
1. 问题介绍
在时序数据中,由于环境的不稳定性,数据分布常常会随时间变化,且这种变化通常被认为是难以预测的。这种现象被称为概念漂移(Concept Drift),它会导致在历史数据上训练的模型在概念漂移后性能下降。在下图的例子中:圆形和三角形代表两类数据。随着时间的推移,三角形的数据越来越多,两类数据的分类边界朝左上侧进行转移。此时在历史数据(Historical data)中训练的模型如果缺乏对分类边界移动的感知,在接下来的未知数据(Unseen data)上的性能会发生较大的下降。监督学习是最常用的机器学习方法,监督学习的假设是训练数据和测试数据是独立同分布的,当数据的分布不一致时,模型将会过拟合训练数据,欠拟合测试数据。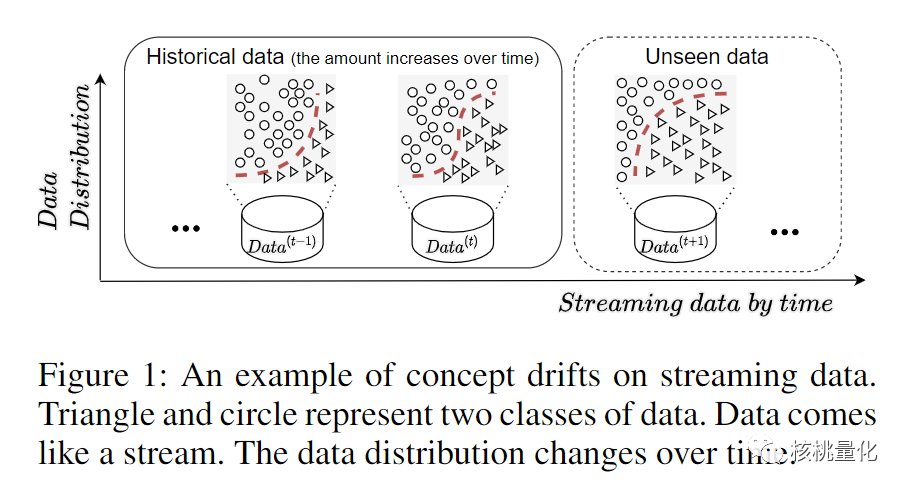
2. 已有方法
为了处理概念漂移问题,此前的工作会检测概念漂移是否发生,然后调整模型以适应最近的数据分布。
下面是本文实验部分选取的对比工作,基本包含了处理概念漂移的各种方法。
-
RR(定期滚动重新训练模型):RR模型周期性地在内存中的数据上进行重新训练,使用相等的权重。内存只存储有限窗口大小内的最新数据。 -
GF-Lin(基于RR的渐进遗忘):GF-Lin方法基于RR模型,通过线性地降低权重来实现渐进遗忘,权重随时间逐渐减小。 -
GF-Exp(基于RR的渐进遗忘):GF-Exp方法也基于RR模型,但通过指数衰减的方式降低权重来实现渐进遗忘,权重随时间指数级减小。 -
ARF(自适应随机森林):ARF方法用于处理流式数据中的概念漂移,它对每个新创建的树进行内部和外部概念漂移检测。最终的预测通过投票策略得出。 -
Condor(基于模型重用的概念漂移处理):Condor方法是一种集成方法,通过建立新模型和为先前模型分配权重来处理非平稳环境中的概念漂移。它通过模型重用的方式来处理概念漂移。
3. 本文贡献
本文提出了一种新方法 DDG-DA 来预测数据分布未来的变化,然后利用预测的数据分布生成新的训练数据来学习模型以适应概念漂移,最终提升模型性能。DDG-DA 算法提出并证明了未来数据的数据分布是可预测的。
DDG-DA算法可以利用时序数据中随时间产生的样本,学习或调整模型以进行未来一段时间的预测。由于历史数据和未来数据的分布存在差异,这会影响学得模型的预测性能。因此,DDG-DA的目标是缩小这种分布差距。DDG-DA会输出历史数据的采样权重,并基于这些权重重新采样生成数据集,该数据集的分布被用作未来一段时间的分布预测。同时,该研究还设计了一个与KL散度等价的分布距离函数,用于衡量预测分布与未来实际分布之间的差距。该距离函数具有可导性质,因此可以高效地学习DDG-DA的参数,以最小化其预测分布误差。在学习阶段,DDG-DA首先在历史时序数据上学习如何重采样数据。在预测阶段,DDG-DA定期通过重采样历史数据生成训练数据集。在DDG-DA生成的数据集上训练的模型将能更好地适应未来数据分布的变化,从而缓解概念漂移导致的模型精度下降。
4. 算法分析

在DDG-DA中,整个模型的设计和学习过程可以分为内外两层训练优化。
外层训练优化
首先,我们构建了一个用于训练的任务集合Task_train,其中包含了多个任务。我们的学习目标是提高在测试任务集合Task_test上的性能。这个外层的训练优化过程旨在使得整个模型能够在不同任务上表现更好。外层优化的目标是采样概率预测模型。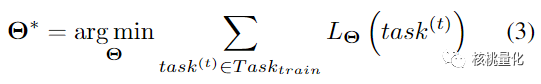
内层训练优化
外层任务目标本身是最小化采样数据和测试数据两个分布之间的KL loss: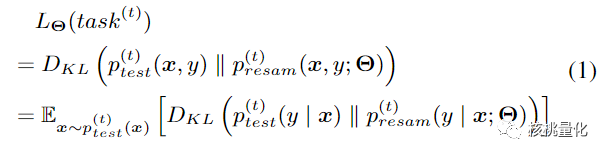
经过数学转换(细节可以参考文章附录),损失函数转换为下面的形式,第一项是采样数据,第二项是要测试数据: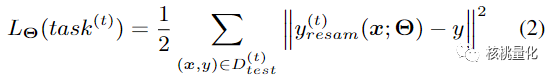
由于采样本身是不可微的,为了使得梯度可以回传,本文使用一个线性代理模型来近似代替采样,代理模型的优化目标是在采样数据集上最小化下面的loss,这也是内层优化的目标: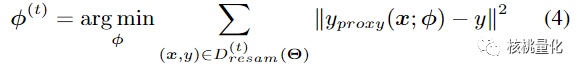
公式4的优化目标又可以转换为下面的形式,其中Q部分就是要输出的采样概率: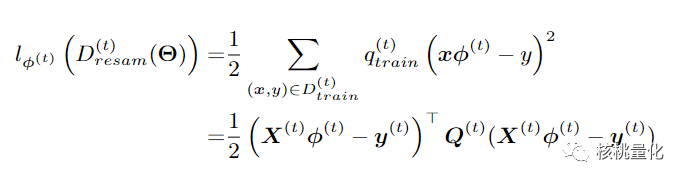
整体训练
综合来看,整个问题变成一个两层优化问题,外层是元任务训练优化采样概率预测模型(公式3),内层是优化代理模型(公式4),由于使用了代理模型,所以外层训练的梯度是可以经过公式4直接回传到采样概率Q的,实现了对采样概率生成的网络进行更新。整体的优化目标如下: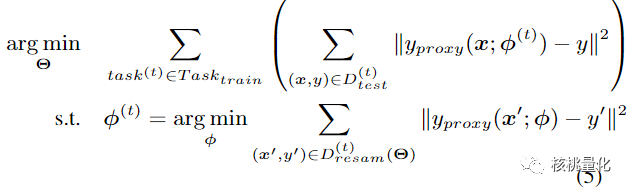
通过内外两层训练优化的迭代,DDG-DA可以逐步改进模型的性能,使其在测试任务上表现更好。外层训练优化采样概率预测模型,而内层训练对代理模型进行优化。
5. 实验结果
本文进行了多组实验,实验结果显示DDG-DA方法在股价预测、电力负荷和日照辐照度三个真实场景预测任务和多个模型上进行了实验验证并且性能得到了显著提升。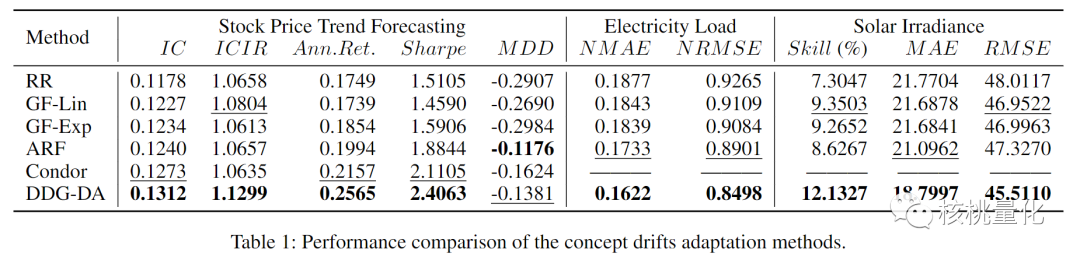
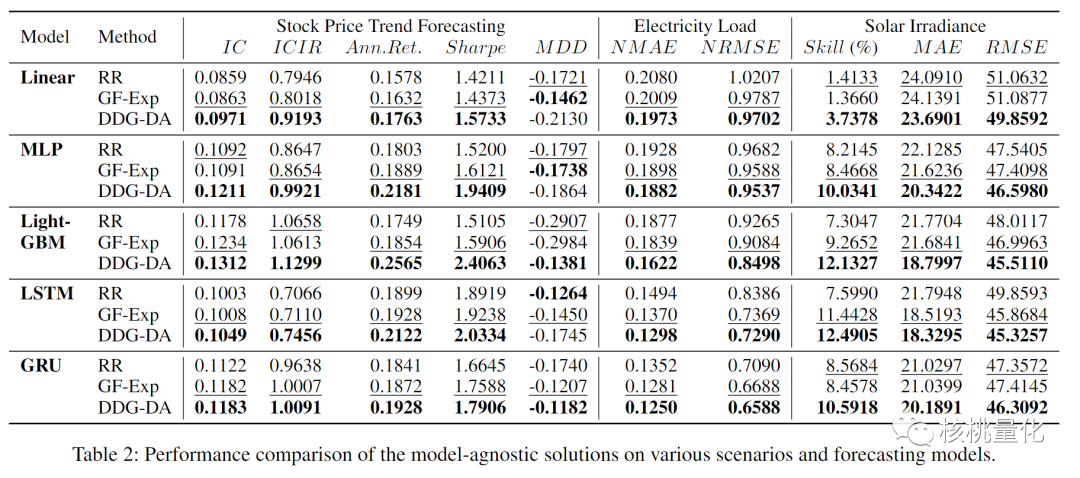
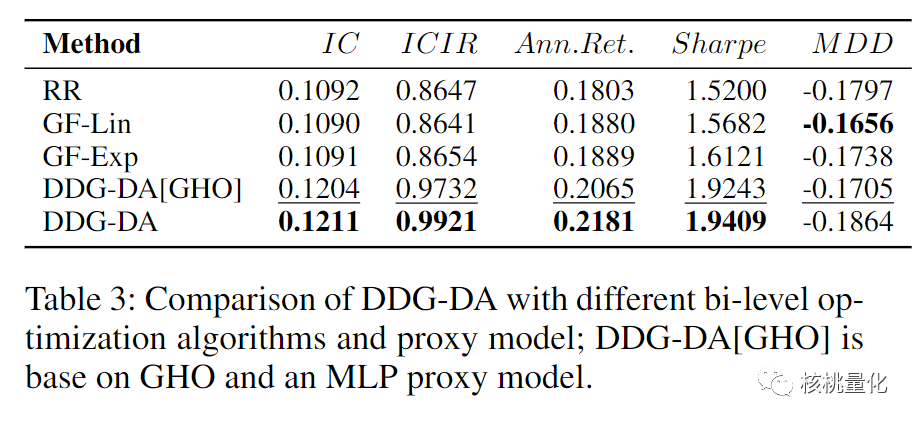
6. 总结展望
本文提出了DDG-DA方法着力于从预测未来数据分布的角度解决概念漂移问题。实验结果显示,相对于以往的工作,预测未来数据分布的方法表现的更优秀。但是当前该方向的研究工作尚且偏少,仍有较多有意思的问题可以研究,作者也提到了当前DDG-DA是一个针对静态模式数据的方法,后续工作会将DDG-DA优化为一个可以适用于动态数据的方法。
后续可以考虑从以下几点扩展算法:
(1)更加充分的利用训练样本的时序先后信息生成采样概率;
(2)扩展算法到分类问题,验证算法在分类问题上的表现;
(3)当前算法只能采样单步样本,是否可以拓展为支持采样或重构多步序列样本;
(4)时序数据的训练集划分长度通常是一个固定数值的超参,过长和过短的训练集都会影响模型精度,是否可以利用DDG-DA的方法为每个任务自动选择训练集长度以提高模型训练精度;
(5)当前是通过采样数据生成训练集,是否可以通过采样+生成的方法生成训练数据集;
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111033
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!




![[通达信指标]一款效果不错的背离公式](https://95sca.cn/2024/08/07/ufMJoKgF8YOr4mA1722996571.7124038.jpg?imageMogr2/thumbnail/!480x300r|imageMogr2/gravity/center/crop/480x300)
