
开始之前,晒一下AI大佬镇镇场子。
我想最不被仇富,最有成就感,calling的目标,应该是突破前沿科技,给全人类带来福祉,然后通过资本市场(一级市场股权,期权)获得超级财富。
比如如下这位,openAI的CEO山姆.奥特曼。



之前我们写过gplearn,但是内置了一个向量化的回测引擎。
gplearn在期货和多支股票上因子挖掘实战的代码(代码+数据下载)
年化167%,夏普比大于7:基于gplearn的股指期货的高频因子挖掘
我们需要把gplearn整合到quantlab3.0中去。
多因子挖掘是量化的未来,因子挖掘可以贯穿quant2.0-3.0的全过程。
之前我们梳理过:Quantlab3.0进展,结合Quant4.0的思考:全自动,可解释AI量化是未来
Quant 2.0:将量化的研究模式从小型的天才工坊因子流水线。Quant2.0主要是挖因子,在股票和期货市场的私募里已经比较流行。
gplearn等自动挖掘因子的工具基本是标配:gplearn在期货和多支股票上因子挖掘实战的代码(代码+数据下载)。
Quant3.0:Quant 3.0更注重深度学习建模。在使用相对简单的因子下,深度学习仍然有潜力通过其强大的端到端学习能力和灵活的模型拟合能力。深度学习需要大量的数据。
咱们在DeepAlphaGen里有尝试过端到端的因子合成:端到端因子挖掘框架:DeepAlphaGen V1.0代码发布,支持最新版本qlib。
gplearn原本是用于符号拟合:
比如下面的代码:y= cos(x1)-sin(x2)
# 此文档将简要说明gplearn的使用方法 import numpy as np import pandas as pd from gplearn import fitness from gplearn.genetic import SymbolicRegressor from datetime import datetime def score_func_basic(y, y_pred, sample_weight, **args): # 适应度函数:策略评价指标 return sum((pd.Series(y_pred) - y) ** 2) # 这里是最小化残差平方和 m = fitness.make_fitness(function=score_func_basic, # function(y, y_pred, sample_weight) that returns a floating point number. greater_is_better=False, # 上述y是输入的目标y向量,y_pred是genetic program中的预测值,sample_weight是样本权重向量 wrap=False) # gplearn.fitness.make_fitness(function, greater_is_better, wrap=True) cmodel_gp = SymbolicRegressor(population_size=500, # 每一代公式群体中的公式数量 500 generations=10, # 公式进化的世代数量 10 metric=m, # 适应度指标,这里是前述定义的通过 大于0做多,小于0做空的 累积净值/最大回撤 的评判函数 tournament_size=50, # 在每一代公式中选中tournament的规模,对适应度最高的公式进行变异或繁殖 50 function_set=('add', 'sub', 'mul', 'abs', 'neg', 'sin', 'cos', 'tan'), # 用于构建和进化公式使用的函数集 const_range=(-1.0, 1.0), # 公式中包含的常数范围 parsimony_coefficient='auto', # 对较大树的惩罚,默认0.001,auto则用c = Cov(l,f)/Var( l), where Cov(l,f) is the covariance between program size l and program fitness f in the population, and Var(l) is the variance of program sizes. # stopping_criteria=100.0, # 是对metric的限制(此处为收益/回撤) init_depth=(2, 4), # 公式树的初始化深度,树深度最小2层,最大6层 init_method='half and half', # 树的形状,grow生分枝整的不对称,full长出浓密 p_crossover=0.2, # 交叉变异概率 0.8 p_subtree_mutation=0.2, # 子树变异概率 p_hoist_mutation=0.2, # hoist变异概率 0.15 p_point_mutation=0.2, # 点变异概率 p_point_replace=0.2, # 点变异中每个节点进行变异进化的概率 max_samples=1.0, # The fraction of samples to draw from X to evaluate each program on. feature_names=None, warm_start=False, low_memory=False, n_jobs=1, verbose=1, random_state=0 ) if __name__ == '__main__': start = datetime.now() LenD = 1000 X1 = pd.DataFrame(data={'a': range(LenD), 'b': np.random.randint(-10, 10, LenD)}) Y1 = X1.sum(axis=1) # .values print("初始策略是Y1=X1.sum(axis=1)") cmodel_gp.fit(X1, Y1) print(cmodel_gp) print("------------------------------------------------------------------------------------") print(" ") print(" ") print(" ") print(" ") print(" ") print(" ") print("------------------------------------------------------------------------------------") LenD = 1000 X2 = pd.DataFrame(data={'a': range(LenD), 'b': np.random.randint(0, 10, LenD)}) Y2 = np.cos(X2['a']) - np.sin(X2['b']) cmodel_gp.fit(X2, Y2) print(cmodel_gp) print("------------------------------------------------------------------------------------") end = datetime.now() elapsed = end - start print("Time elapsed:", elapsed)
经过几轮迭代,可以生成表达式。
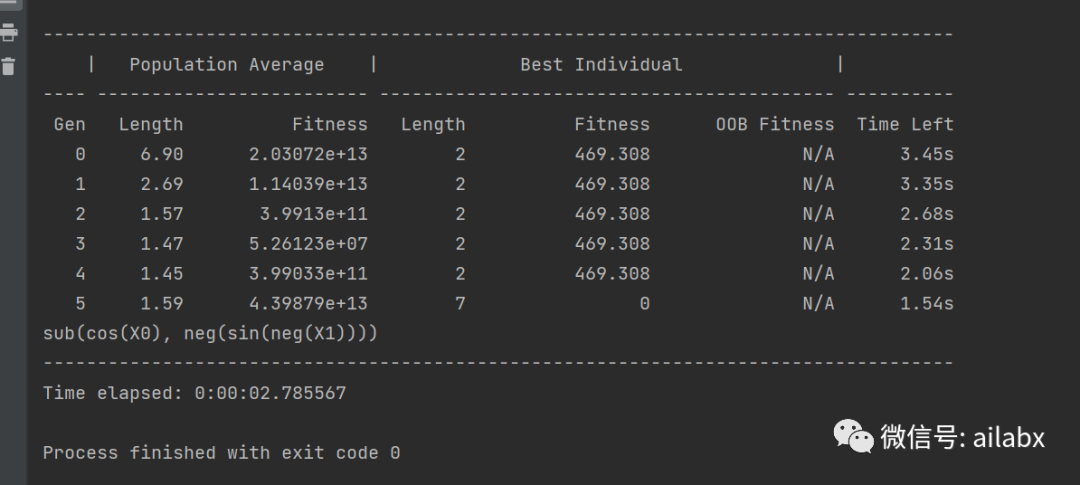
这个机制天然适合我们挖掘因子,只需要换上合适的fitness即可。
针对期货的分钟线,我们来挖掘因子,并计算因子值:
import pandas as pd import numpy as np from gplearn import fitness from gplearn.genetic import SymbolicRegressor train_data = pd.read_csv('../backtesting/test/IC_train.csv', index_col=0, parse_dates=[0]) feature_names = list(train_data.columns) train_data.loc[:,'y'] = np.log(train_data['Open'].shift(-4)/train_data['Open'].shift(-1)) # 对数收益率 train_data.dropna(inplace = True) print(train_data) def my_gplearn(function_set, score_func_basic, pop_num=100, gen_num=3, tour_num=10, random_state = 42, feature_names=None): # pop_num, gen_num, tour_num的几个可选值:500, 5, 50; 1000, 3, 20; 1000, 15, 100 metric = fitness.make_fitness(function=score_func_basic, # function(y, y_pred, sample_weight) that returns a floating point number. greater_is_better=True, # 上述y是输入的目标y向量,y_pred是genetic program中的预测值,sample_weight是样本权重向量 wrap=False) # 不保存,运行的更快 # gplearn.fitness.make_fitness(function, greater_is_better, wrap=True) return SymbolicRegressor(population_size=pop_num, # 每一代公式群体中的公式数量 500,100 generations=gen_num, # 公式进化的世代数量 10,3 metric=metric, # 适应度指标,这里是前述定义的通过 大于0做多,小于0做空的 累积净值/最大回撤 的评判函数 tournament_size=tour_num, # 在每一代公式中选中tournament的规模,对适应度最高的公式进行变异或繁殖 50 function_set=function_set, const_range=(-1.0, 1.0), # 公式中包含的常数范围 parsimony_coefficient='auto', # 对较大树的惩罚,默认0.001,auto则用c = Cov(l,f)/Var( l), where Cov(l,f) is the covariance between program size l and program fitness f in the population, and Var(l) is the variance of program sizes. stopping_criteria=100.0, # 是对metric的限制(此处为收益/回撤) init_depth=(2, 3), # 公式树的初始化深度,树深度最小2层,最大6层 init_method='half and half', # 树的形状,grow生分枝整的不对称,full长出浓密 p_crossover=0.8, # 交叉变异概率 0.8 p_subtree_mutation=0.05, # 子树变异概率 p_hoist_mutation=0.05, # hoist变异概率 0.15 p_point_mutation=0.05, # 点变异概率 p_point_replace=0.05, # 点变异中每个节点进行变异进化的概率 max_samples=1.0, # The fraction of samples to draw from X to evaluate each program on. feature_names=feature_names, warm_start=False, low_memory=False, n_jobs=1, verbose=1, random_state=random_state) # 生成因子 # 函数集 function_set=['add', 'sub', 'mul', 'div', 'sqrt', 'log', # 用于构建和进化公式使用的函数集 'abs', 'neg', 'inv', 'sin', 'cos', 'tan', 'max', 'min', # 'if', 'gtpn', 'andpn', 'orpn', 'ltpn', 'gtp', 'andp', 'orp', 'ltp', 'gtn', 'andn', 'orn', 'ltn', 'delayy', 'delta', 'signedpower', 'decayl', 'stdd', 'rankk' ] # 最后一行是自己的函数,目前不用自己函数效果更好 def score_func_basic(y, y_pred, sample_weight): # 因子评价指标 try: _ = bt.run_(factor=y_pred) factor_ret = _['annualized_mean']/_['max_drawdown'] if _['max_drawdown'] != 0 else 0 # 可以把max_drawdown换成annualized_std except: factor_ret = 0 return factor_ret factor_num = 1 # 因子编号 my_cmodel_gp = my_gplearn(function_set, score_func_basic, random_state=0, feature_names=feature_names) # 可以通过换random_state来生成不同因子 my_cmodel_gp.fit(train_data.loc[:, :'rank_num'].values, train_data.loc[:, 'y'].values) print(my_cmodel_gp) test_data = pd.read_csv('../backtesting/test/IC_test.csv', index_col=0, parse_dates=[0]) factor = my_cmodel_gp.predict(test_data.values) print(factor)
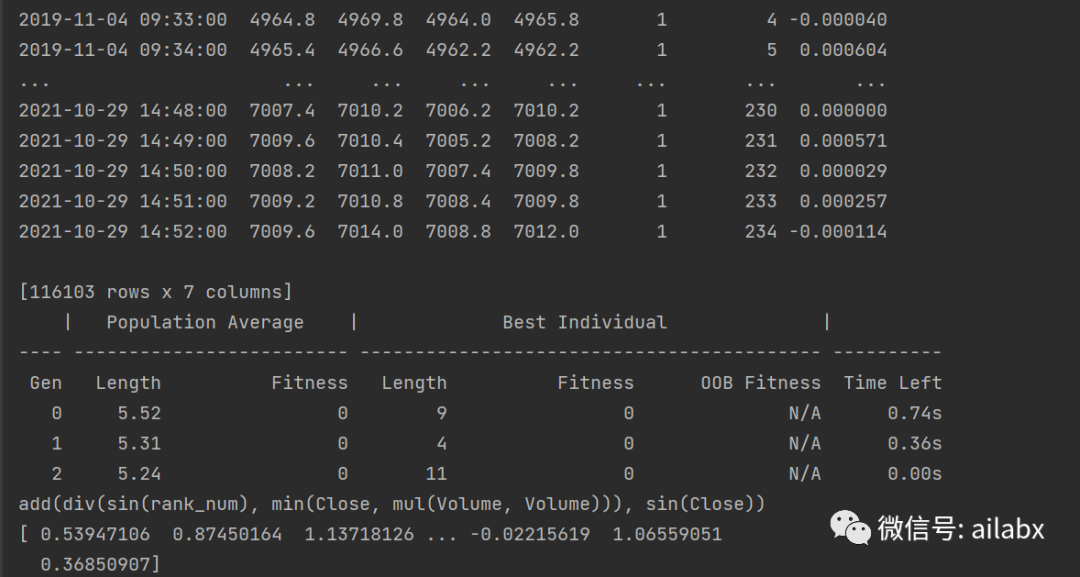
有了因子值,我们明天把因子值输入到咱们quant3.0的系统里直接回测。
代码与数据下载:
吾日三省吾身
给大家分享一下最近的学习心得。
斯多葛学派的“二分法”在很多地方都很有用。
做好你能掌控的,比如关于成长和成功。让你自己成长,多读书,深度思考,这是自己能掌控去做的。而成功,受限于外部很多因素,比如运气,遇到的人,时代的趋势等。
按老话说的——“但行好事,莫问前程”。
2023就要结束了,总结这一年,展望下一年。
在“成长与财富自由【星球优惠券】AI量化实验室&个人成长与财富自由践行社”里,给大家分享我的新年的“ABCZ”人生计划之”ABCZ”计划。
终于把C计划给补齐了。
之前一直在犹豫,C计划的思考方向是金融,历史,“用金融视角看世界底层逻辑”之类的命题。就点像宋鸿兵后来做的事情,或者卢克文写的一些东西。
加入过卢克文的星球,如下全球热点做的剖析,不知对错,但内容确实很丰富——可是除了茶余饭后的谈资,这些内容的价值?
——尽管说不必要事事都“功利主义”。
但如果要作为年度核心规划方向,需要一个“calling”(有召唤感)的目标。
后来我想到这个目标应该是“LLM-AGI”。
个人身上的标签一直是“技术”,“逻辑”。一个好朋友说“科学家”——这个还不太敢当。
好朋友问我,为何想做“金融”。——可能需要“祛魅”吧。
年轻时,其实最大的红利是互联网公司的期权,但“一山望那山高”,觉得像麦肯锡这样的咨询公司——现在都很少听说了——后来想象中的基金经理的千万年薪。。。
金融不是强逻辑,甚至谈不上严格的科学,否则牛顿老爵爷就不必感慨——可以计算天体的运动,却无法计算人性的疯狂。
当然金融有其意义,资金配置到最有效率的地方去。
而量化的底色是投机,你要找价值,那就是“价值发现”,给市场提供流动性吧。
有通过投机赚了大钱的大佬,也会陷入虚空,而后投身于科学。
科学可以实实在在为人类进步,而来巨大的福祉。
能做为“终身事业”的目标,应该是:“能参与进去”,”为人类社会有巨大价值“。对个人有意义,对社会有意义。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103597
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!