
一 本文简介
近年来,深度学习在自然语言处理领域取得了显著进展。然而,在时间序列预测领域,深度学习模型的应用仍处于探索阶段。时间序列本质上是一系列按时间顺序排列的数据点。可以将其视为一种序列问题,并尝试使用类似于自然语言处理中的预训练转换器等技术来解决时间序列预测问题,但这种方法并不总是有效的。目前,研究者们已经详细研究了深度学习模型在时间序列预测上的表现。然而这些工作并没有全面呈现问题的情况。即使在NLP领域,也有人将GPT模型的突破归因于“更多的数据和计算能力”,而非“更好的ML研究”。
本文旨在使用可靠的数据和来源来消除混淆并提供公正的观点,希望本文能够对广大读者在时间序列算法领域的研究和实践工作提供指导和帮助。本文涵盖的主要内容如下:
-
深度学习和统计模型的优缺点。 -
在何时使用统计模型,何时使用深度学习。 -
如何处理预测任务。 -
如何通过选择最佳模型来节省时间和金钱。
二 相关工作
本文的工作是在参考文献[1]的基础上进行分析。这是一篇最新的总结 Makridakis 竞赛中参赛算法表现的论文。Makridakis竞赛是一个关于时间序列预测的国际性评估比赛。该竞赛于1982年创办,竞赛的目标是提供一个公开、透明和可持续的平台,以评估不同的时间序列预测方法,并推动该领域的进步。在Makridakis竞赛中,参赛者需要使用真实世界数据集进行预测,并提交他们的预测结果。然后,这些预测结果会被评估和比较,以确定哪种方法或模型最有效。竞赛的评估标准通常包括平均绝对误差(MAE)、平均绝对百分比误差(MAPE)和平均绝对缩放误差(MASE)等指标。这些指标可以帮助评估预测模型的准确性、稳定性和可靠性。
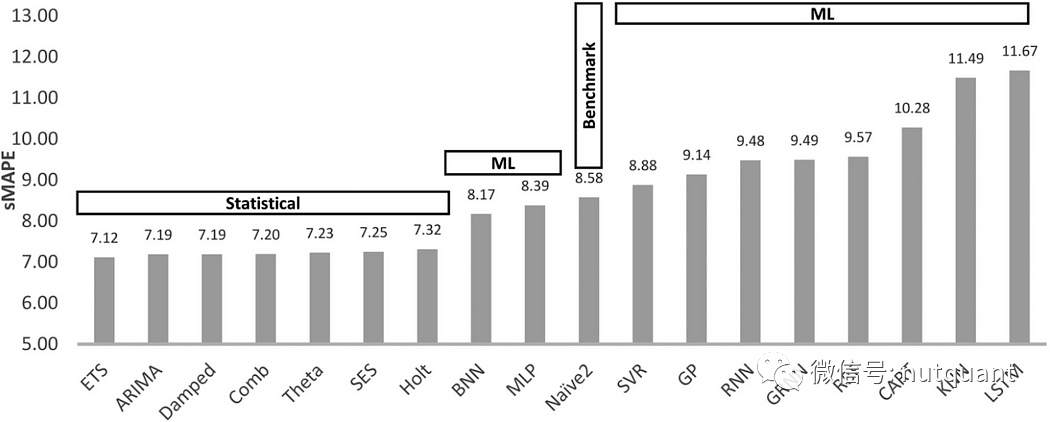

与 自然语言处理不同,直到 2018-2019 年,第一个深度学习模型预测模型才成熟到足以挑战传统预测模型。上文展示了八种统计方法和十种机器学习预测方法的预测准确性(sMAPE)。在2018年之前所有机器学习方法都排在最后。
在基准方法中,统计模型使用了ARIMA和ETS(指数平滑)。此外,作者进行了以下操作:
-
通过超参数调整来微调机器学习和深度学习模型。 -
统计模型逐个时间序列进行训练,而深度学习模型是全局的(在数据集的所有时间序列上训练的单个模型)。因此,作者利用交叉学习。 -
使用集成方法:Ensemble-DL模型由深度学习模型和Ensemble-S组成,它由统计模型组成。集成方法是预测的中位数。 -
Ensemble-DL包含200个模型,每个类别有50个模型:DeepAR、Transformer、WaveNet和MLP。 -
该研究使用M3数据集:首先,作者测试了1045个时间序列,然后是完整数据集(3003个序列)。 -
作者使用MASE(平均绝对比例误差)和SMAPE(平均绝对百分比误差)来测量预测准确性。这些误差指标通常用于预测。
三 结果分析
接下来,我们来分析从上述基准测试的结果中获得的结论。
3.1 深度学习模型整体表现更好
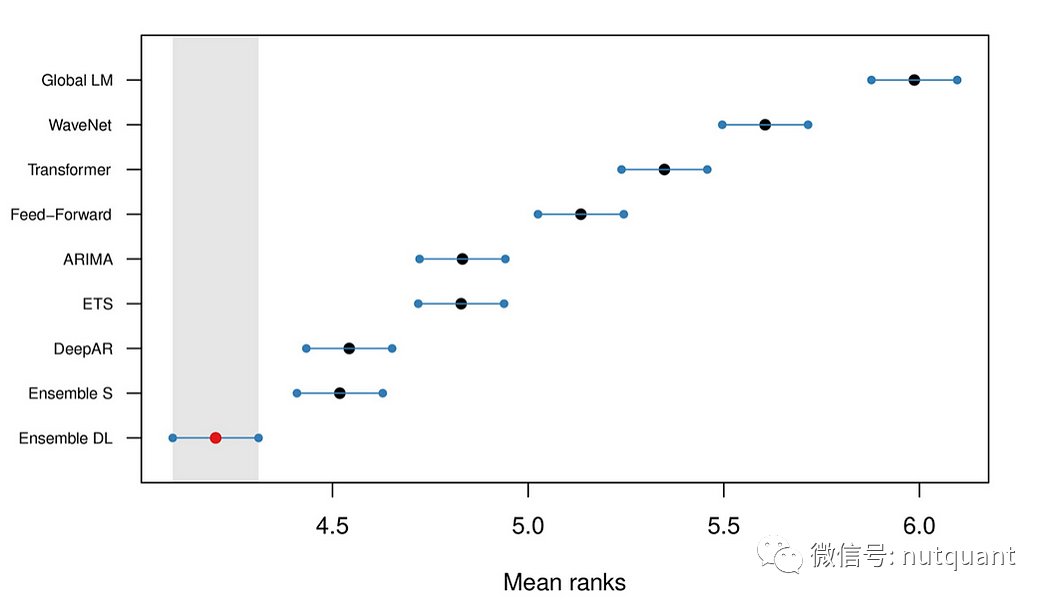
从上图可以看出,Ensemble-DL模型整体表现确实优于Ensemble-S模型,但是仅有DeepAR模型的表现优于单个统计模型。这可能意味着在某些情况下,深度学习模型并不总是优于传统的统计模型。具体而言,可能是因为在某些时间序列数据集上,统计模型更适合捕捉特定的模式和趋势,从而能够产生更好的预测结果。此外,当训练数据集较小或噪声较大时,深度学习模型的泛化能力可能会受到影响,导致其在测试集上的表现不如统计模型。
总之,选择何种模型取决于特定问题的性质和数据的特征。在某些情况下,深度学习模型可能比传统的统计模型更为有效,但在其他情况下则可能相反。
3.2 深度学习模型很昂贵
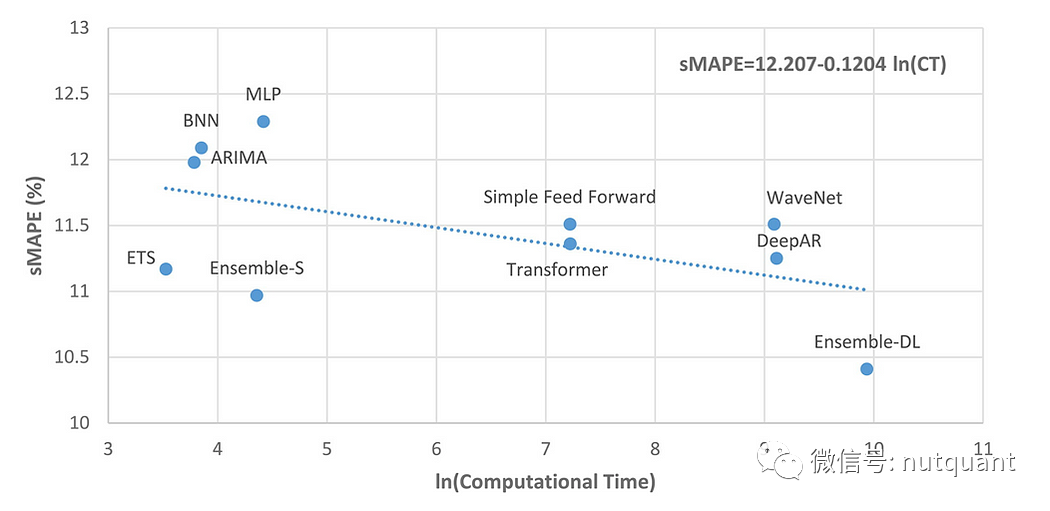
如上图所示,深度学习模型的训练时间和计算成本通常比传统的统计模型更高。这是由于深度学习需要大量的计算资源和时间来训练大量的参数。但是,也有一些方法可以缩短深度学习模型的训练时间,例如使用更快的硬件、并行化训练和优化训练过程。另外,从下图可以看出,通过减少集成中使用的模型数量,可以显著降低深度学习模型的计算成本,同时仍然保持较高的预测精度。这暗示着在实践中,我们可以探索更智能的集成方法,以在保持预测准确性的前提下降低计算成本。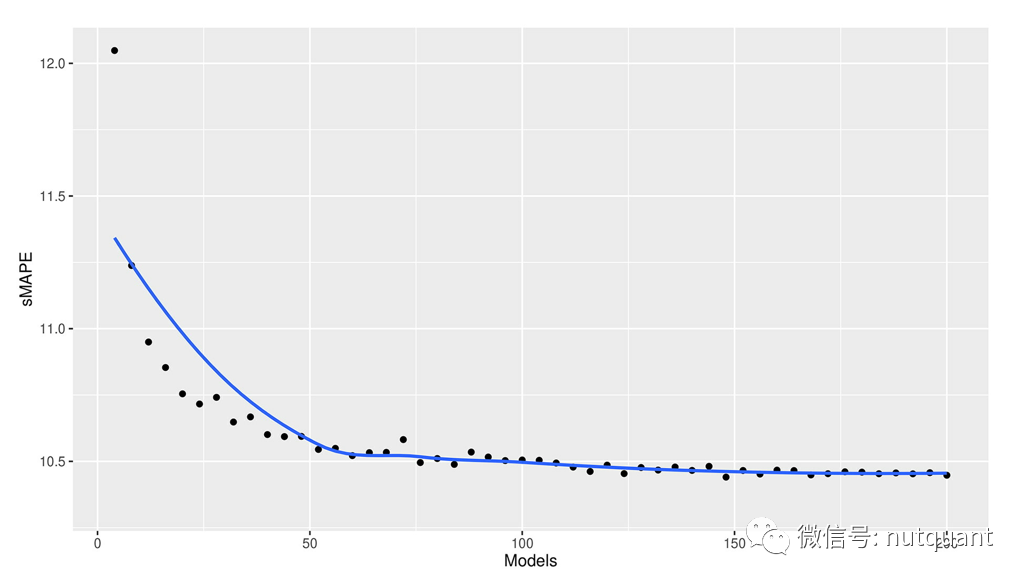
最后,深度学习模型的迁移学习能力可能会进一步扩展其应用范围,并且可以在更小的数据集上进行训练,从而减少计算成本。这可能是未来研究的一个重要方向。
3.3 集成模型是最好的
集成方法是非常有效的。Ensemble-DL和Ensemble-SL都是能够提供最佳性能的模型。这种方法利用多个单独模型各自捕捉时间序列数据的不同动态特征,通过将它们的预测结果结合起来,可以获得更准确、更全面的预测结果。这种方法能够识别出复杂的模式,从而进一步增强了算法的性能。
3.4 短期预测和长期预测存在差异
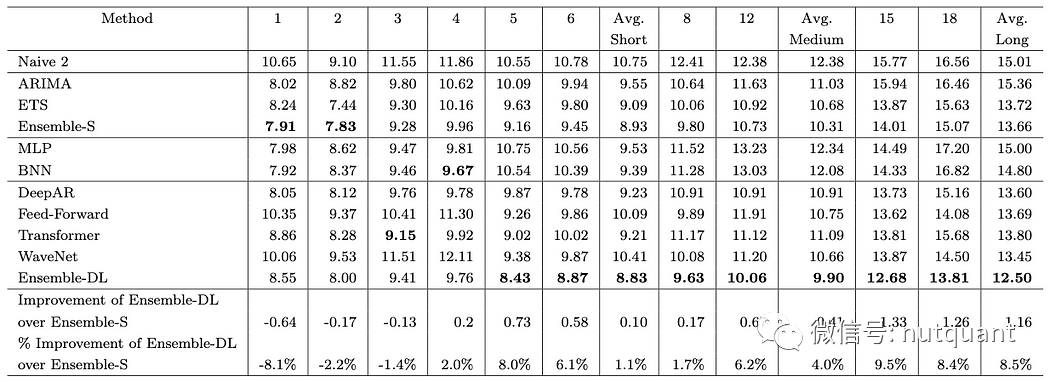
从上图中我们可以得出以下的观察结果:
-
首先,长期预测的准确性通常不如短期预测,这可能是由于随着预测范围的增加,误差会逐渐积累导致的。 -
其次,在前四个时间窗口中,统计模型表现更好。然而,随着预测窗口的增加,深度学习模型开始表现更好,最终Ensemble-DL获胜。具体来说,Ensemble-S的准确性在第一个窗口中提高了8.1%,而Ensemble-DL则在最后一个视野中提高了8.5%。这可能是由于深度学习模型是多输出模型,因此其预测误差分布在整个预测序列中,而统计模型则是自回归模型,随着预测范围的增加,误差会累积。
3.5 深度学习模型会随着数据的增加而改进吗?
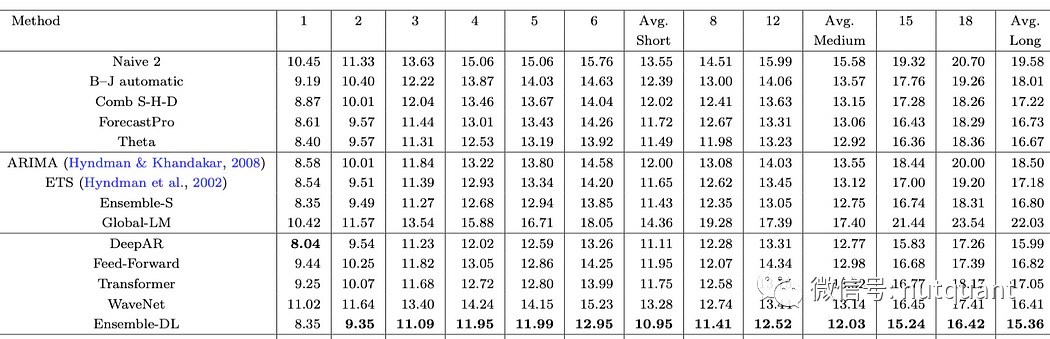
作者进一步扩展了实验并使用完整的数据集(3003个时间序列)进行重新运行。他们还分析了每个预测范围内的预测损失,并将结果绘制在上图中。与之前在1045个时间序列上的实验相比,Ensemble-DL和Ensemble-S之间的差距已经缩小了。统计模型在第一个时间窗口中与深度学习模型相匹配,但是之后,Ensemble-DL的表现优于它们。
随着预测时间步骤的增加,深度学习模型的性能明显优于统计集成方法。
3.6 关于趋势和季节性分析
作者还研究了统计模型和深度学习模型如何处理趋势和季节性等重要的时间序列特征,并探究这些特征与sMAPE误差之间的关系。结果如下图所示。从图中我们可以看出,具有噪声、趋势和非线性数据时,深度学习模型表现更好。而统计模型则更适合具有线性关系的季节性和低方差数据。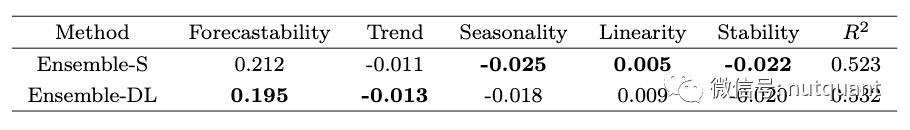
这些见解对于选择合适的模型以及进行数据分析和预测都是无价的。在实际应用中,我们应该对数据进行广泛的探索性分析(EDA),了解数据的性质和特点,然后选择能够最好地捕捉这些特征的模型来进行预测。
四 总结展望
总的来说,这篇论文提出了一个非常有用的时间序列预测框架,并对不同类型的模型进行了广泛的比较和分析。但是,它也存在一些局限性。
首先,研究中没有涉及到树/提升树模型,尤其是在处理类似表格数据的情况下,Boosted Trees 模型仍然是最佳选择之一。
其次,使用 M3 数据集作为基准数据集可能过于简单,并不能完全代表现代实际场景中的时间序列数据特征。因此,在未来的研究中,应该使用更大、更复杂的数据集进行测试和探索。
第三,本研究中使用的深度学习模型已经落后于当前的技术水平。新的模型如MQTransformer、TFT、N-BEATS等在时间序列预测中都取得了很好的效果,并且在零样本学习和元学习方面有着更广阔的应用前景。
最后,除了预测准确性外,其他关键领域如不确定性量化、预测可解释性、零样本学习或元学习等也是时间序列预测中需要考虑的重要因素。因此,在未来的研究中,应该进一步探讨这些方面的问题。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111093
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!