
集成方法(Ensemble)是一种技术,通过创建多个模型,然后将它们合并以产生改进的结果。在机器学习中,集成方法通常比单个模型产生更准确的解决方案。这在许多机器学习比赛中都是如此,其中获胜的解决方案使用了集成方法。在流行的 Kaggle 竞赛中,获胜者通常会使用了集成方法来实现强大的协同过滤算法。
本文使用术语“模型”来描述用数据训练的算法的输出。然后使用该模型进行预测。该算法可以是任何机器学习算法,例如逻辑回归、决策树等。当这些模型作为集成方法的输入时,它们被称为“基本模型”,最终的结果是一个集成模型。本文将介绍用于分类的集成方法,并描述一些广为人知的集成方法:投票、堆叠、装袋和提升。
基于投票和平均的集成方法
投票和平均是机器学习中集成学习的两个最简单的例子。它们都易于理解和实施。投票用于分类,平均用于回归。
在这两种方法中,第一步都是使用一些训练数据集创建多个分类/回归模型。每个基本模型都可以使用相同训练数据集和相同算法的不同拆分,或者使用具有不同算法的相同数据集,或任何其他方法来创建。

-
多数表决:多数表决法是一种简单而直观的集成模型方法,它将多个预测结果进行投票,最终输出获得投票数最多的那个结果。这种方法适用于二分类或多分类问题,并且可以处理不同类型的预测器。 -
加权投票:加权投票法和多数表决法相似,但是在计算投票次数时,不同的预测器会被分配不同的权重。这些权重可以基于每个预测器的性能来赋值,通常越准确的预测器会被赋予更高的权重。 -
简单平均:简单平均法是将多个预测器的结果求平均值,作为最终的预测结果。这种方法适用于回归问题,并且对于具有相似性质和性能的预测器较为有效。 -
加权平均:加权平均法与简单平均法类似,但是不同的预测器会被分配不同的权重,以便更好地利用它们之间的差异。这种方法适用于回归问题,并且对于具有不同性质和性能的预测器较为有效。
堆叠集成方法
堆叠(Stacking)集成方法是一种用于集成多个预测模型的方法,它将不同类型的预测器组合在一起,通过训练一个次级学习器来汇总个体预测器的结果。
Stacking方法包含以下几个步骤:
第一步,需要用训练数据集来训练多个基础学习器,例如决策树、KNN、SVM等,每个基础学习器都会输出预测结果。
第二步,将第一步中得到的预测结果作为输入数据,再次将其分配给另一个学习器,称之为”元学习器”或”次级学习器”。通常情况下,元学习器是一个简单的线性回归模型或神经网络模型。
第三步,使用测试数据集对训练好的Stacking模型进行验证。
Stacking方法的优点是可以整合不同类型的预测器,从而提高了模型的性能和稳定性。但是,它也存在一些缺点,例如需要更多的计算资源和时间,以及可能会导致模型过拟合。此外,选择合适的基础学习器和元学习器也需要具有一定的经验和技巧。
Bootstrap方法
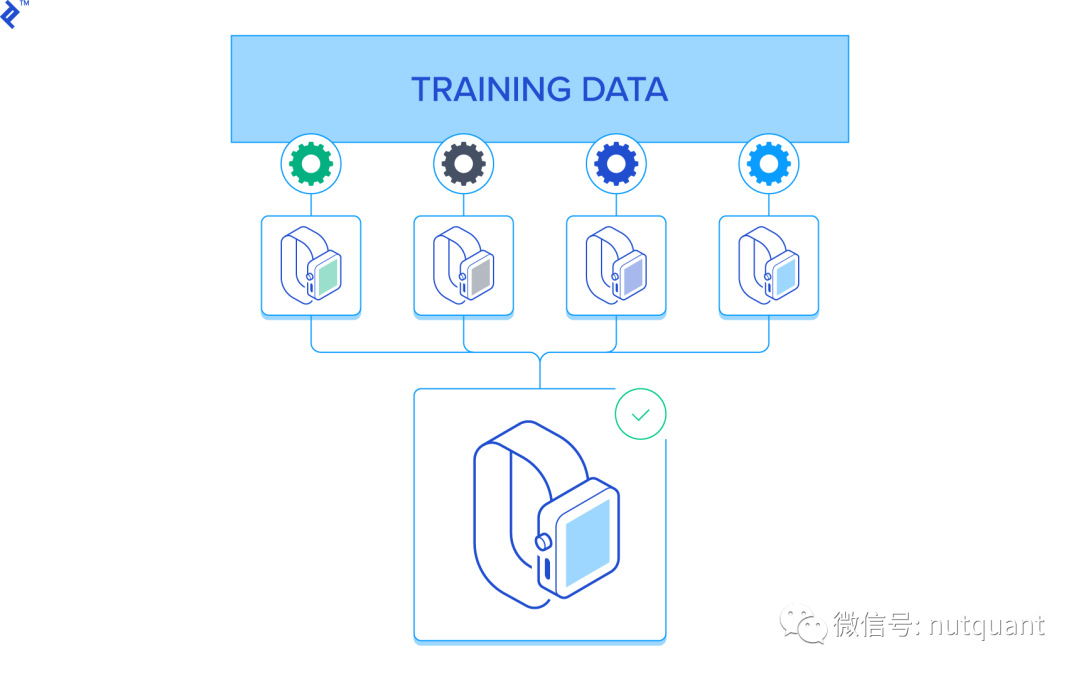
Bootstrap是一种集成方法中常用的技术,它可以增加模型的稳定性和准确性。Bootstrap方法通过有放回地从原始数据集中采样生成多个新的数据集,然后将这些新的数据集用于训练不同的预测模型。
在Bootstrap方法中,我们将原始数据集的大小设为N,每次随机抽取一个大小为N的样本作为新的数据集,并将其用于训练一个新的预测模型。由于采样是有放回的,所以有些样本会被重复抽取,而有些样本则可能被省略。这个过程可以重复进行M次,从而生成M个新的数据集和M个预测模型。最终的预测结果可以通过对这M个预测模型的输出进行平均或投票来得到。
Bootstrap方法具有以下优点:
-
减少过拟合:由于每个新的数据集都是从原始数据集中随机生成的,因此能够减少模型对特定数据分布的过拟合。 -
提高稳定性:使用多个不同的预测模型进行集成,能够提高整个模型的稳定性。 -
适用于小样本数据:当训练数据集较小时,Bootstrap方法可以有效地增加训练数据量,提高模型的表现。
Bootstrap方法也存在一些局限性。例如,采用Bootstrap方法时需要进行多次模型训练,因此会增加计算量和时间成本。此外,重复抽样可能会导致样本的选择偏差,影响最终预测结果的准确性。
Boosting方法
Boosting方法是一种常用的集成学习方法,通过逐步地训练多个弱学习器,并将它们组合成一个强学习器来提高模型的准确性。
Boosting方法包含以下几个步骤:
-
使用训练数据集训练一个初始的弱学习器,例如决策树、KNN等。这个学习器通常不能很好地解决分类或回归问题。 -
对于训练数据集中被错误分类的样本进行加权,使得下一次训练时更关注于这些样本。这个过程可以通过增大被错误分类的样本的权重来实现。 -
再次使用加权后的数据集重新训练一个新的弱学习器,然后将其与前面的学习器结合起来,形成一个更强的学习器。这个过程可以重复多次,每次都会生成一个新的弱学习器,并将其添加到整个模型中。 -
将所有的弱学习器组合起来,构建成一个强学习器,用于对测试数据进行预测。
Boosting方法在训练初期可能表现不如Bagging或Random Forest等其他集成方法,但随着迭代次数的增加,它可以逐步提高模型的准确性。Boosting方法在处理大规模数据和高维特征时比较有效,在图像识别、自然语言处理等领域有着广泛的应用。
集成学习是一种优雅而有效的方法,可以显著提高模型的预测效果。与单个模型相比,集成学习可以通过组合多个模型的结果来减少过拟合、提高稳定性,并增强整个模型的预测能力。同时,集成学习方法适用于各种类型的数据和问题,例如分类、回归、聚类等。使用集成学习技术,我们可以通过训练多个基础学习器并将它们组合起来以生成更可靠的预测结果。虽然集成学习需要更多的计算资源和时间,但这也是提升预测性能的代价,而且构建一个有效的集成模型,只需具备相关经验和技巧即可。因此,集成学习是一种实现精度和可靠性的优雅方式,可以使模型在各种应用场景中发挥出最佳的性能。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111094
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!