
数据挖掘的第一步通常是进行数据探索性分析(EDA),以理解和探索正在解决的问题的数据。通过EDA, 我们可以分析数据集,了解变量间的相互关系以及变量与预测值之间的关系,帮助后期更好地进行特征工程和建立模型,是数据挖掘中非常关键的一步。
ydata-profiling库主要目标是在一致且快速的解决方案中提供单线探索性数据分析 (EDA) 体验。就像 pandasdf.describe()函数一样,它非常方便 。ydata-profiling 提供了对 DataFrame 的扩展分析,允许以html和json等不同格式导出数据分析。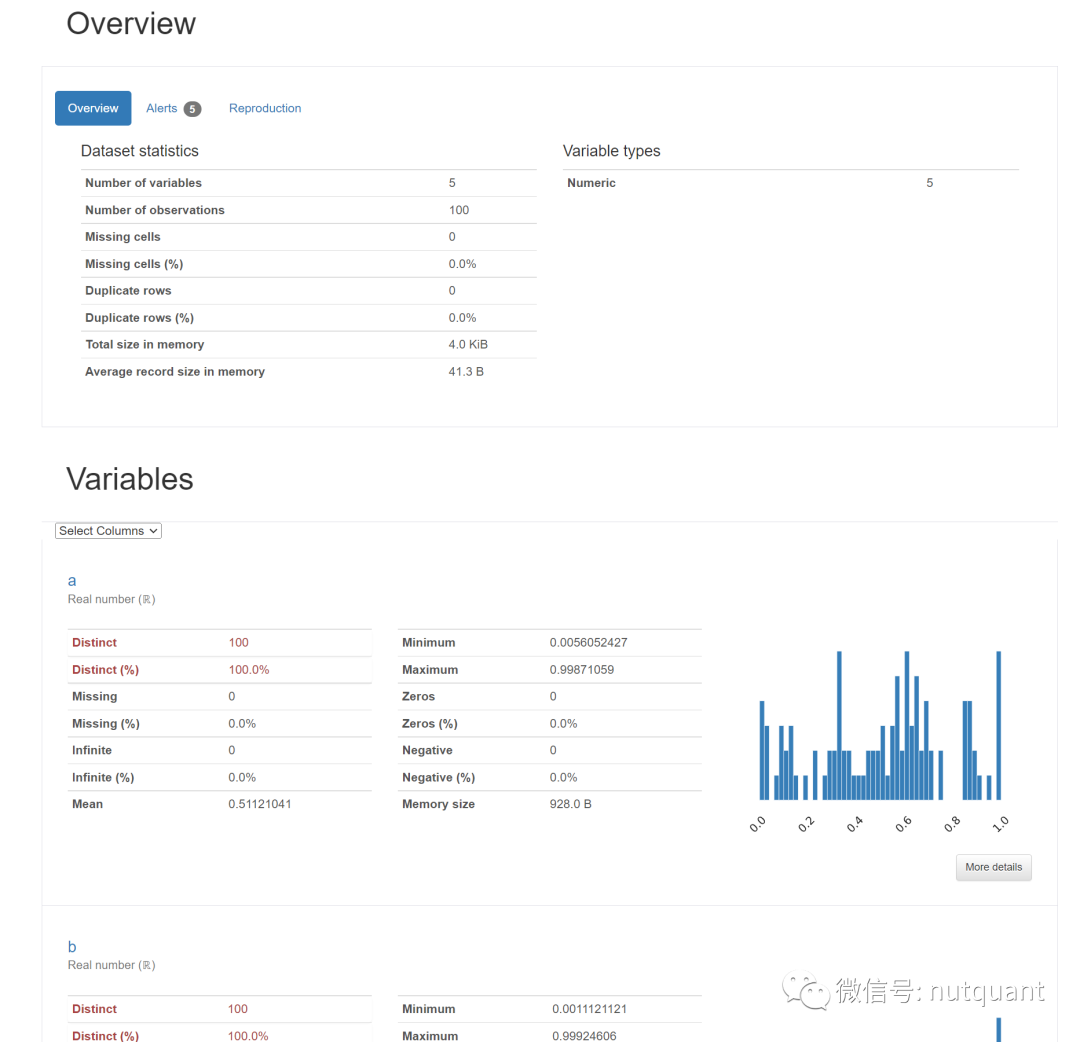

主要特征
-
类型推断:自动检测列的数据类型(Categorical、Numerical、Date等); -
警告:提示数据中存在的可能需要处理的的问题(如缺失数据、不准确等); -
单变量分析:包括描述性统计(均值、中值、众数等)和可视化,例如分布直方图; -
多变量分析:包括相关性、缺失数据的详细分析、重复行以及对变量成对交互的可视化支持; -
时间序列:包括与时间相关数据相关的不同统计信息,例如自相关和季节性,以及 ACF 和 PACF 图; -
文本分析:最常见的类别(大写、小写、分隔符)、脚本; -
文件和图像分析:文件大小、创建日期、尺寸、截断图像的指示和 EXIF 元数据; -
比较数据集:快速完成数据集比较并生成报告; -
灵活的输出格式:所有分析都可以导出为 HTML或JSON文件,也可以作为 Jupyter Notebook 中的小部件。
安装
pip install -U ydata-profiling
conda install -c conda-forge ydata-profiling
使用示例
ydata-profiling支持在python脚本中进行一键调用,可以导出为HTML和JSON两种格式的分析报告:
import numpy as np
import pandas as pd
from ydata_profiling import ProfileReport
df = pd.DataFrame(np.random.rand(100, 5), columns=["a", "b", "c", "d", "e"])
profile = ProfileReport(df, title="Profiling Report")
# 获取HTML文件的形式的数据报告
profile.to_file("report.html")
# 获取JSON文件的形式的数据报告
profile.to_file("report.json")
ydata-profiling支持在Jupyter Notebook中使用,可以通过小部件和嵌入式HTML两种形式调用:
profile = ProfileReport(df, title="Profiling Report")
# 通过小部件使用
profile.to_widgets()
# 生成嵌入式HTML报告
profile.to_notebook_iframe()
对于标准格式的CSV文件, ydata-profiling支持直接使用命令行工具生成分析报告:
pandas_profiling --title "Example Profiling Report" --config_file default.yaml data.csv report.html
ydata-profiling支持对大型数据集进行分析,可以处理敏感数据,进行数据集的对比,分析时序数据集,自定义数据报告的外观……. 详细使用说明请参考ydata-profiling的文档。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111084
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!