
星球群里好多同学在聊,实盘的事情。
量化交易系统自动化,工程化的事情。
客观地说,精力有点放错了地方。我之前也在回测系统的设计上花了很多的心力,当然这个是值得的——主要是为了写策略,优化策略更快,比如“因子表达式”、“模块化写策略”,“策略模板“,”自动化超参数优化“。
交易里最重要的事情是策略。
策略的主流与未来是”多因子“,私募里的策略也是以多因子为主。
多因子策略的优点:容量大,容易与AI、机器学习相结合、容易优化,形式统一。
比如你从5个因子,扩展到500个因子,策略逻辑基本是不需要变的。
如果你是规则策略,这基本是做不到到。信号相互矛盾了如何处理等?
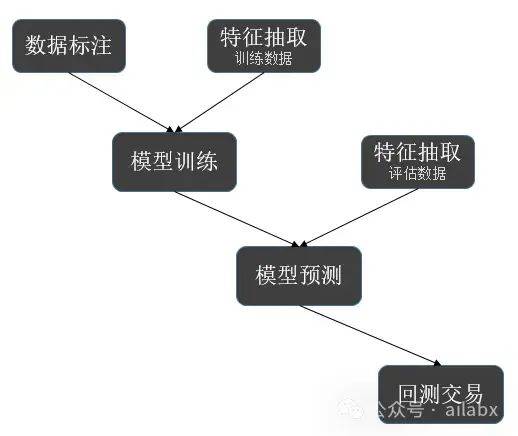
多因子分解为两个部分: 因子挖掘、因子合成(机器学习模型)。
因子合成,借鉴bigquant的思路我们来实现StockRanker。
就是通过多因子,对多支股票进行排序。

下面的代码使用lightGBM对多支ETF进行排序预测。
import joblib import os import lightgbm as lgb def prepare_groups(df): df_copy = df.copy(deep=True) df_copy['day'] = df_copy.index group = df_copy.groupby('day')['day'].count() return group class StockRanker: def __init__(self, load_model=False, feature_cols=None): self.feature_cols = feature_cols if load_model: path = os.path.dirname(__file__) self.ranker = joblib.load(path + '/lgb.pkl') def predict(self, data): data = data.copy(deep=True) if self.feature_cols: data = data[self.feature_cols] pred = self.ranker.predict(data) return pred def train(self, x_train, y_train, q_train, model_save_path): ''' 模型的训练和保存 :param x_train: :param y_train: :param q_train: :param model_save_path: :return: ''' train_data = lgb.Dataset(x_train, label=y_train, group=q_train) params = { 'task': 'train', # 执行的任务类型 'boosting_type': 'gbrt', # 基学习器 'objective': 'lambdarank', # 排序任务(目标函数) 'metric': 'ndcg', # 度量的指标(评估函数) 'max_position': 10, # @NDCG 位置优化 'metric_freq': 1, # 每隔多少次输出一次度量结果 'train_metric': True, # 训练时就输出度量结果 'ndcg_at': [10], 'max_bin': 255, # 一个整数,表示最大的桶的数量。默认值为 255。lightgbm 会根据它来自动压缩内存。如max_bin=255 时,则lightgbm 将使用uint8 来表示特征的每一个值。 'num_iterations': 200, # 迭代次数,即生成的树的棵数 'learning_rate': 0.01, # 学习率 'num_leaves': 31, # 叶子数 # 'max_depth':6, 'tree_learner': 'serial', # 用于并行学习,‘serial’:单台机器的tree learner 'min_data_in_leaf': 30, # 一个叶子节点上包含的最少样本数量 'verbose': 2 # 显示训练时的信息 } #import lightgbm as lgb #gbm = lgb.LGBMRanker() #gbm.fit(x_train, y_train, group=q_train, # eval_set=[(x_train, y_train)], eval_group=[q_train], # eval_at=[5, 10, 20]) #print(gbm.feature_importances_) gbm = lgb.train(params, train_data, valid_sets=[train_data]) # 这里valid_sets可同时加入train_data,val_data print(gbm.feature_importance()) gbm.save_model(model_save_path) def predict(x_test, comments, model_input_path): ''' 预测得分并排序 :param x_test: :param comments: :param model_input_path: :return: ''' gbm = lgb.Booster(model_file=model_input_path) # 加载model ypred = gbm.predict(x_test) predicted_sorted_indexes = np.argsort(ypred)[::-1] # 返回从大到小的索引 t_results = comments[predicted_sorted_indexes] # 返回对应的comments,从大到小的排序 return t_results ''' def train_bak(self, ds: DataSet): X_train, X_test, y_train, y_test = ds.get_split_data() X_train_data = X_train.drop('symbol', axis=1) X_test_data = X_test.drop('symbol', axis=1) # X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=1) query_train = self._prepare_groups(X_train.copy(deep=True)).values query_val = self._prepare_groups(X_test.copy(deep=True)).values query_test = [X_test.shape[0]] import lightgbm as lgb gbm = lgb.LGBMRanker() gbm.fit(X_train_data, y_train, group=query_train, eval_set=[(X_test_data, y_test)], eval_group=[query_val], eval_at=[5, 10, 20], early_stopping_rounds=50) print(gbm.feature_importances_) joblib.dump(gbm, 'lgb.pkl') ''' if __name__ == '__main__': from datafeed.dataloader import CSVDataloader from config import DATA_DIR symbols = [ '511220.SH', # 城投债 '512010.SH', # 医药 '518880.SH', # 黄金 '163415.SZ', # 兴全商业 '159928.SZ', # 消费 '161903.SZ', # 万家行业优选 '513100.SH' # 纳指 ] # 证券池列表 loader = CSVDataloader(path=DATA_DIR.joinpath('etfs'), symbols=symbols) df = loader.load(fields=['slope(close,20)', 'qcut(shift(close,5)/close-1,5)'], names=['roc_20', 'label']) ranker = StockRanker() df.set_index([df.index, 'symbol'], inplace=True) df.sort_index(inplace=True) x_train = df[['roc_20']] y_train = df['label'] q_train = prepare_groups(x_train) print(y_train) ranker.train(x_train=x_train, y_train=y_train, q_train=q_train, model_save_path='model.pkl')
代码在如下这个位置:
明天要添加更多因子,进行更细节的优化。
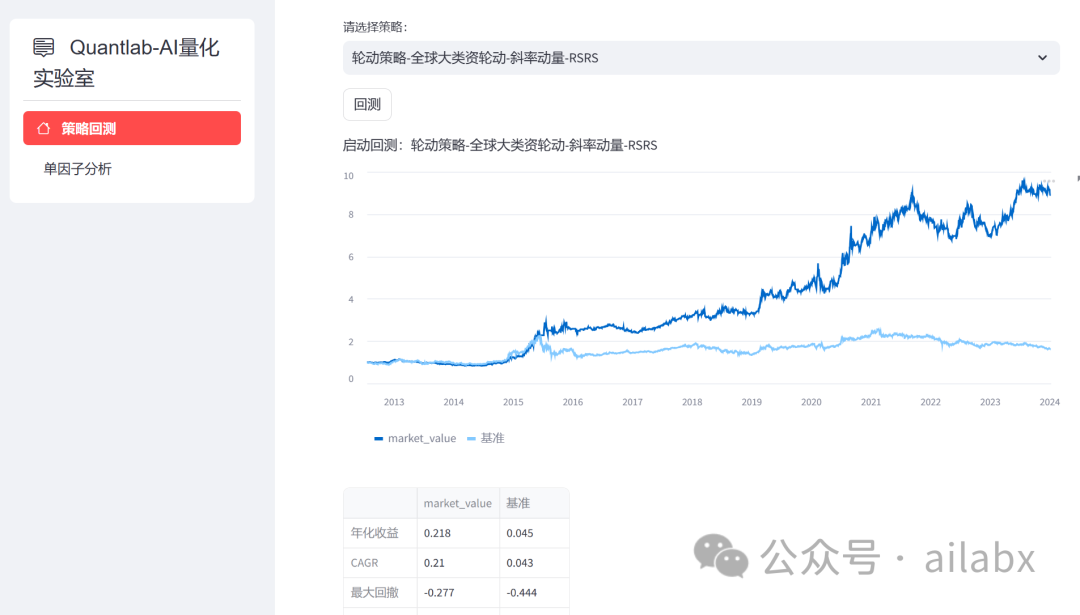
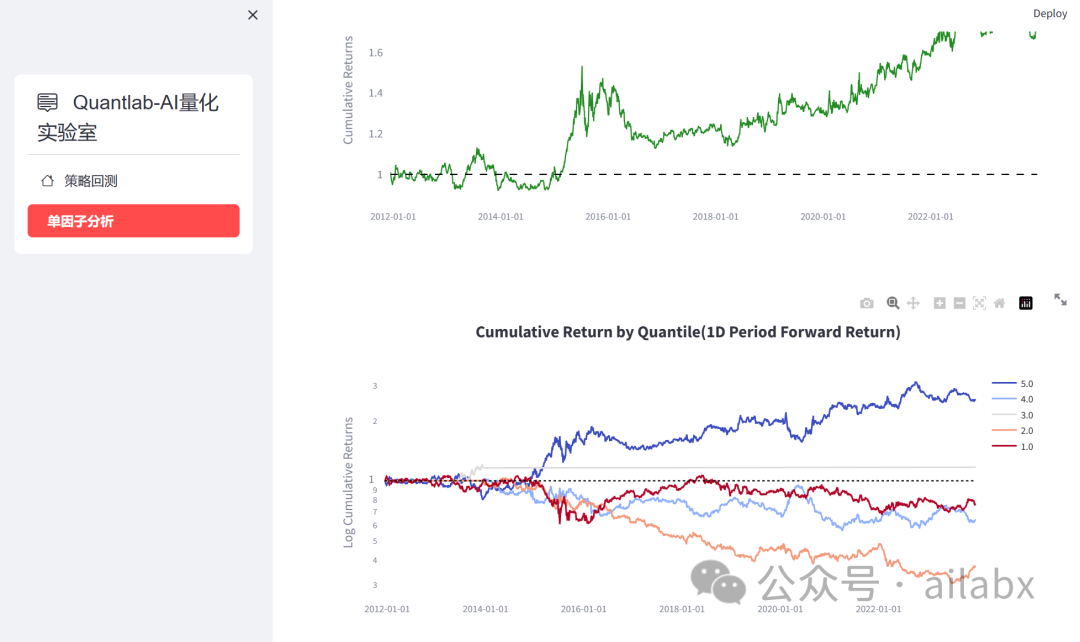
先上图——策略回测:
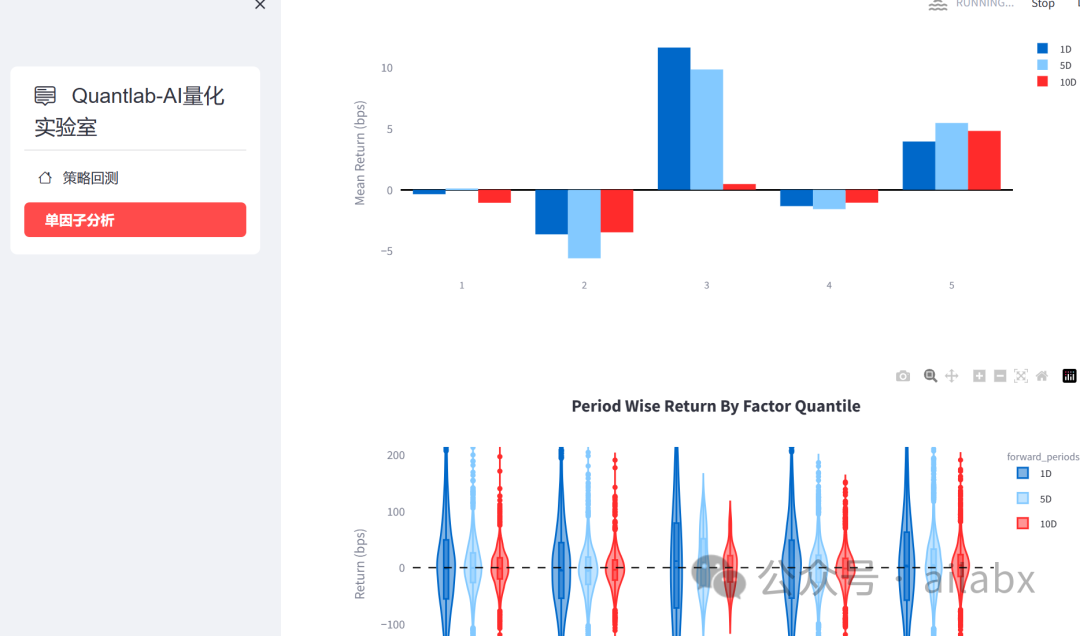
单因子分析(Alphalens-reloaded+streamlit整合):
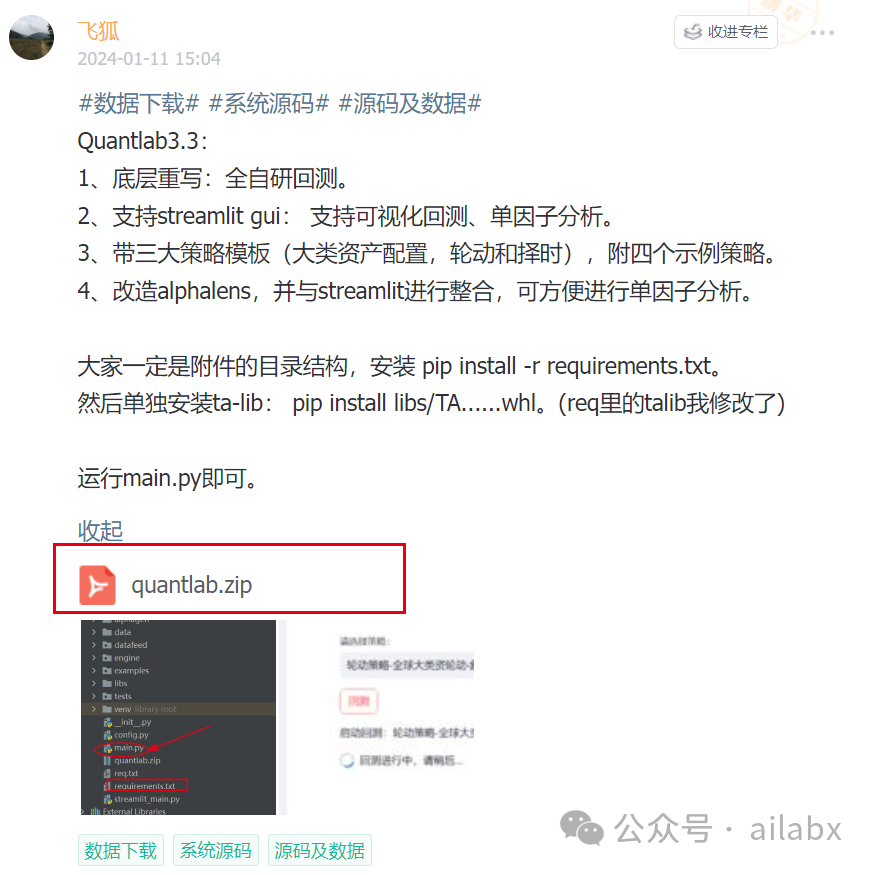
1、底层重写:全自研回测。
2、支持streamlit gui:支持可视化回测、单因子分析。
3、带三大策略模板(大类资产配置,轮动和择时),附四个示例策略。
4、改造alphalens,并与streamlit进行整合,可方便进行单因子分析。
大家一定按照附件的目录结构,python3.9的环境。
安装 pip install -r requirements.txt。然后单独安装ta-lib:
pip install libs/TA_Lib-0.4.24-cp39-cp39-win_amd64.whl。
运行main.py即可。
今日计划:
1、静待花开策略。
2、stock ranker 1.0代码(lightgbm l2r)实现。
今天同样来做一个轮动策略——静待花开。
发现在一些平台,这个策略的参数需要打赏才能获得了。之前写过,在3.3我们刷新一下:
def Rolling_flower(): task = TaskRolling() task.name = '轮动策略-全球大类资轮动-静待花开' task.benchmark = '510300.SH' task.start_date = '20150115' task.symbols = [ '511220.SH', # 城投债 '512010.SH', # 医药 '518880.SH', # 黄金 '163415.SZ', # 兴全商业 '159928.SZ', # 消费 '161903.SZ', # 万家行业优选 '513100.SH' # 纳指 ] # 证券池列表 task.features = ["因子" ] task.feature_names = ["因子名"] task.rules_buy = ['买入信号'] task.rules_sell = ["卖出信号"] task.order_by = '排序因子' task.topK = 8 return task
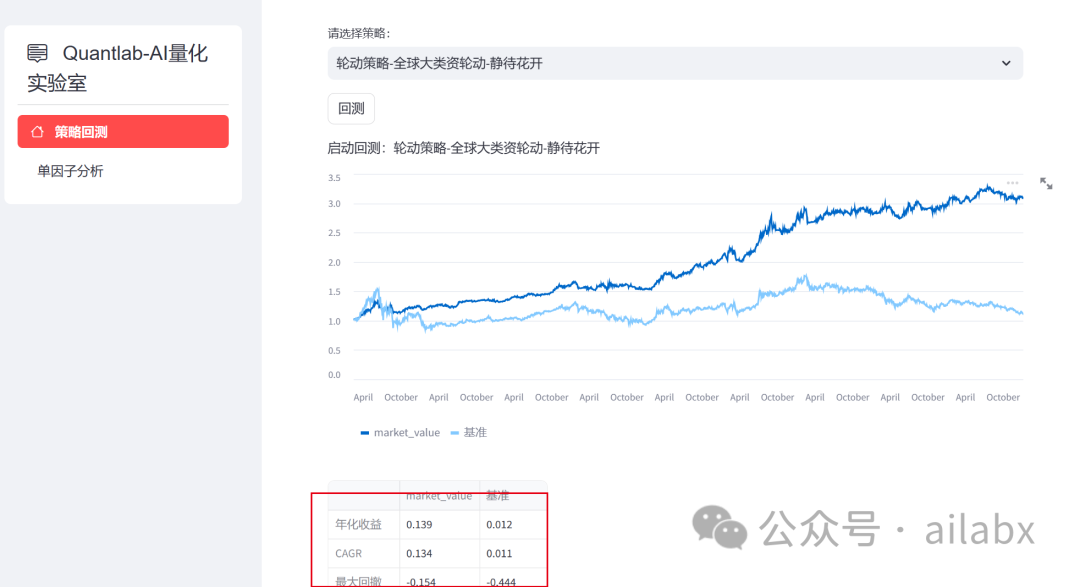
年化13.9%,回撤15%。大家前往星球下载代码体验。
第2件事情,还实现StockRanker,为后续多因子机器学习做好准备。
def train(self, x_train, y_train, q_train, model_save_path): ''' 模型的训练和保存 :param x_train: :param y_train: :param q_train: :param model_save_path: :return: ''' train_data = lgb.Dataset(x_train, label=y_train, group=q_train) params = { 'task': 'train', # 执行的任务类型 'boosting_type': 'gbrt', # 基学习器 'objective': 'lambdarank', # 排序任务(目标函数) 'metric': 'ndcg', # 度量的指标(评估函数) 'max_position': 10, # @NDCG 位置优化 'metric_freq': 1, # 每隔多少次输出一次度量结果 'train_metric': True, # 训练时就输出度量结果 'ndcg_at': [10], 'max_bin': 255, # 一个整数,表示最大的桶的数量。默认值为 255。lightgbm 会根据它来自动压缩内存。如max_bin=255 时,则lightgbm 将使用uint8 来表示特征的每一个值。 'num_iterations': 200, # 迭代次数,即生成的树的棵数 'learning_rate': 0.01, # 学习率 'num_leaves': 31, # 叶子数 # 'max_depth':6, 'tree_learner': 'serial', # 用于并行学习,‘serial’:单台机器的tree learner 'min_data_in_leaf': 30, # 一个叶子节点上包含的最少样本数量 'verbose': 2 # 显示训练时的信息 } gbm = lgb.train(params, train_data, valid_sets=[train_data]) # 这里valid_sets可同时加入train_data,val_data gbm.save_model(model_save_path)
传统排序学习的代码都比较简洁,与分类和回归不同之处在于,排序学习还需要一个qtrain的数据。这个咱们明天细说。
这里说的是“AI量化”,区别于传统量化。
量化相对主观而言,以数量化的方式产生信号,“机械”执行信号。
但传统量化之于主观量化,并没有明显的优势。至少在国内这些年,仍然属于资管的边缘部门。
传统量化,更像传统技术分析的自动化版本。
只不过人工画K线,变成计算机来计算。金叉,通道突破等。技术分析的缺点,传统量化也有。
做得好一点的,加上超参数优化——对参数空间进行遍历,进而找到最优的参数集。——这一点看起来高级了一点点。
规则信号最大的问题,不好优化,就是hard-code的。而且更多的规则不好组合在一起,一般就是M条中满足N条这样的逻辑,不能更加模糊地组合到一起。
而多因子就没有这个问题,技术面,基本面,另类因子,可以通过机器学习按不同的权重复合到一个策略里,这样模型的预测能力就大幅度提升。
另外,通过排序算法,我们需要找出相对更优的股票、期货组合持有等。
StockRanker梯度提升树、排序学习用于股票排序 | gplearn和DeepAlphaGen端到端的因子挖掘系统(开源)
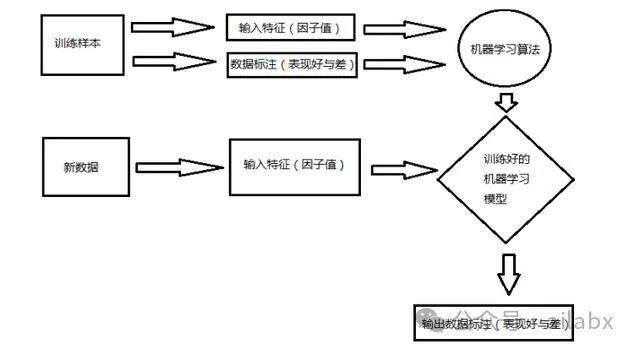
好消息是,私募机构至少当下的主流都是多因子。
多因子很适合拥抱机器学习,深度学习。
因子,对应就是机器学习里的特征工程。
自动特征工程,自动参数优化,在AI领域都是日新月异的进步。
因此,咱们Quantlab后续的计划,主要是支持多因子策略,甚至端到端去构建的。StockRanker梯度提升树、排序学习用于股票排序 | gplearn和DeepAlphaGen端到端的因子挖掘系统(开源)
Qlib本身就是AI-驱动的量化平台,它更加彻底,压根不支持传统量化。
交易模板也仅有一个top K的轮动策略。
当然,它主要精力花在各种前沿的模型上,而不是因子挖掘和筛选上。这一点上qlib走错了方向。
AI量化还有一个很大的好处,它的形式非常统一,我们更多是去积累高质量的因子,而不是花心思去“凑”参数。这一部分甚至可以通过数据挖掘去大量产生,筛选。
比如gplearn和DeepAlphaGen这样的因子筛选框架。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103561
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!