
想想做AI量化的初心,与当初学计算机的逻辑相似。
极少数,不需要依赖所谓大团队可以完成的事情。当然现在计算机个人能完成一个大作品的机会很少了,都是资本在主导。
量化还有。因为投资不是严格意义上的科学,这一点让做的人很痛苦,因为你有时候会发现它毫无规律,而恰恰是这一点,让普通人让有机会参与其中。否则规律早就被挖掘了。
昨天的文章:年化24.9%:基于动量、波动率、乖离率的多因子合成策略的指数轮动。(代码+数据下载)
今天继续优化,希望通过择时来改善最大回撤,尝试了几种方式,效果有限。
比如,当“20日动量小于0时”,则卖出,由于我们后续还有排序规则,所以,相当于我们是对选择的标的做了一层过滤,就是20日动量为负时不持仓。
收益变少了(长期年化18.2%),回撤并没有明显改善。
————这里我的分析逻辑如下:我们的综合分,已经考虑到动量因素,中短期动量,波动率,乖离率,若是我们再使用动量来过滤,那么可能把评分高的滤掉,被评分低的取而代之,因为并没有起来改善性能的效果。
这也是我为什么一直考虑轮动、机器排序模型的原因。量化择时太难,预测市场太难。你要问,不预测量化做什么呢?——按概率选择“相对更好”的。就是我们并不知道市场下一步怎么走,但我们会知道,A比B相对更好,长期这样选择,结果一定不会差。
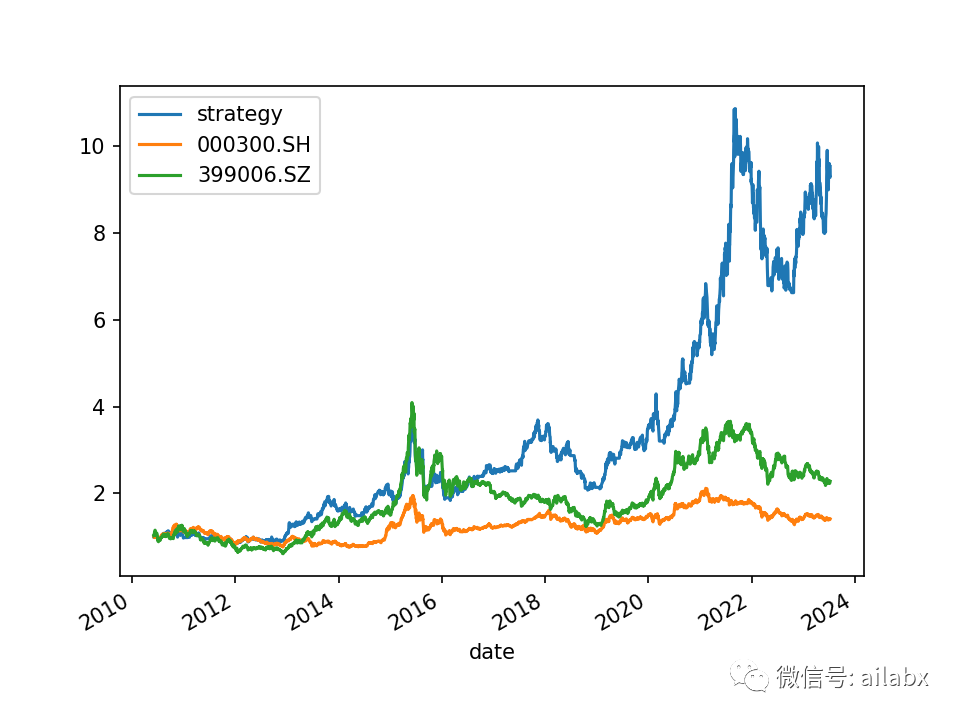

from engine.datafeed.dataloader import Hdf5Dataloader from engine.env import Env from engine.algo import * from engine.config import DATA_H5 from engine.config import etfs_indexes loader = Hdf5Dataloader(etfs_indexes.values(), start_date="20100101") fields = ['roc(close,20)', 'std(volume,20)','bias(close,20)', 'roc(close,5)', 'std(volume,5)','bias(close,5)', 'rank(roc_20)+rank(bias_20)+rank(roc_5)+rank(bias_5)-rank(std_20)-rank(std_5)'] names = ['roc_20', 'std_20','bias_20', 'roc_5', 'std_5','bias_5', 'rank'] df = loader.load(fields=fields, names=names) e = Env(df=df, benchmarks=['000300.SH', '399006.SZ']) e.set_algos([ RunDays(days=10), RunWeekly(), SelectAll(), SelectBySignal(buy_rules=[], sell_rules=['ind(roc_20)<-0']), SelectTopK(drop_top_n=1, K=2, order_by='rank', b_ascending=False), #PickTime() WeightEqually() ]) e.backtest_loop() e.show_results() # e.save_results()
接下来,我们考虑一下大盘择时:
比如创业板的RSRS因子,年化20.7%,最大回撤26%。有明显的超额收益,而且有效控制了回撤,在2015年牛熊转换其间保住了大部分收益。
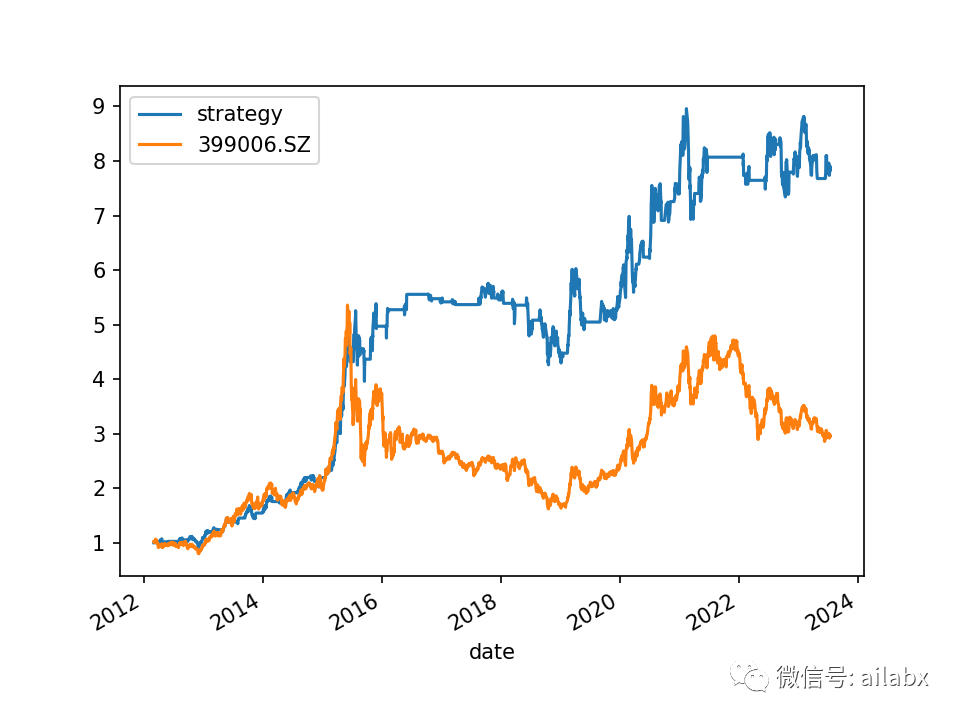
from engine.datafeed.dataloader import Hdf5Dataloader symbols = ['399006.SZ'] loader = Hdf5Dataloader(symbols, start_date="20120101") df = loader.load(fields=['slope_pair(high,low,18)', 'zscore(rsrs_18,600)'], names=['rsrs_18', 'zscore']) from engine.env import Env from engine.algo.algos import * from engine.algo.algo_weights import * bench_loader = Hdf5Dataloader(['399006.SZ'], start_date='20120101') e = Env(df, name='创业板RSRS择时', benchmarks=bench_loader.load()) e.set_algos([ #RunMonthly(), SelectBySignal(buy_rules=['ind(zscore)>0.7'], sell_rules=['ind(zscore)<-0.7']), WeightEqually() ]) e.backtest_loop() e.show_results(plot=True) # e.save_results()
指数多因子改进后:年化27.7%,夏普大于1。
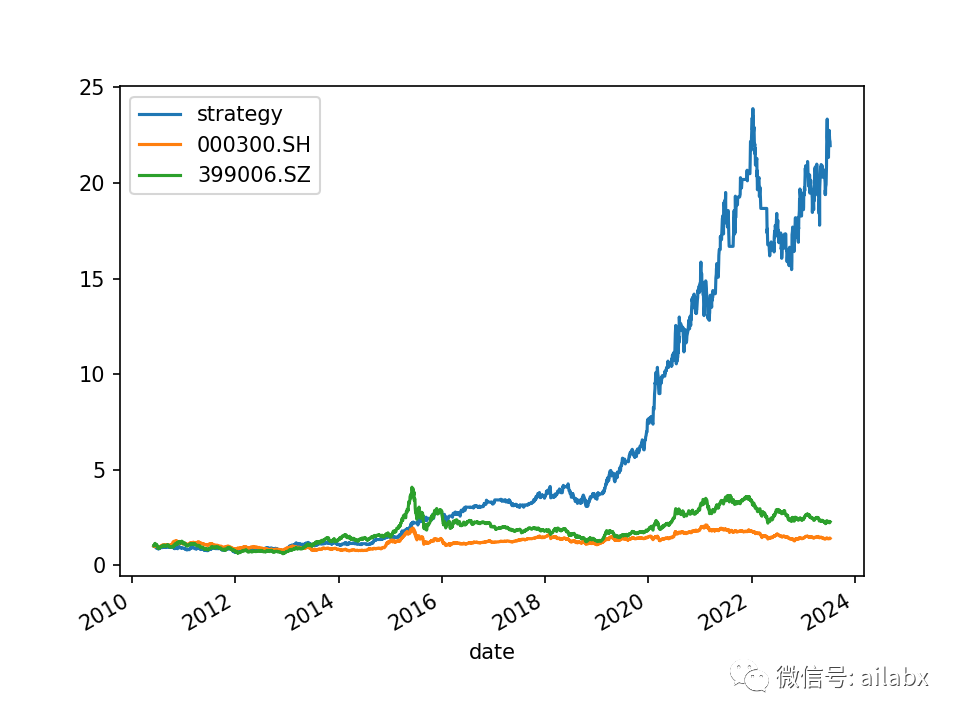
from engine.datafeed.dataloader import Hdf5Dataloader from engine.env import Env from engine.algo import * from engine.config import DATA_H5 from engine.config import etfs_indexes loader = Hdf5Dataloader(etfs_indexes.values(), start_date="20100101") fields = ['roc(close,20)', 'std(volume,20)', 'bias(close,20)', 'roc(close,5)', 'std(volume,5)', 'bias(close,5)', 'rank(roc_20)+rank(bias_20)+rank(roc_5)+rank(bias_5)-rank(std_20)-rank(std_5)'] names = ['roc_20', 'std_20', 'bias_20', 'roc_5', 'std_5', 'bias_5', 'rank'] df = loader.load(fields=fields, names=names) bench_loader = Hdf5Dataloader(['399006.SZ', '000300.SH']) e = Env(df=df, benchmarks=bench_loader.load(fields=['slope_pair(high,low,18)', 'zscore(rsrs_18,600)<-0.7'], names=['rsrs_18', 'zscore'])) e.set_algos([ # RunDays(days=10), RunWeekly(), # SelectAll(), # SelectBySignal(buy_rules=[], sell_rules=['ind(roc_20)<-0']), SelectTopK(drop_top_n=1, K=1, order_by='rank', b_ascending=False), PickTime(benchmark='399006.SZ', signal='zscore'), PickTime(benchmark='000300.SH', signal='zscore'), WeightEqually() ]) e.backtest_loop() e.show_results() # e.save_results()
再做一些优化,考虑上实盘。
今天代码的重点,在昨天基础上,加上了大盘择时,当大盘的RSRS指数为-0.7时,清空仓位。风险、收益均得到了不小的提升。
代码已经发布。知识星球与开源项目:万物之中,希望至美
闲庭独坐对闲花,
轻煮时光慢煮茶,
不问人间烟火事,
任凭岁月染霜华。财富自由的生活
你写PPT时,阿拉斯加的鳕鱼正跃出水面;
你看报表时,梅里雪山的金丝猴刚好爬上树尖;
你挤进地铁时,西藏的山鹰一直盘旋云端;
你在会议中吵架时,尼泊尔的背包客一起端起酒杯坐在火堆旁。
有一些穿高跟鞋走不到的路,有一些喷着香水闻不到的空气,有一些在写字楼里永远遇不见的人。
人工智能现在还不能自主参与投资,但若你本身会投资,又懂得借力人工智能,你将无往而不利。

这段时间有不少读者留言,说想进一步沟通与交流。之前维护过微信群,不是一种好的沟通方式,再加上现在还有开源项目,我估计大家想问的问题会更多。
做知识星球的初心:以实战、盈利为导向,开发可持续的策略和平台。
市场覆盖:ETF、可转债、股票、期货和数字货币。
项目100%对星友开源,持续维护和升级。
所以,如果大家理念一致,或者有任何问题,意见或建议,可以到星球找我,每天都在。
在这里希望你学会投资,而且学会人工智能技术。
小结
七年之约,只是开始。
践行长期主义。
万物之中,希望至美。
人工智能与金融投资,都是长坡厚雪,且还是为数不多,可以满足个人英雄主义情结的地方。
走,一起赶路吧。
原创文章第269篇,专注“个人成长与财富自由、世界运作的逻辑与投资“。
很多星友关心的问题,这里统一回复,星球的初心就是策略研究。
回归策略研究本身,GUI可视化是辅助工具。策略研究是基于数据的,数据还是要基于可视化的。所以我们需要低成本的实现一个界面,这就是我们折腾GUI的原因。
AI量化无外乎:数据、因子、策略(规则)、回测、评价、迭代。
数据在本地我们统一使用hdf5,去掉之前的csv。
使用notebook下的data_viewer可以查看数据库里的数据。
我们把所有的daily_quotes数据都统一存储在data.h5里,使用symbol统一访问,包括指数数据,etf数据,可转债数据,股票数据等。


基于统一的数据存储,我把以前的策略都“刷新”了一下:
大小盘轮动策略:(年化14.6%)


代码如下(已在星球更新):
from engine.datafeed.dataloader import Hdf5Dataloader from engine.env import Env from engine.algo import * start_date = '20110101' loader = Hdf5Dataloader(['399006.SZ', '000300.SH'], start_date=start_date) df = loader.load(fields=['close/shift(close,20)-1'], names=['roc_20']) bench_loader = Hdf5Dataloader(['000300.SH', '399006.SZ'], start_date=start_date) e = Env(name='roc_20_index', df=df, benchmarks_df=bench_loader.load()) e.set_algos([ RunWeekly(), # SelectAll(), SelectBySignal(buy_rules=['ind(roc_20)>0.08'], sell_rules=['ind(roc_20)<-0']), SelectTopK(K=1, order_by='roc_20'), WeightEqually() ]) e.backtest_loop() e.show_results()
大类资产-风险平价(季度再平衡,长期年化7%):


策略代码如下:
from engine.env import Env from engine.algo.algo_weights import * from engine.algo.algos import * indexes = [ 'HSI', 'SPX', 'GDAXI', 'N225', '000300.SH', ] from engine.datafeed.dataloader import Hdf5Dataloader loader = Hdf5Dataloader(indexes, start_date="20100101") df = loader.load() bench_loader = Hdf5Dataloader(['000300.SH', 'SPX'], start_date='20100101') e = Env(df, benchmarks=bench_loader.load()) e.set_algos([ RunQuarterly(), SelectAll(), WeightRP() ]) e.backtest_loop() e.show_results()
回测就是在特定的universe时,去找相应有效的因子,然后按规则,或者使用机器学习模型进行拟合(预测)。
针对行业指数,我们计算几个因了,除了之前的N日动量之外:
N天成交额的波动率:
def std(se, N): return se.groupby('symbol', group_key=False).apply(lambda x: rolling(se, N, 'std'))
因子表达式:std(volume,20)
N天BIAS:BIAS指标的计算逻辑为收盘价与移动平均线之间的差距。
def bias(se: pd.Series, N): def _bias(se: pd.Series, N): return se / se.rolling(window=N).mean() return se.groupby('symbol', group_keys=False).apply(lambda x: _bias(x, N))
准备好的指标,写策略就很容易了:
策略逻辑,3个指标:N天动量,N天交易额波动率,N天乖离率。(N=5,20)。
因子合成,6个因子排名等权合成为一个Rank因子,按因子值倒排,择优轮动。
看下效果(年化24.9%):

from engine.datafeed.dataloader import Hdf5Dataloader from engine.env import Env from engine.algo import * from engine.config import DATA_H5 from engine.config import etfs_indexes loader = Hdf5Dataloader(etfs_indexes.values(), start_date="20100101") fields = ['roc(close,20)', 'std(volume,20)','bias(close,20)', 'roc(close,5)', 'std(volume,5)','bias(close,5)', 'rank(roc_20)+rank(bias_20)+rank(roc_5)+rank(bias_5)-rank(std_20)-rank(std_5)'] names = ['roc_20', 'std_20','bias_20', 'roc_5', 'std_5','bias_5', 'rank'] df = loader.load(fields=fields, names=names) e = Env(df=df, benchmarks=['000300.SH', '399006.SZ']) e.set_algos([ RunDays(days=10), RunWeekly(), SelectAll(), # SelectBySignal(buy_rules=['ind(roc_20)>0.08'], sell_rules=['ind(roc_20)<-0']), SelectTopK(K=3, order_by='rank', b_ascending=False), #PickTime() WeightEqually() ]) e.backtest_loop() e.show_results() e.save_results()
明天基于市场择时再做优化,主要是优化回撤。
代码和数据已经更新至星球,请大家请往下载。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104070
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!