
Scikit-learn 是一个python的开源库,其提供了统一的接口,用于实现机器学习、数据预处理、交叉检验和可视化算法。本文汇集了该工具库的常用方法,方便查阅和参考。


导入数据
所需数据为数值类型,可用Numpy数组或Scipy稀疏矩阵保存;如果数据为其他类型,需要转换为数值类型的数组,如Pandas Dataframe数据就需要转换为数值型数组。
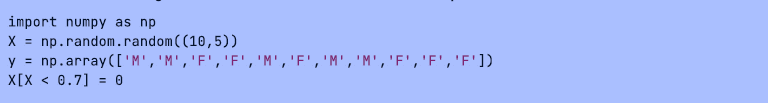
训练数据和测试数据

模型拟合
监管学习:

非监管学习:

预测
监管预测:

非监管预测:

数据预处理
数据标准化:

范式化:

二进制化:
分类特征编码:

处理缺失的数据:

生成多个特征:

创建模型
创建监管学习预测模型
(1)线性回归模型

(2)支持向量机模型(SVM)

(3)朴素贝叶斯模型
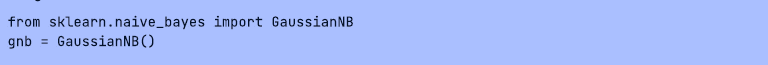
(4)KNN模型

非监管学习预测模型
(1)主成分分析(PCA)

(2)K means模型

模型评估
分类评价指标
(1)准确度评分

(2)生成分类报告

(3)混淆矩阵

回归评价指标
(1)均值绝对误差

(2)均值平方根误差

(3)R平方评分

聚类评价指标
(1)调整兰德系数

(2)同质化评价

(3)V-measure评分

模型调优
网格搜索:

随机参数优化:

发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76285
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!