
大概率,会启用pybroker。
底层引擎换成pybroker后,重构完成:


一个很重要的原因,其实咱们现在的框架,与框架之间耦合不多。就是在再平衡环境调用了一下api。因此,咱们换引擎很容易,而且与大家无关,是透明的,对大家无感。
为何要换?
backtrader代码是严谨,但很多方式确实是上个世纪的东西了。python也在进化。
pybroker的调用代码如下——特别简洁,而且所有代码要读完都特别容易:
class Engine: def __init__(self, df: pd.DataFrame, config: ProjConfig, global_observer=None): self.strategy = StrategyAlgos(df, config, global_observer) self.result = None def run(self): self.result = self.strategy.backtest() return self.result def analysis(self): logger.debug('回测完成,开始分析...') self.result.orders.to_csv('orders.csv') print(self.result.orders)
还有很多优点,比如天然支持多标的(backtrader要取时间最大的),轮动,机器学习(WFA算法)等。
最大的一个动因是:backtrader要实现再平衡的话,就是有些要买,有些要买,非常麻烦,你得自己来计算哪个先卖,否则cash不够。而pybroker由框架决定, 我只需要给它调仓表就好了(order_target_percent)。
看pybroker的代码——BacktestMixin,先执行cover, sell,然后buy。

pybroker的做空实现。
pybroker的逻辑比较简单,就是配置ctx的buy_shares,也就是买入多少股,而最终会拿cash去验证,能成交多少股就成交多少股。买空操作,没有限制,就是记录margin(保证金),也就是说买空的时候,没有验证cash。似乎margin是另一个账户的概念。
pybroker的交易佣金配置:
config_pyb = StrategyConfig(fee_mode=FeeMode.ORDER_PERCENT, fee_amount=config.commission*100)
再强调一次,回测是模糊的正确。
很多同学在纠正的是100股/手,还是现在的100+1。真没必要,回测是验证大逻辑与策略可行性,正确性。
策略产出的信号,最终落实到broker,就是买或卖多少股,然后broker去实际下单。实盘的broker与交易软件的api相关,本身也不会使用无论是pybroker,还是backtrader,都需要封装过。
回测更关心策略的大方向。
pybroker目前看来简洁,符合预期。

长期主义
书中自有黄金屋。
最近读了很多个人成长类的书,有些还是蛮有启发的。
但总结起来,结论可能大家听起来不那么舒服。
就是:成功学就是鸡汤,成长学基本是显学。
什么意思呢?
成功是很多因素加和的结果,其中运气占了很多的比重,不可复制,因此已经成功的人,怎么讲都是对的,如何预判,如何卧薪尝胆,就是运气好罢了。
成长为何是显学呢?你要努力,要专注,要长期主义,要延时满足,听起来熟不熟悉?就是道理你都懂的,而且有的还是互相矛盾的,需要用“多重思维模型”来调和呢。
为何说长期主义呢,长期主义有一点就是“磨刀不误砍柴功”。我们一直在调优“AI量化”回测平台,其实就是磨刀的过程。
今天仍然是优化版本体验:

目前计划在短视频平台(搜索:AI量化实验室)上日更视频课程,大家感兴趣可以关注。

近期代码迭代记录:
2023-10-03 1、修改bug 2、支持console和gui两种模式。 2023-10-01 1、dataclass配置ProjConfig,同步生成toml,配置策略更容易 2、网格策略Algo开发。 2023-09-29 1、toml包不支持异构的array,改用tomli包来读,还是使用toml来写。 2、引入dataclass来读写toml文件,可以直接转成类。 2023-09-28 1、使用pyinstaller打包 pyinstall main.py --noconsole --add-data ./data:./data
吾日三省吾身
国庆假期,之于我比较无感。
朋友圈看大家走遍全国,周游世界。
但想起更多的是,《百万富翁快车道》里说的,为何大家拿辛勤工作的5天,去换取周末2天的休息还这么开心?为何用一年之辛劳,换到这7天到处拥挤的打卡,还这么幸福?
这样一种惯性一定是正确的嘛?
昨天读到一本书,感觉挺好的。
“单干”的逻辑并不是字面上的,一定让你单枪匹马去做自由职业者。它指的是一种状态,也就是当下流行的“超级个体”或者“1人企业”。

为什么需要公司这样的人才组织方式?就是原始社会,由于个体力量弱,只有抱团取暖,相互帮助,大家才能很好地生存下去。工业化时代如此,互联网进入资本时代之后也是。
打造一个体验非常好,还得免费,体验为王,供给过剩的时代,军团化作战,资本加持才能做好。
但进入到互联网下半场,撒个种子就能遍地开花的时代已经过去,商业模式要求必须自己能造血。这时候,利润与成本就变得非常关键。
超级个体是由于基础设施与用户消费习惯成熟。个人做出产品容易,变现模式也变得容易。个人企业的逻辑的成本优化,最小化成本,最大化利润。
所谓商业模式,就是赚钱的模式,也就是如何变现。现在很多企业也转向把这个问题放在第一位。而不是开始只考虑规模,不考虑变现。
超级个体的逻辑是——像经营公司一样经营自己。
你是自己这家公司的CEO,有战略部,销售部,运营部,品牌部,研发部。。。
不想过被他人主导的生活,你就必须自己决定怎么做,而且有勇气去做。
财富是你睡觉的时候,还能产生现金流的东西。产品,稀缺的产品,信息差,解决方案导向,能带来确定性的产品。杠杆倍率=基数 x 溢价。基数=标准化;溢价=独特价值。
新手红利期,向高手学习,对标头部竞品。跨界升维,差异化。
代码进展,当前版本是1.6,支持通过toml写策略,积木式策略模式,低代码量化。
正在进行中的开发,包含但不限于:
1、引入pybroker引擎。
2、全流程单元测试,提升质量。
3、各种经典策略,前沿机器学习模型引入。
量化论坛建设中
AI量化是一个长期主义的事情,做持续有积累,有价值的事情。
上午把AI量化论坛简单搭建了一个,网站也有个样子了,还有优化中。
发现星友中,有好多初学者,也许是好奇,也许是奔着收益。
但无论如何,想学投资,以及想用量化对投资加持,至少这个选择是对的。
星球本身就是一个社群,为何还要一个论坛。
星球对于一些不要花钱,或者犹豫的同学,还是有一点门槛,论坛则是半开放的。正如,有了社群,我们一样有群。
群,最大的问题,就是有些问题要不停的重复回答,因此我想到了一个中间态,就是传统的bbs。大家可以去指定版块先检索答案,若没有解决,则可以再提问,指定版主来回答。
当然,星友会有私密的高级版块,还可以引入圈子等功能。
后面面向不同进度的同学, 我们还是要准备课程的。
单元测试
量化是一个严肃的事情,如何确保程序质量,越小的开发团队,单元测试越发重要。
我们使用pytest单元测试框架。
从咱们很重要的信号选股算子为例:
这个算子,可以输出多条规则,比如“20日动量>0.08”,“收盘价突出上轨”之类的,at_least_count是至少满足多少条规则,比如3条中的两条。这在规则量化中非常实用。direction是信号的方向,是做多,空,还是平仓。
class SelectBySignal(Algo): def __init__(self, rules=[], at_least_count=1, direction='long'): # direction是信号的方向: long:多单, short空单, flat平仓。 super(SelectBySignal, self).__init__() self.rules = rules if at_least_count > len(rules): at_least_count = len(rules) if at_least_count <= 0: at_least_count = 1 self.at_least_count = at_least_count self.direction = direction def _check_if_matched(self, df_bar, rules, at_least_count): matched_items = [] se_count = pd.Series(index=df_bar.index, data=0) for r in rules: se_count += df_bar.eval(r) matched_items = se_count[(se_count.values >= self.at_least_count)].index return matched_items def __call__(self, target): df_bar = target.df_bar matched = None if self.rules and len(self.rules): matched = self._check_if_matched(df_bar, self.rules, self.at_least_count) if len(matched) == 0: return True if self.direction == 'flat': target.temp['selected_flat'] = matched # 卖出信号,如果允许short,那就是做空单,或者平仓 elif self.direction == 'short': target.temp['selected_short'] = matched else: target.temp['selected'] = matched return True
借写单元测试,我重构了一版,使用df.eval,效率高,而且部分信号不需要预先计算了。
这里逻辑分支挺多的,有了单元测试,就不需要担心再次重构的问题了。
from engine.strategy import StrategyAlgo from engine.algos import * from unittest import mock def test_select_by_signal(): s = mock.MagicMock() df_bar = pd.DataFrame( data=[ [3003, 0.08, 1.1], [16888, -0.03, 0.7], ], index=['000300.SH', 'SPX'], columns=['close', 'roc_20', 'rsrs_18'] ) s.df_bar = df_bar s.temp = {} algo = SelectBySignal(rules=['roc_20>0']) algo(s) assert list(s.temp['selected']) == ['000300.SH'] s.temp = {} algo = SelectBySignal(rules=['roc_20<0','rsrs_18<0.8'], at_least_count=3) algo(s) assert list(s.temp['selected']) == ['SPX'] s.temp = {} algo = SelectBySignal(rules=['roc_20<0', 'rsrs_18<0.8'], at_least_count=3, direction='flat') algo(s) assert list(s.temp['selected_flat']) == ['SPX'] s.temp = {} algo = SelectBySignal(rules=['roc_20>-1', 'rsrs_18>1'], at_least_count=1, direction='short') algo(s) assert list(s.temp['selected_short']) == ['000300.SH', 'SPX'] s.temp = {} algo = SelectBySignal(rules=['roc_20>-1', 'rsrs_18>2'], at_least_count=2, direction='short') algo(s) assert 'selected_short' not in s.temp.keys() s.temp = {} algo = SelectBySignal(rules=['roc_20<0', 'rsrs_18<0.8'], at_least_count=0, direction='flat') algo(s) assert list(s.temp['selected_flat']) == ['SPX']
几点体会,
1、python这样的脚本语言,有些分支错误会带到运行时,使用单元测试覆盖下很有必要。
2、写单元测试时,反而会帮我们补充很多边界条件(尤其是异常分支)。
3、代码重构后,可以轻松验证。
这就属于有积累,值得做的事情。
pybroker
之前其实写过系列文章:
基于pybroker的动量轮动+排序模型,年化11%(附代码)
因子表达式,积木式策略开发与pybroker框架整合(附源码)
pybroker:兼容传统规则和机器学习的高性能量化回测框架(附源码)
昨天我在星球里发起的讨论:
backtrader在提交多个订单的时候,是需要自己决定顺序的,比如先卖再买,先平仓再开仓。
要说错吧,也没错,但回测系统可以做得更好,因为这个肯定的。做轮动,再平衡,还要去自己算是买还卖,违背易用的原则。
因为我想再看看pybroker的原因。
pybroker代码看懂很容易,支持它自定义的DataSource也支持Dataframe。
咱们现有的多symbol的dataframe加一个‘date’列就可以使用了,现代技术栈还是比较方便,老框架喜欢封装成各种自己的类。
from pybroker import Strategy from datafeed.dataloader import Duckdbloader from config import DATA_DIR_CSVS symbols = ['000300.SH', '000905.SZ'] loader = Duckdbloader(path=DATA_DIR_CSVS.joinpath('index').resolve(), symbols=symbols, columns=['close', 'high', 'low', 'open', 'volume'], start_date="20100101") df = loader.load() df['date'] = df.index print(df) def exec_fn(ctx): # Buy on a new 10 day high. if not ctx.long_pos(): ctx.buy_shares = 100 # Hold the position for 5 days. ctx.hold_bars = 5 # Set a stop loss of 2%. ctx.stop_loss_pct = 2 strategy = Strategy(df, start_date='1/1/2022', end_date='7/1/2022') strategy.add_execution( exec_fn, symbols) # Run the backtest after 20 days have passed. result = strategy.backtest(warmup=20) print(result.metrics_df) print(result.positions) print(result.trades) import matplotlib.pyplot as plt chart = plt.subplot2grid((3, 2), (0, 0), rowspan=3, colspan=2) chart.plot(result.portfolio.index, result.portfolio['market_value']) plt.show()
pybroker肯定支持卖空,而且是期货,加密货币模式。
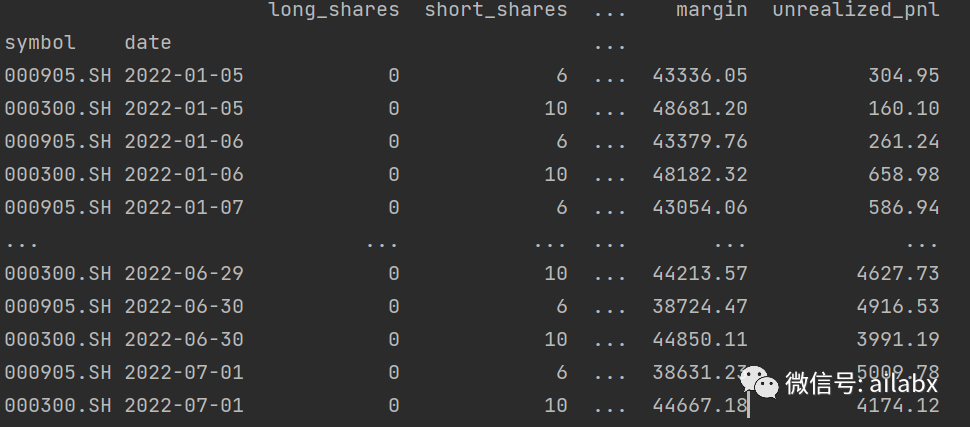
另外就是我最关心的交易执行顺序的问题。
是可以“自动再平衡的”,这是它官网上的例子。
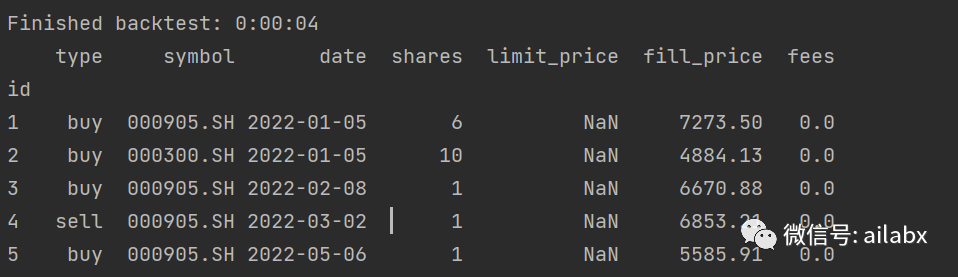
它的execution是分symbol的,就是支持一个symol一个策略,也支持多个symobl一起运算。
之前我认为这很鸡肋,但若是机器学习单独建模,倒是个逻辑,也不影响。
另外,它的metrics竟然没有年化收益,这是我觉得最神奇的地方,当然,这个我们可以自己实现,还是就是它的可视化等于没做,特别简单一个plot。
总体而言,使用它的引擎的话,不考虑周边,感觉更简单,而且发现异常呢,看代码也容易。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103815
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!