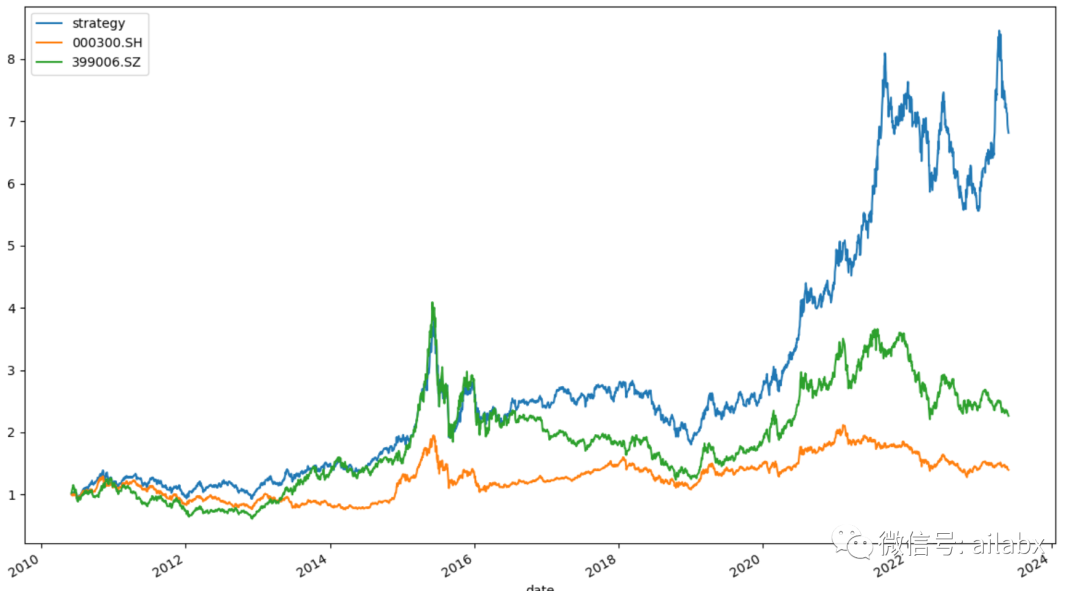
最终的策略文件如下 :
大家运行工程里这个文件即可:
代码更新详见星球:知识星球与开源项目:万物之中,希望至美
name = '行业指数轮动_20日动量top6_周平衡' [data] start_date = '20100101' end_date = '' symbols = '29个行业指数' fields = ['roc(close,20)'] names = ['roc_20'] benchmarks=['000300.SH','399006.SZ'] #bench_fields=['zscore(slope_pair(high,low,18),600)<0'] #bench_names=['rsrs'] [[algos]] name = 'RunDays'# 运行周期与再平衡 days=10 [[algos]] # 选股 name = 'SelectTopK' K=3 drop_top_n=3 order_by='roc_20' b_ascending= false #[[algos]] #name='PickTime' #benchmark='000300.SH' #signal='rsrs' [[algos]] name = 'WeightEqually'
使用name即可调用对应的配置文件,后续我会使用wxpython实现GUI可视化,到时候操作会更加方便。
if __name__ == '__main__': loader = ConfigLoader() print(loader.symbols_dict) print(loader.proj_dict) name = '行业指数轮动_买入持有_周平衡' name = '行业指数轮动_20日动量top6_周平衡' e = Toml2Env(loader.proj_dict[name]) print(e) e.backtest_loop() e.show_results()
工程改进
尽管我们的“积木式”策略模板已经非常简洁,但仍然需要写几行代码。策略一多,有时候修改起来,尤其对于刚入门的同学比较复杂。
我再加一层,写配置文件的形式,把配置文件直接解析成策略。这样就可以通过gui直接生成和修改策略。
与qlib不同,我们使用toml这种config文件格式。
python上pip install toml即可。
代码在如下位置,请前往星球更新代码。知识星球与开源项目:万物之中,希望至美
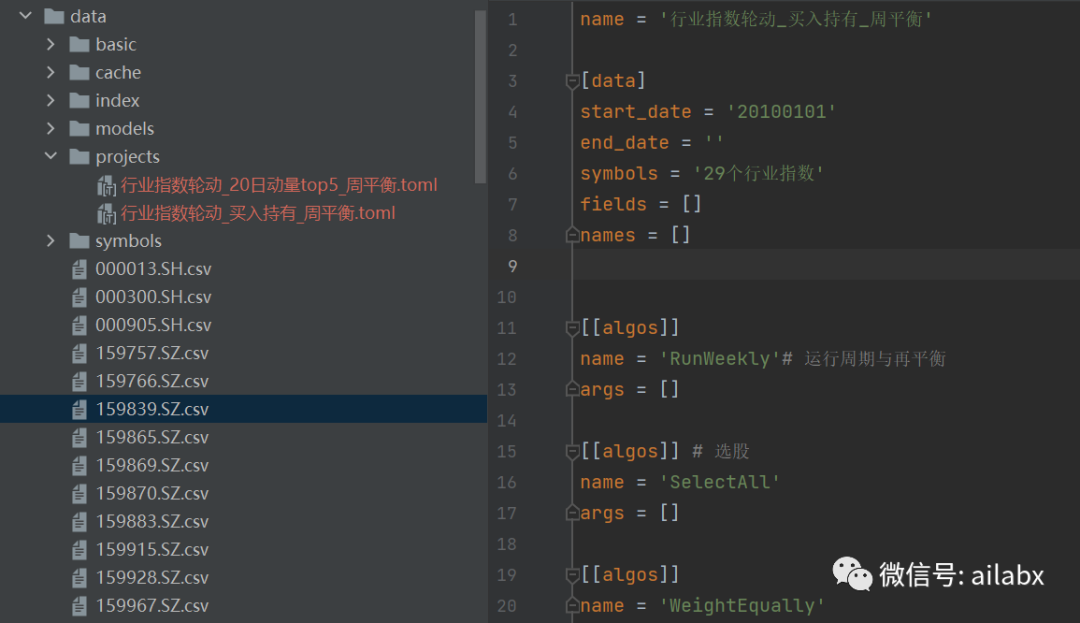
name = '行业指数轮动_买入持有_周平衡' [data] start_date = '20100101' end_date = '' symbols = '29个行业指数' fields = [] names = [] [[algos]] name = 'RunWeekly'# 运行周期与再平衡 args = [] [[algos]] # 选股 name = 'SelectAll' args = [] [[algos]] name = 'WeightEqually'
工程解析的代码:
from engine.config import DATA_PRJ, DATA_SYMBOLS, DATA_INDEX import os import toml from loguru import logger from engine.env import Env from engine.datafeed.dataloader import Hdf5Dataloader, CSVDataloader import importlib def parse_algo(algo_config: dict): module = importlib.import_module('engine.algo') algo = getattr(module, algo_config['name'])() return algo def parse_data(data_config: dict): symbols = data_config['symbols'] start_date = data_config['start_date'] end_date = data_config['end_date'] fields = data_config['fields'] names = data_config['names'] loader = CSVDataloader(path=DATA_INDEX,symbols=symbols, start_date=start_date, end_date=end_date) df = loader.load(fields=fields, names=names) return df def Toml2Env(config: dict): if 'algos' not in config.keys() or 'data' not in config.keys(): logger.error('algos 或者 data 不存在于配置文件') return df = parse_data(config['data']) print(df) e = Env(df) algos_list = config['algos'] algos = [] for algo_config in algos_list: algo = parse_algo(algo_config) algos.append(algo) e.set_algos(algos) return e class ConfigLoader: def __init__(self): self.symbols_dict = {} self.proj_dict = {} self._load_symbols_list() self._load_projects() def _load_symbols_list(self): toml_files = os.listdir(DATA_SYMBOLS.resolve()) for f in toml_files: config = toml.load(DATA_SYMBOLS.joinpath(f)) if 'name' not in config.keys() or 'symbols' not in config.keys(): logger.error('{}文件格式不对,请检查!'.format(DATA_SYMBOLS.joinpath(f))) return name = config['name'] symbols = config['symbols'] self.symbols_dict[name] = symbols def _load_projects(self): toml_files = os.listdir(DATA_PRJ.resolve()) for f in toml_files: config = toml.load(DATA_PRJ.joinpath(f)) if 'name' not in config.keys() or 'data' not in config.keys() or 'symbols' not in config['data'].keys(): logger.error('{}文件格式不对,请检查!'.format(DATA_PRJ.joinpath(f))) return symbols_name = config['data']['symbols'] config['data']['symbols'] = self.symbols_dict[symbols_name] self.proj_dict[config['name']] = config if __name__ == '__main__': loader = ConfigLoader() print(loader.symbols_dict) print(loader.proj_dict) # name = '行业指数轮动_买入持有_周平衡' name = '行业指数轮动_20日动量top5_周平衡' e = Toml2Env(loader.proj_dict[name]) print(e) e.backtest_loop() e.show_results()
昨天再听2023版本的富爸爸、穷爸爸,梳理一下。
核心概括起来就是一句话:不要为钱工作,要让钱为你工作。
前半句讲成长,在李笑来的财富自由之路里,就是“成长是刚需”。尤其是年轻的时候,不能盯着这里高3K还是怎么,而是你想拥有什么技能,能够学到什么东西。所以,年轻时候去大厂是有好处的,尤其是当年高成长的BAT、TMD这样的头部公司。对外是“创造价值”,——这是百万富翁快车道里提及的概念。
这一点很多人没真的想明白,年轻的时候工作就是工作,做一天和尚撞一天钟的心态,其实真正浪费的是自己时间与成长机会。
后半句更好理解,让钱为你工作,核心就是积累资产,所谓资产是可以带来现金流入的东西,增值或者产生再多流。房子、证券、知识产权。其实多数人也就这三样。房子不必说的,但门槛高流动性一般,证券的门槛是本金与投资技能,知识产权与前半句可以结合起来,就是你越成长,你越可能打造属于自己的产权的作品,坐拥被动现金流。
代码请前往星球下载。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104083
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!