
【代码发布】Quantlab4.3:lightGBM应用于全球大类资产的多因子智能策略(代码+数据)
"""模型保存"""
from config import DATA_DIR
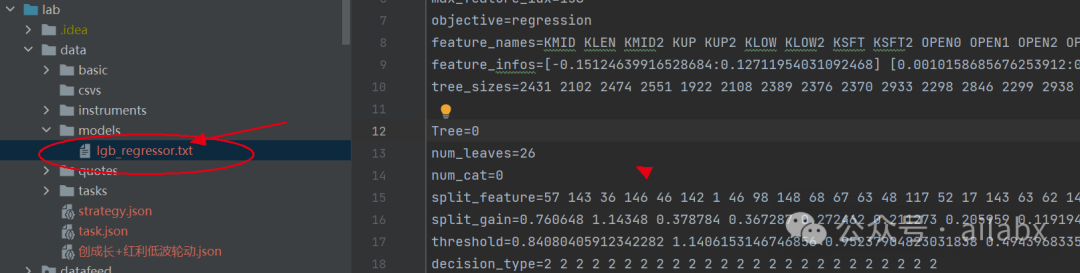
model.booster_.save_model(DATA_DIR.joinpath('models').joinpath('lgb_regressor.txt'))
在昨天代码的基础上,加一行代码,即可以把训练好的模型保存到本地。
其实就是一些参数,可以直接保存成txt的格式,可以打开来查开。

现在我们可以通过加载特定的模型来回测(暂时先不考虑WFA,也就是先不考虑滚动训练)。
加载已经训练的模型如下:
def load_model(model_name):
from config import DATA_DIR
import lightgbm as lgb
model = lgb.Booster(model_file=DATA_DIR.joinpath('models').joinpath(model_name).resolve()) return model
这是机器学习预测的效果:
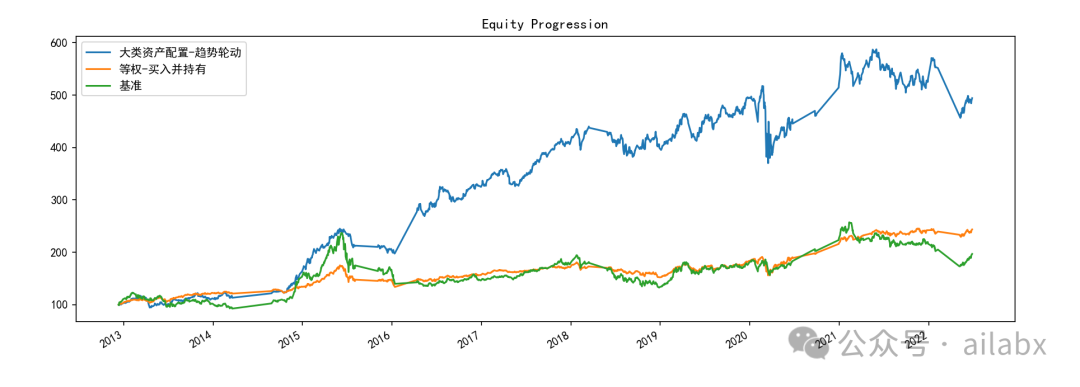
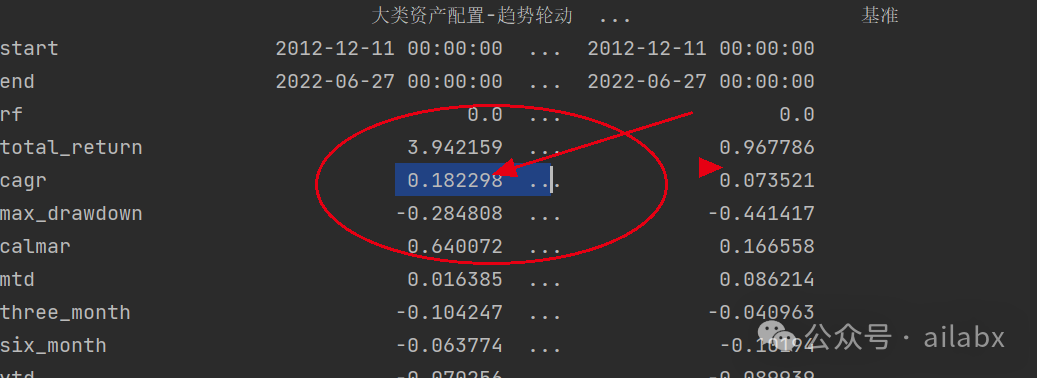
新增模型加载与预测的代码:
df = CSVDataloader(config.DATA_DIR_QUOTES.resolve(), symbols=task.symbols, start_date=task.start_date).load( task.features, task.feature_names) del df['amount'] df.dropna(inplace=True) if task.model_name: df['pred'] = model.predict(df[task.feature_names]) #df['pred']=df.groupby('symbol', group_keys=False).apply(lambda x: calculate_pred(x, task.feature_names, model)) s = bt.Strategy(task.name, task.get_algos(df)) s_bench = bt.Strategy('等权-买入并持有', [ bt.algos.SelectAll(), bt.algos.WeighEqually(), bt.algos.Rebalance(), ])
吾日三省吾身
生活中,有些事情,不必急——关键是急也没有用。
日子就是这么一天天过。
有些事情结束,有新的事情开始。
也许有意外,也会有惊喜。
不确定性构成新常态。
认真地活在当下,过好每一个当下。
关心自己可以掌控的事情。
其余的事情,允许一切发生的心态。
今天,需要先 pip install lightgbm。
之前我们有分享过类似的文章:
Quantlab3.3代码发布:全新引擎 | 静态花开:年化13.9%,回撤小于15% | lightGBM实现排序学习
今天我们要把lightgbm应用于全球大类资产配置的排序上。
-
处理大规模数据:量化投资经常涉及到处理大量的历史交易数据和其他市场数据。LightGBM 能够有效地处理这些数据,并从中学习。
-
快速模型训练:量化策略需要快速迭代和测试。LightGBM 的训练速度使得研究人员能够快速评估不同策略的效果。
-
模型解释性:虽然不是 LightGBM 的主要优势,但决策树模型的可解释性可以帮助量化分析师理解模型的决策过程,这对于合规性和策略调整非常重要。
"""第三方库导入""" from lightgbm import LGBMRegressor from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.metrics import r2_score, mean_squared_error from sklearn.datasets import fetch_california_housing data = fetch_california_housing() """训练集 验证集构建""" X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42) """模型训练""" model = LGBMRegressor() model.fit(X_train, y_train) def calc_metrics(model, X, y): y_pred = model.predict(X) mse = mean_squared_error(y, y_pred) r2 = r2_score(y, y_pred) print('r2:',r2,'mse:',mse) print('训练集:') calc_metrics(model, X_train, y_train) print("测试集") calc_metrics(model, X_test, y_test)

模型调参,调参后训练集r2达到0.94, 测试集也提升至0.85

调参代码如下:
def adj_params(): """模型调参""" params = { 'n_estimators': [100, 200, 300, 400], # 'learning_rate': [0.01, 0.03, 0.05, 0.1], 'max_depth': [5, 8, 10, 12] } other_params = {'learning_rate': 0.1, 'seed': 42} model_adj = LGBMRegressor(**other_params) # sklearn提供的调参工具,训练集k折交叉验证(消除数据切分产生数据分布不均匀的影响) optimized_param = GridSearchCV(estimator=model_adj, param_grid=params, scoring='r2', cv=5, verbose=1) # 模型训练 optimized_param.fit(X_train, y_train) # 对应参数的k折交叉验证平均得分 means = optimized_param.cv_results_['mean_test_score'] params = optimized_param.cv_results_['params'] for mean, param in zip(means, params): print("mean_score: %f, params: %r" % (mean, param)) # 最佳模型参数 print('参数的最佳取值:{0}'.format(optimized_param.best_params_)) # 最佳参数模型得分 print('最佳模型得分:{0}'.format(optimized_param.best_score_))
代码在如下位置:

我们来代入大类资产的因子数据,由于量化投资,使用的价量数据是时序数据,因些不能按照train_test_split这样随机划分,我们需要按时间分成两段。
def train(self, train_func): df = self.df split_date = self.split_date df_train = df.loc[:split_date] df_val = df.loc[split_date:] fields, names = self.alpha.get_fields_names() train_func(df_train, df_val, feature_cols=names)
总体训练代码如下:
symbols = [ 'CL', # 原油 '^TNX', # 美十年期国债 'GOLD', # 黄金 '^NDX', # 纳指100 '000300.SH', # 沪深300 '000905.SH', # 中证500 '399006.SZ', # 创业板指数 '000012.SH', # 国债指数 '000832.SH', # 中证转债指数 'HSI', # 香港恒生 'N225', # 日经225 'GDAXI' # 德国DAX指数 ] m = ModelTrainer(symbols=symbols, alpha=Alpha158()) from models.lightgbm_models import train m.train(train_func=train)
在未进行数据预处理时,容易出现过拟合的情况:

代码在如下位置:

发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103244
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!