
这个也是承诺给同学们好久,我们一直在探索前沿技术,但前沿技术是没有尽头的,我们仍然会持续关注。
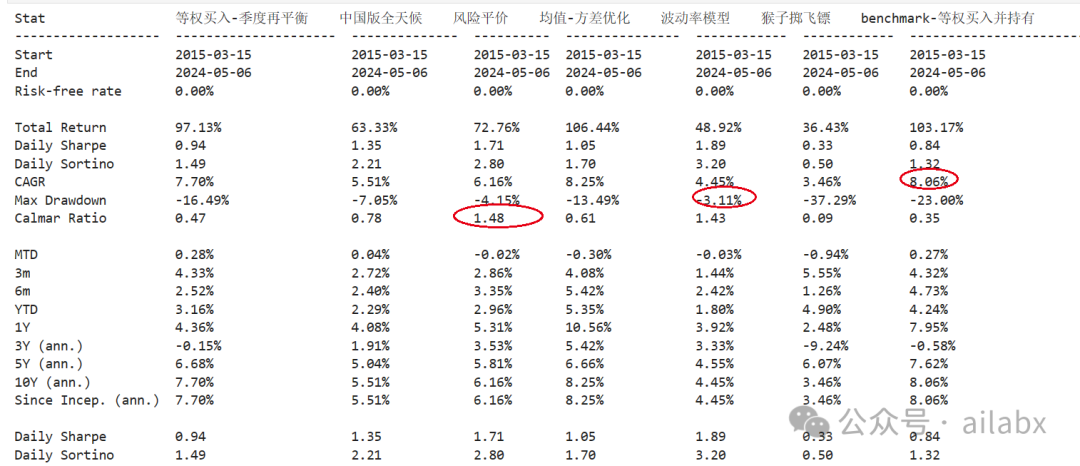
大类资产配置类,实现七个策略,回测结果如下:


大类资产配置分析:
从卡玛比率看(综合风险收益之后),风险平价最优,甚至优于中国版的全天候(毕竟参数会随时间变化),但其实差不多。
回撤率看,波动率模型最小。
收益率看,等权买入最佳,但回撤率达到23%。
策略代码如下:
# 创建一个策略,等权买入,季度再平衡 # 这就是我非常喜欢这个框架的原因,这个代码很容易读懂,且不会出错。 s_equally = bt.Strategy('等权买入-季度再平衡', [ bt.algos.RunQuarterly(), bt.algos.SelectAll(), bt.algos.WeighEqually(), bt.algos.Rebalance()]) weights = { '159928':0.03, # 消费ETF '510050':0.06,# 上证50ETF '512010':0.08,# 医药ETF '513100':0.05,# 纳指ETF '518880':0.1,# 黄金ETF '511220':0.32,# 城投债ETF '511010':0.26,# 国债ETF '161716':0.1,# 招商双债ETF } s_fix = bt.Strategy('中国版全天候', [ bt.algos.RunQuarterly(), bt.algos.SelectAll(), bt.algos.WeighSpecified(**weights), bt.algos.Rebalance()]) s_erc = bt.Strategy('风险平价', [ bt.algos.RunAfterDays(20*6 + 1), bt.algos.RunQuarterly(), bt.algos.SelectAll(), bt.algos.WeighERC(), bt.algos.Rebalance()]) s_mvo = bt.Strategy('均值-方差优化', [ bt.algos.RunAfterDays(20*6 + 1), bt.algos.RunQuarterly(), bt.algos.SelectAll(), bt.algos.WeighMeanVar(), bt.algos.Rebalance()]) s_vol = bt.Strategy('波动率模型', [ bt.algos.RunAfterDays(20*6 + 1), bt.algos.RunQuarterly(), bt.algos.SelectAll(), bt.algos.WeighInvVol(), bt.algos.Rebalance()]) s_randomly = bt.Strategy('猴子掷飞镖', [ bt.algos.RunQuarterly(), bt.algos.SelectAll(), bt.algos.WeighRandomly(), bt.algos.Rebalance()]) s_bench = bt.Strategy("benchmark-等权买入并持有",[ bt.algos.RunOnce(), bt.algos.SelectAll(), bt.algos.WeighEqually(), bt.algos.Rebalance()]) s_list = [s_equally, s_fix, s_erc, s_mvo,s_vol, s_randomly,s_bench] bkts = [bt.Backtest(s, df, progress_bar=True) for s in s_list] res = bt.run(*bkts)
大类资产配置,在选择好战略资产候选集后,一般不再需要选股,因此使用SelectAll全选所有。大类资产配置的调仓周期一般较长,比如每季度调仓一次即可,因些使用RunQuarterly。重点是Weigh仓位管理。
风险平价在大类资产配置里确实是有效的。
代码与数据请前往星球下载:
吾日三省吾身
焦虑不安有时也未必完全是坏事。
好比小的伤病会激发人体的免疫系统一般。
之前分享过人生计划之”ABCZ”,这个仍然是周期波动,不确定时代,个人人生之总纲。
“七年一辈子”是个人特别喜欢的一个概念。
昨天说被误解的“运气动力学”,成功与财富自由,人生可以过差不多11辈子,前面几辈子可能没有得到特别大的运气加持,也没关系,来得及。人生永远有的选。
普通人家的孩子晚熟。——不要相信所谓“穷人的孩子早当家”。当家吃的那些苦,在现实世界并不能支持你去赢,只是支撑着你活下去罢了。
35岁左右,而立而不立,上有老下有小,少年轻狂不在,痛定思痛,有一部分人反思,觉醒,改变。
但来得及。
回顾一下“上辈子”,2017-2024,挺有意思。
2017年,正好35岁,有了孩子,家庭,责任;工作上了台阶,但管理岗位很少了,需要的综合素质也更高了。收获不少,但回归到ABCZ而言,前3年完成Z计划0-1的摸索,试水。后3年完成Z计划建仓,实战,目前基本完成,不需要花太多时间。
同时在后3年里,开始B计划的试水,尝试。目前完成从0-1或者说1-10的探索,找到一点感觉。后三年希望完成B计划的管道化,同时完成C计划的探索与从0到1。
大家看出来没有,七年一辈子,用“一辈子”去完成一件事情,同时还花20%的精力开始布局下一辈子。
”N阶行动计划“是我喜欢的另一个概念:1000天也就是3阶(10的三次方),完成一件事,布局一件事。这让你目前长远。多少事情,往前看三年,往后想三年,都是小事。什么争吵,矛盾,职场斗争都不是事。
100天(三个月,10的2次方)做具体计划,完成一个个阶段小目标。行动计划按季度做就好了。
(Z计划稳定运行中)下一个三年计划(下个半辈子):
A计划稳中求进,以稳为主。
B计划花三年时间管道化。
C计划在同一个三年从0到1(做一个研究者,学富五车,自由随心)。
尽管bt框架内置了不少算子,但扩展自己的算子,才是我们掌握了这个框架的标志。这意味着我们真正可以驾驭这个框架,实现咱们想实现的功能。
实现算子并不复杂,但要设计出一个良好的可复用的算子,还是需要花点心思。
框架内置的SelectMomentum算子,按N天的收益率(动量)对标的进行从大到小排序,取前N个。这个算子在轮动策略中非常有效。
在这个不够灵活,我们希望可以传入任何信号(Siganl),都可以进行排序。
我们看下源代码里SelectMomentum的实现:
它继承了AlgoStack,然后初始化的时候,传入StatTotalReturn和SelectN两个算子,搞定。
这就是代码复用的力量。
class SelectHolding(bt.Algo):
def __init__(self):
pass
def __call__(self, target):
holding = []
if target.now in target.positions.index:
sig = target.positions.loc[target.now] > 0
se_pos = sig[sig == True].index # noqa: E712
universe = target.universe.loc[target.now, list(se_pos)].dropna()
holding = list(universe[universe > 0].index) if 'selected' not in target.temp.keys(): return True # 如果前而有selected,则加上当前持仓。 selected = target.temp['selected'] selected = list(set(selected + holding)) target.temp['selected'] = selected return True
其中StatTotalReturn这个算子计算当前所有标的收益率,缓存在target.temp[‘stat’]中;SelectN读取这个stat中的值,对标的进行排序,取最大的前N个。
class SelectMomentum(AlgoStack): def __init__( self, n, lookback=pd.DateOffset(months=3), lag=pd.DateOffset(days=0), sort_descending=True, all_or_none=False, ): super(SelectMomentum, self).__init__( StatTotalReturn(lookback=lookback, lag=lag), SelectN(n=n, sort_descending=sort_descending, all_or_none=all_or_none), )
一个极简的,根据信号从大到小排序的算子实现如下:
Signal可以是信号的dataframe,也可以是变量字符串;K就是取前N个。
class SelectTopK(bt.AlgoStack):
def __init__(self, signal, K):
super(SelectTopK, self).__init__(bt.algos.SetStat(signal), bt.algos.SelectN(K))
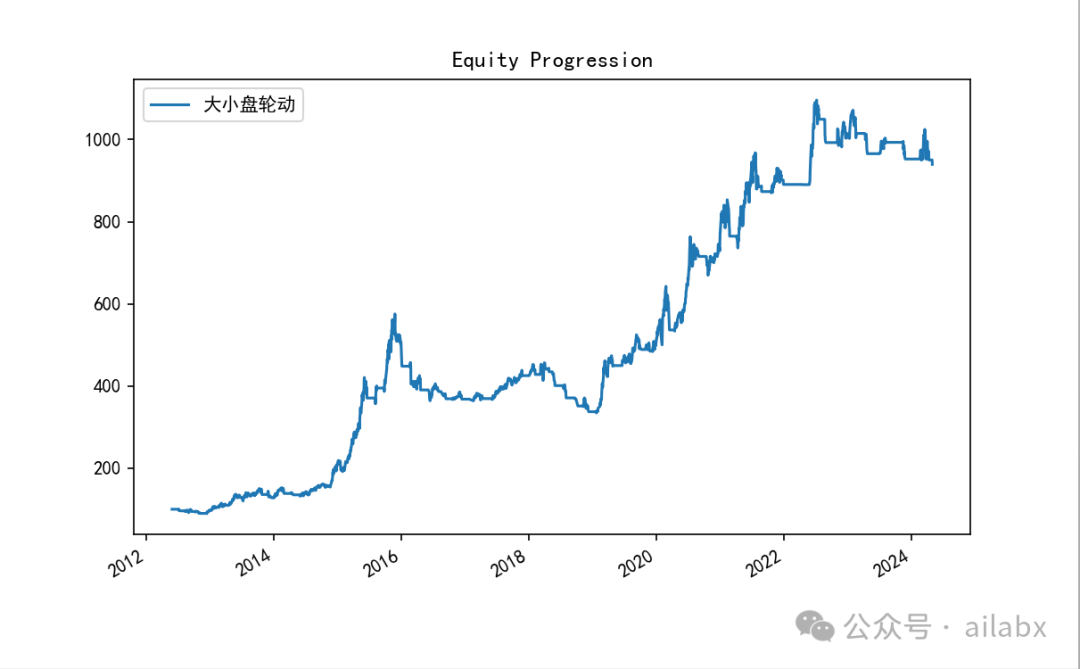
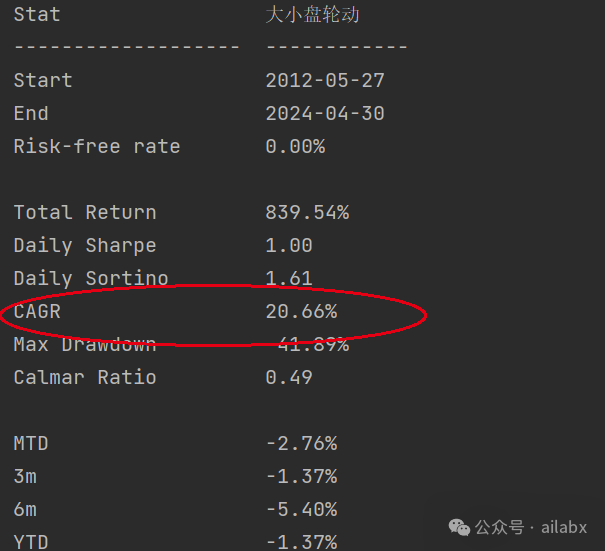
代码同步在星球下,请大家自取:

吾日三省吾身
昨天的文章,几个反思点: 生产有长期价值的产品。
这个不确定的时代,你无法规划长远,但不意味着你无所作为。而是说计划赶不上变化,临渊羡鱼,不如退而结网,当下看到——有生产长期价值产品的机会,干就是了。——也许这就是局部最优,但没关系,没有人真的可以看到所谓的全局最优。——机器学习的搜索算法也是如此。
若你仍想思考更长期的未来。
不是你想过什么样的生活,这个太容易,太廉价,谁不想权倾天下,富可敌国?周游列国,结交名仕。
把“我想要”,换成“我能给”。
芒格说,“得到一件想要的东西最好的办法,就是想办法配得上它”。
你要想,什么样的能力和付出,配过这样的生活。
这个社会,本质就是价值交换,你想得到什么,取决你能拿什么东西来换。
80%的精力做当下最优,能产出阶段产品的事情。
20%的精力随兴趣漫游,尝试各种新事情,积极拥抱各种可能性。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103399
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!