
下面是量化投资中最常用的数据公式和概念,都是很简单的知识点,没有需要背诵的,只要知道就可以了。
一:数学期望
在日常生活中,我们每做的一件事,都有对它的期望,这里的期望不仅仅只有结果的胜负,也可以和状态有关。
但在数学中,一般指的就是达到结果的期望,最简单的计算是每次可能结果的概率乘以其结果的总和。
数学期望(Expected Value),也叫做均值或期望值,是概率论中一个重要的概念,表示随机变量在一系列可能结果中的
加权平均值。它是一个理论值,用于衡量在大量重复实现或观测中随机变量的平均表现。数学期望可以应用于离散型
和连续型随机变量。
期望 = SUM(事件发生的结果 * 事件发生的概率)
举例:一个人射箭,一共射了5次,分别是10环,8环,8环,7环,5环。
数学期望就是10*0.2 + 8*0.2 + 8*0.2 + 7*0.2 + 5*0.2
期望在金融领域的应用:
期望收益:
在投资组合管理中,期望收益是衡量投资组合预期表现的关键指标。通过计算各种资产的预期收益率和权重,
投资者可以了解投资组合的预期收益。期望收益可以帮助投资者根据风险偏好,投资目标和事件范围来选择合适
的投资组合。
风险度量:
期望在计算风险度量指标,如标准差,价值在险等时也起到关键作用。这些度量指标可以帮助投资者评估投资组合的
风险程度,从而制定相应的风险管理策略。
期权定价:
期望在期权定价模型中扮演者重要角色。期权定价模型需要计算标的资产在到期日的预期价格分布,以估算期权的合理价格。
期望在这一过程中用于计算预期收益率和波动率等参数。
二:方差
方差是衡量数据分布离散程度的统计量,用于表示数据集中各数据值与其平均值之间的差异程度。方差可以帮助我们了解数据的
波动性和不稳定性。方差值越大,波动越大,越不稳定。值越小,波动越小,越稳定。
方差(X) = SUM((X – X.MEAN())**2) / N
在python中numpy.ndarray.var()使用方法:
import numpy as np
a = [5, 6, 12, 9]
var = np.var(a)
print(var)三:标准差
标准差是一个用来衡量一组数据的离散程度(即数据分布的集中或分散程度)的统计指标。
它是方差的平方根,标准差可以帮助我们了解数据的波动性和不确定性。
标准差越大,波动越大,越不稳定。标准差越小,波动越小,越稳定。
标准差 = sqrt(方差)
在python中numpy.ndarray.std()的使用方法:
import numpy as np
b = [2,4,6,8]
std = np.std(b)
print(std)四:协方差
协方差(Covariance)是一种衡量两个随机变量之间线性相关性的统计量。如果两个变量的协方差为正值,那么他们在很大程度上是正相关的,
即一个变量增加时,另一个变量也倾向于增加。如果协方差为负值,则表示两个变量大致呈现负相关,即一个变量增加时,另一个变量倾向于减少。
如果协方差接近于零,则表示两个变量之间的相关性较弱。
协方差(x, y) = 期望((X – 期望(x)) * (Y – (期望(y))))
协方差(x, y) = sum(X – x.mean) * (Y – y.mean)) / n-1
五:相关系数
相关系数是一个统计指标,用于衡量两个变量之间的线性关系强度。其数值范围在-1到1之间。相关系数的绝对值越接近1,表示两个变量之间的线性关系越强;
相关系数为0表示两个变量之间没有线性关系;正值表示正相关,即一个变量增加时,另一个变量也增加;负值表示负相关,即一个变量增加时,另一个变量
减少;
Corr(x,y) = cov(x,y) / (std(x) * std(y))
相关系数是量化投资中用的非常多的,比如因子挖掘的时候。所以,我们重点介绍一下相关系数:
df.corr(method='')注意:
一:
df.corr(method='spearman')括号内的method有两个参数可选,一个是method=’spearman’
spearman 秩相关系数(斯皮尔曼相关系数):皮尔森相关系数主要用于服从正态分布的连续变量,不服从正态分布的变量,分类的关联性可采用spearman
秩相关系数,也称等级相关系数。
spearman系数和pearson系数在效率上等价.
输出范围为-1到+1,0代表无相关性,负值为负相关,正值为正相关。
0<|r|<1表示存在不同程度线性相关。
|r|<=0.3:不存在线性相关
0.3<|r|<=0.5:低度线性相关
0.5<|r|<=0.8:显著线性相关
|r|>0.8:高度线性相关
二:
df.corr(method='pearson')括号内的method有两个参数可选,第二个是method=’pearson’
皮尔森相关系数也称皮尔森积矩相关系数,是一种线性相关系数。
衡量向量相似度的一种方法。
输出范围为-1到+1,0代表无相关性,负值为负相关,正值为正相关。
0<|r|<1表示存在不同程度线性相关。
|r|<=0.3:不存在线性相关
0.3<|r|<=0.5:低度线性相关
0.5<|r|<=0.8:显著线性相关
|r|>0.8:高度线性相关
前提条件:正态分布。做皮尔森之前要先检验两组数据是不是正态分布。
总结:在使用df.corr()做相关系数之前,要先判断两组数据是不是服从正态分布,服从正态分布,使用method=’pearson’。不服从正态分布的,使用method=’spearman’
三:
K-S检验是否服从正态分布
那么怎么检验两组数据是不是服从正态分布呢?
原假设:数据符合正态分布
kstest(rvs, cdf, args=(), N=20, alternative=’two_sided’, mode=’approx’, **kwds)
对于正态性检验,我们只需要手动设置三个参数即可:
rvs:待检验的一组一维数据
cdf:检验方法,例如’norm’,’expon’,’rayleigh’,’gamma’,这里我们设置为’norm’,即正态性检验
alternative:默认为双尾检验,可以设置为’less’或’greater’作单尾检验
model:’approx'(默认),使用检验统计量的精确分布的近视值,
‘asymp’:使用检验统计量的渐进分布
”’输出结果中第一个为统计量,第二个为P值(注:统计量越接近0就越表明数据和标准正态分布拟合的越好,
如果P值大于显著性水平,通常是0.05,接受原假设,则判断样本的总体服从正态分布)”’
stats.kstest(a, ‘norm’)
举例:
'''
直接用算法做KS检验
'''
# scipy 包是一个高级的科学计算库,它和numpy联系很密切,scipy一般都是操控numpy数组来进行科学计算
from scipy import stats
# 样本数据,35位男士的血糖浓度,和楼上的数据一样的。
data = [87, 77, 92, 68,80,78, 84, 77, 81, 80, 80, 77, 92,86, 76, 80, 81, 75, 77, 72, 81, 72, 84, 86, 80, 68, 77, 87, 76, 77, 78, 92, 75, 80, 78]
df = pd.DataFrame(data, columns = ['value'])
u = df['value'].mean()
std = df['value'].std()
stats.kstest(df['value'], 'norm', (u, std))六:概率分布
概率分布是一个描述随机变量可能取值及其对应概率的数学表达。它是概率论和统计学中的基本概念,用于量化不确定性和随机性。
# 求样本的偏度
df.skew()
# 求样本的峰度
df.kurt()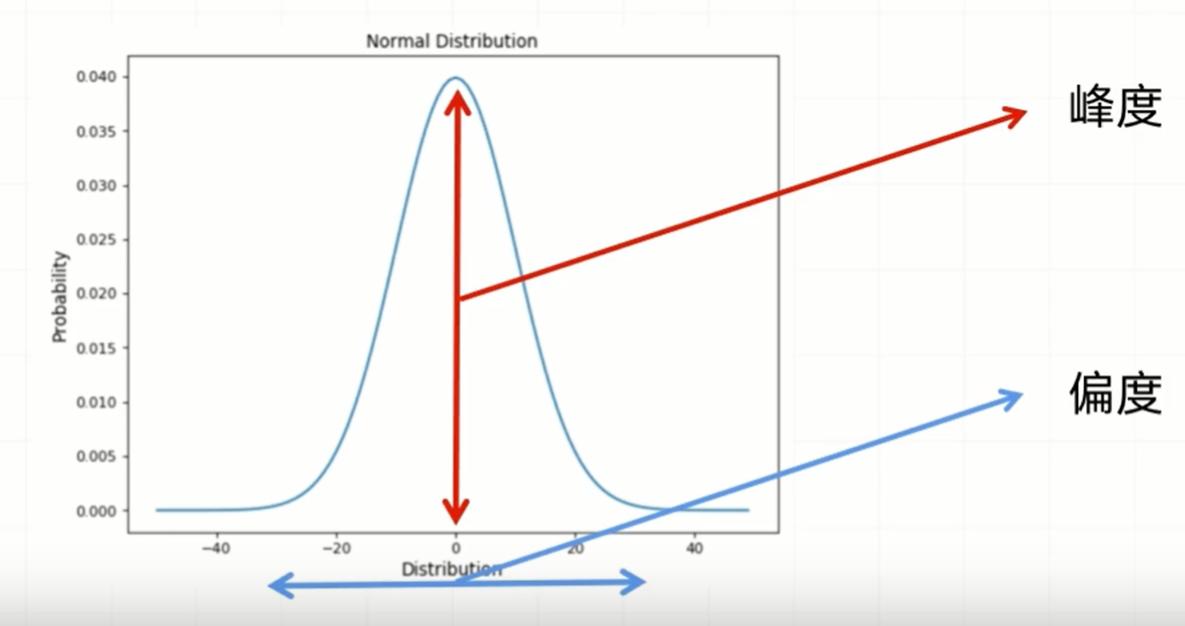

发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/702489
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!