
一. 本文概要
机器学习技术在股票交易和股票价格预测中发挥重要作用,其中一种方法是使用强化学习、LSTM和transformers等技术。现有的强化学习算法在决策时通常不考虑过去的股票数据,为了解决这个问题,提出了一种名为TACR的方法。TACR利用决策transformer模型和评论家网络,能够利用过去的股票数据来预测当前的最佳操作并评估动作的价值。与基线方法相比,TACR的夏普比和收益获得了显著的提高。
二. 本文方法
为了使用强化学习,本文受限构建了一个马尔可夫决策过程(MDP)的状态空间,用于表示股票的相关信息,例如开盘价、收盘价、最高价、最低价以及技术指标等。而动作空间则表示一组满足特定条件的权重分配,用于表示在当前时期中投资于不同股票的比例。任务的目标是通过选择合适的权重分配来最大化收益。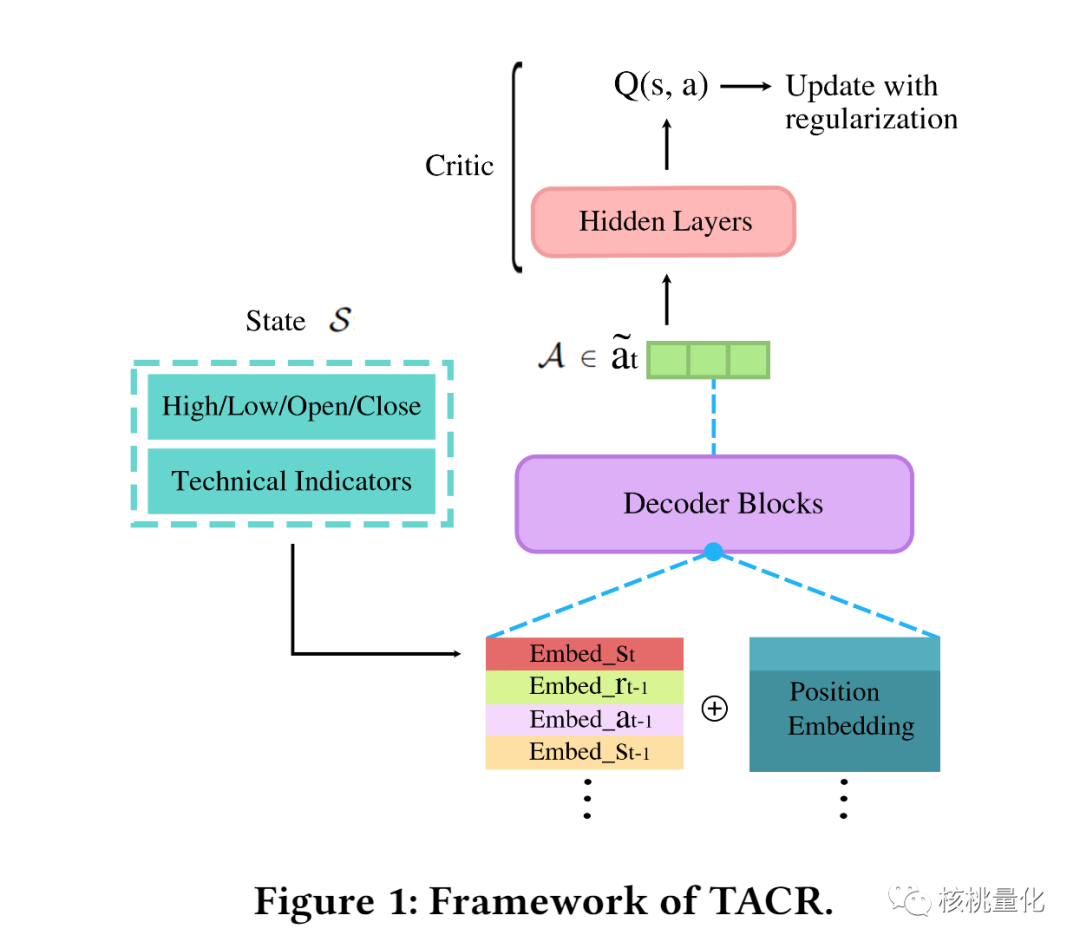

如上图所示,为了实现最大化收益的目标,TACR采用了决策Transformer作为决策者(actor),它通过预测动作并通过评论家网络对动作进行评估来提高性能。决策Transformer的机制是将先前的MDP元素映射到当前的动作。它由隐藏层和多个解码器块组成,其中解码器块使用注意力机制来训练每个MDP元素之间的相关性。与常用的离策略方法不同,TACR选择了离线训练方法来训练模型。离线训练意味着我们通过模仿预先准备的次优动作来训练代理,以期望获得更好的性能并减少学习时间。为了进行离线训练,我们需要创建次优轨迹,即将每个状态对应的次优动作进行配对。我们通过生成具有高动作率的轨迹,根据股票价格的增长率来实现这一点。然而,离线RL算法存在一个问题,即在更新策略时无法与环境进行交互,导致代理无法准确估计未见状态的动作价值。为了解决这个问题,TACR引入了一种正则化方法。该方法通过为模型添加一个行为克隆正则化术语,使得决策Transformer能够更好地模拟数据集中次优轨迹中的动作分布。这个正则化项帮助我们更准确地评估模型的性能。
三. 实验分析
本文实验使用了几个数据集(包括美国、德国和中国的股票指数数据集)来比较TACR模型的性能,这些数据集与其他最先进的方法进行对比。所有数据集都是按天进行的交易,使用投资组合价值和夏普比率作为评估标准。对比的基线方法包括离线RL、离策略RL、在策略RL和经典方法(等权策略)。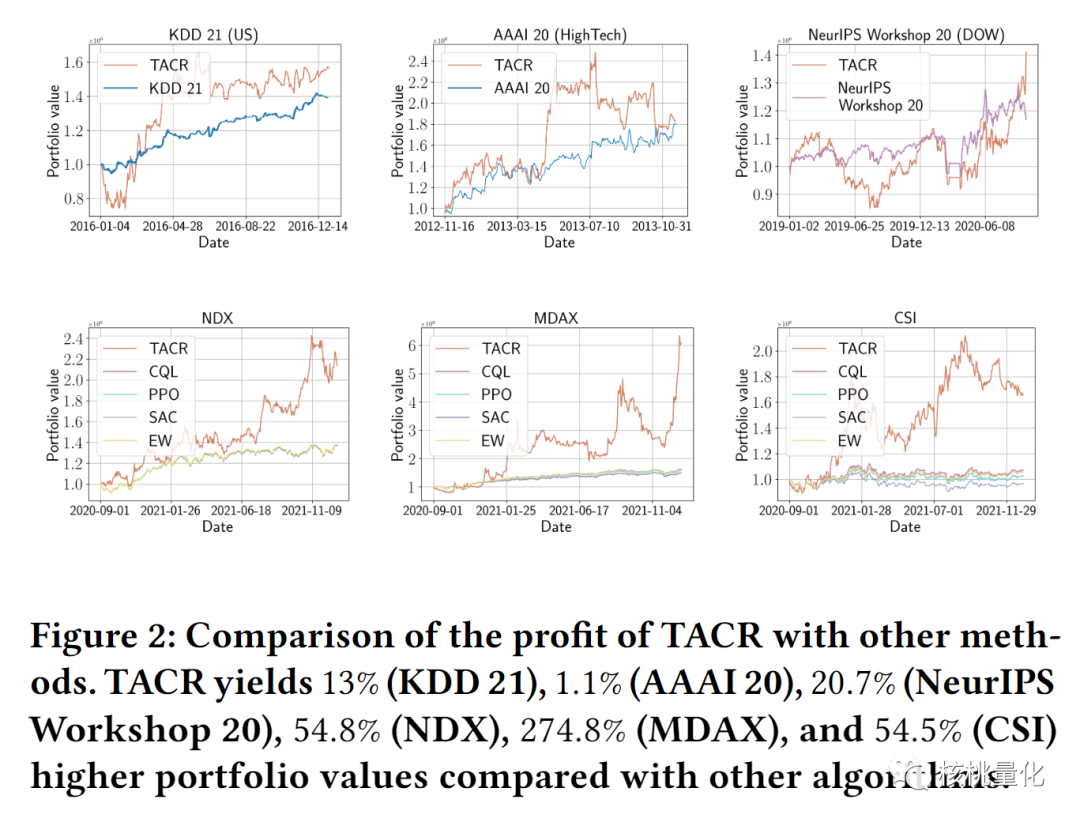
结果显示,与各种基线方法相比,TACR模型具有最好的性能。与其他算法相比,TACR模型在夏普比率方面也表现出色,至少高出基线13.1%,最高可达177.7%。此外,当增加过去MDP元素的序列长度时,大多数数据集都显示出良好的结果,这意味着在考虑更长时间的历史信息时,TACR能够更接近最优的投资行为。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111037
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!