
如果能提前准确预测这些信息,可以为医生提供重要见解,从而能够相应并有效地进行患者治疗。以下演示了对流行的心脏疾病数据库进行的探索性数据分析。除此之外,还使用不同方法(如逻辑回归、随机森林和神经网络)进行心脏病预测。
数据集:数据集包含76个属性,但建议我们只使用其中的14个进行分析。在本文中,使用一个合并的数据集构建分类器,并使用交叉验证技术进行性能评估。
特征:
-
Age:年龄(以年为单位)。
-
Gender:性别,1表示男性,0表示女性。
-
Cp:胸痛类型,取值1:典型心绞痛,取值2:非典型心绞痛,取值3:非心绞痛疼痛,取值4:无症状。
-
Trestbps:静息血压(以毫米汞柱为单位)。
- Chol:血清胆固醇(以毫克/分升为单位)。
- Fbs:空腹血糖 > 120 mg/dl,1表示真,0表示假。
- Restecg:静息心电图结果,取值0:正常,取值1:ST-T波异常,取值2:根据Estes标准显示可能或明确的左室肥厚。
- Thalach:达到的最高心率(每分钟心跳数)。
- Exang:运动诱发心绞痛,1表示是,0表示否。
- Oldpeak:相对于休息引起的ST段压低。
- Slope:峰值运动ST段的斜率,取值1:上坡,取值2:平坦,取值3:下坡。
- Ca:血管数量(0-3)。
- Thal:3 = 正常;6 = 固定缺陷;7 = 可逆性缺陷。
- Target:两个类别,因此是一个二分类问题。
目标:预测一个人是否患有心脏疾病。
读取数据集并检查是否有缺失值
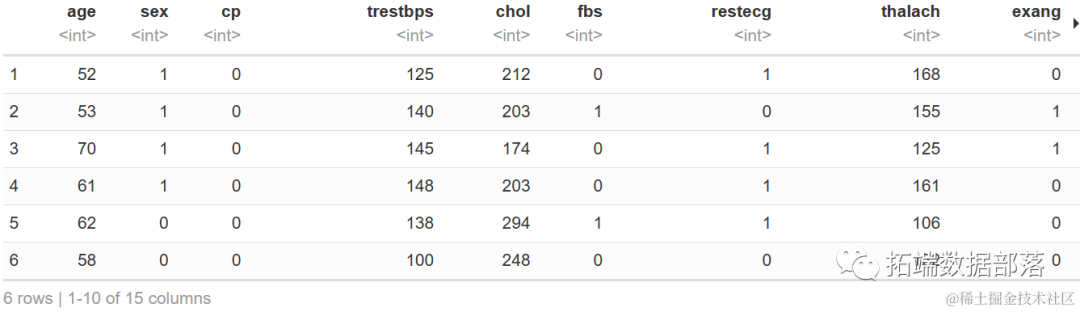
head(heartDiseaseData)

sum(is.na(heartDiseaseData))
## [1] 0
colnames(heartDiseaseData)[1]<-"age"
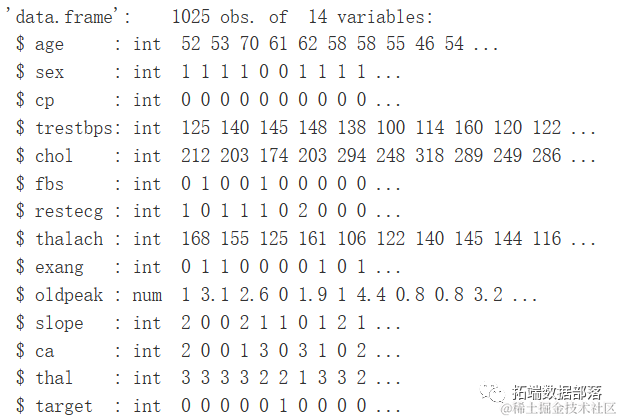
str(heartDiseaseData)
数据预处理
heartDiseaseData$cp<-as.factor(heartDiseaseData$cp)
levels(heartDiseaseData$cp)[levels(heartDiseaseData$cp)==0] <- "Chest Pain Type 0"
levels(heartDiseaseData$cp)[levels(heartDiseaseData$cp)==1] <- "Chest Pain Type 1"
levels(heartDiseaseData$cp)[levels(heartDiseaseData$cp)==2] <- "Chest Pain Type 2"
levels(heartDiseaseData$cp)[levels(heartDiseaseData$cp)==3] <- "Chest Pain Type 3"
...

检查缺失值
sum(is.na(heartDiseaseData))
## [1] 0
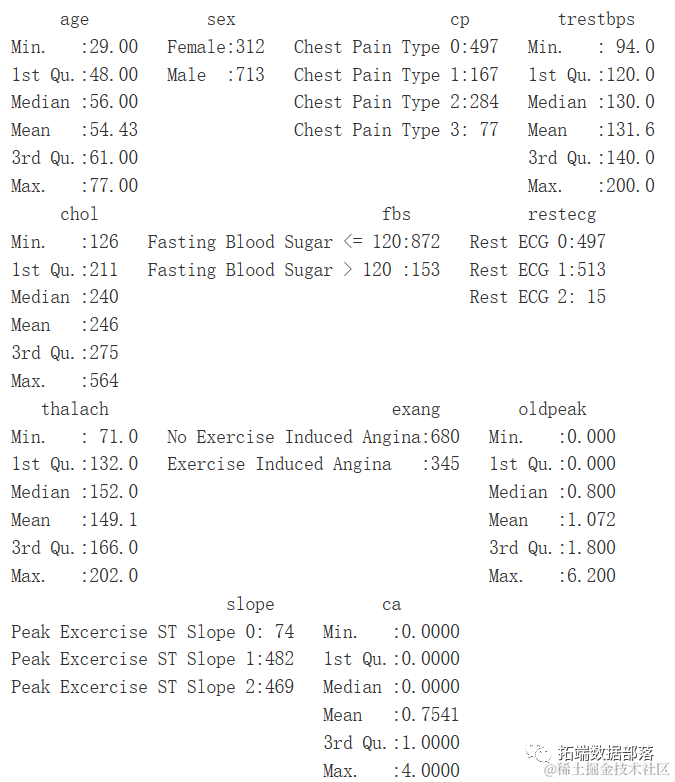
数据摘要
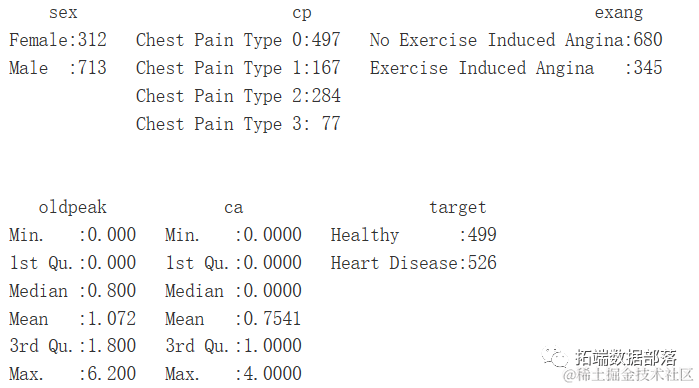
summary(heartDiseaseData)
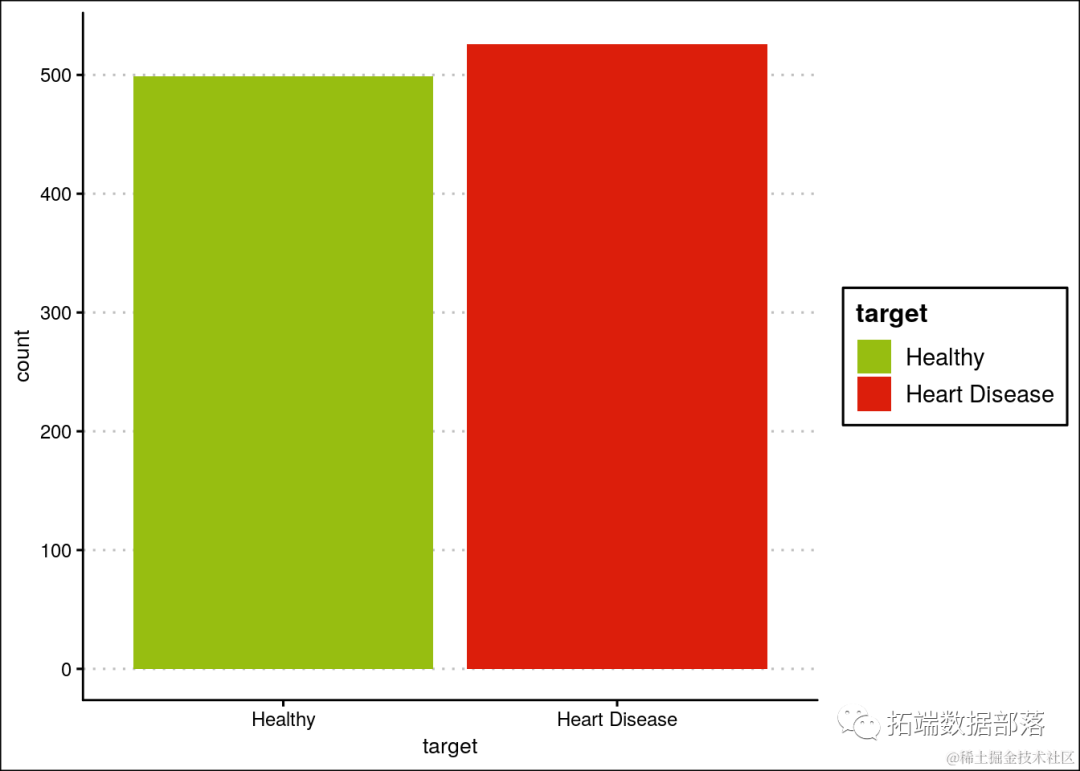
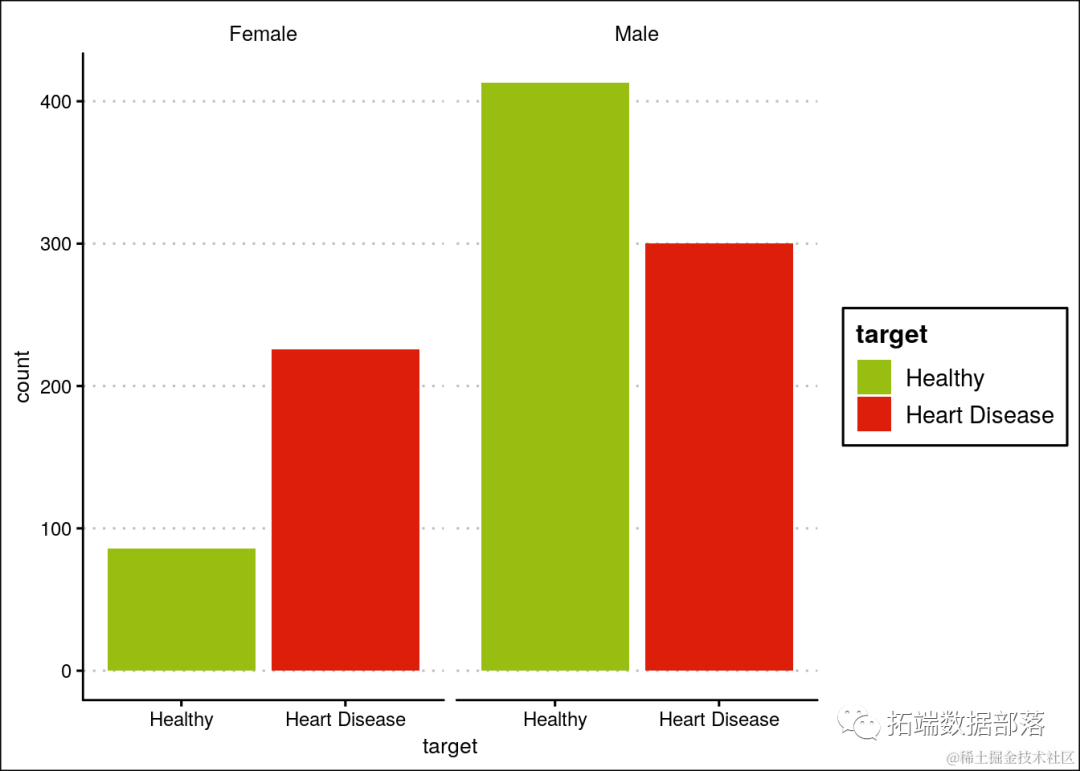
健康人和心脏病患者的观测总数。
ggplot(heartDiseaseData,aes(t...
女性心脏病的发病率高于男性
ggplot(heartDiseaseData,aes(target, fill=target)) +
...
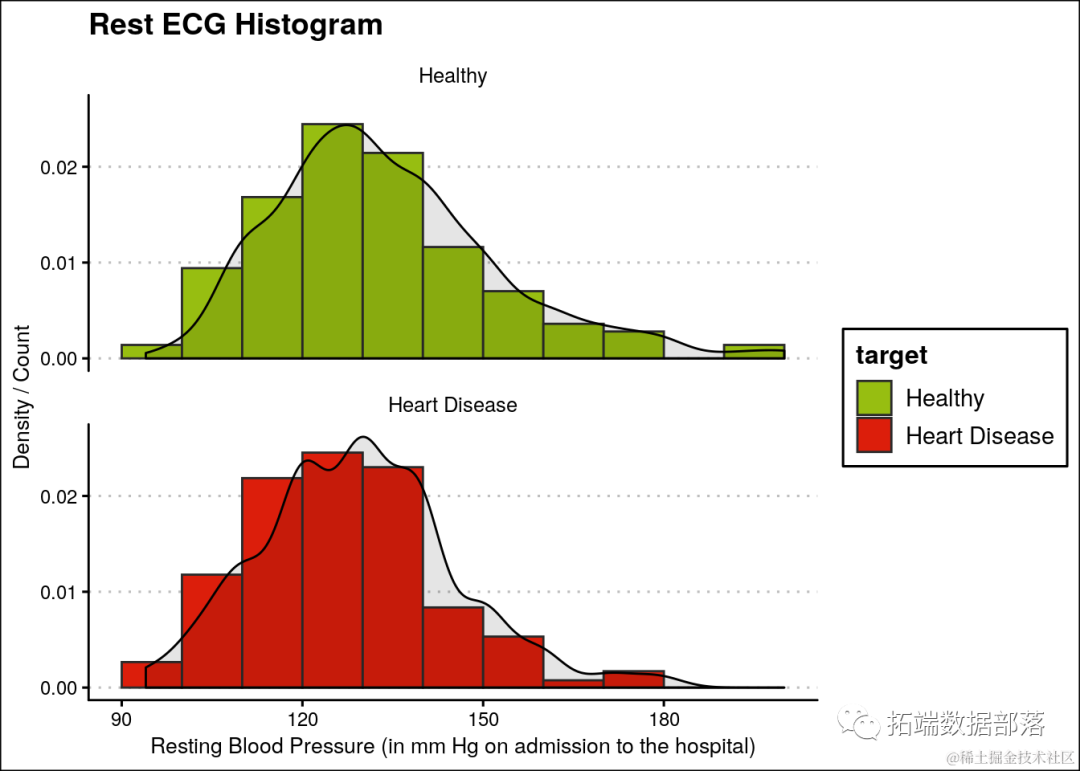
可以观察到,健康人和患有心脏病的人的 Rest ECG 分布没有明显差异。
ggplot(heartDiseaseData,aes(trestbps, fill=target)) +
geom_histogram(aes(y=..density..),breaks=seq(90, 200, by=10), ...
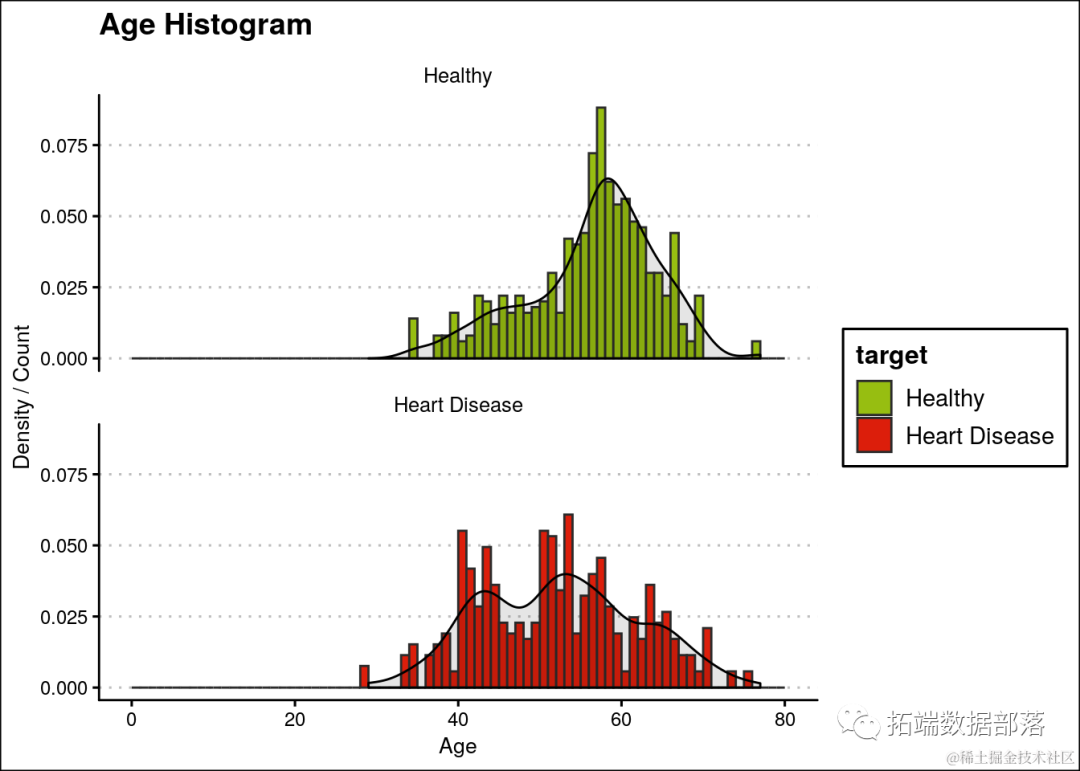
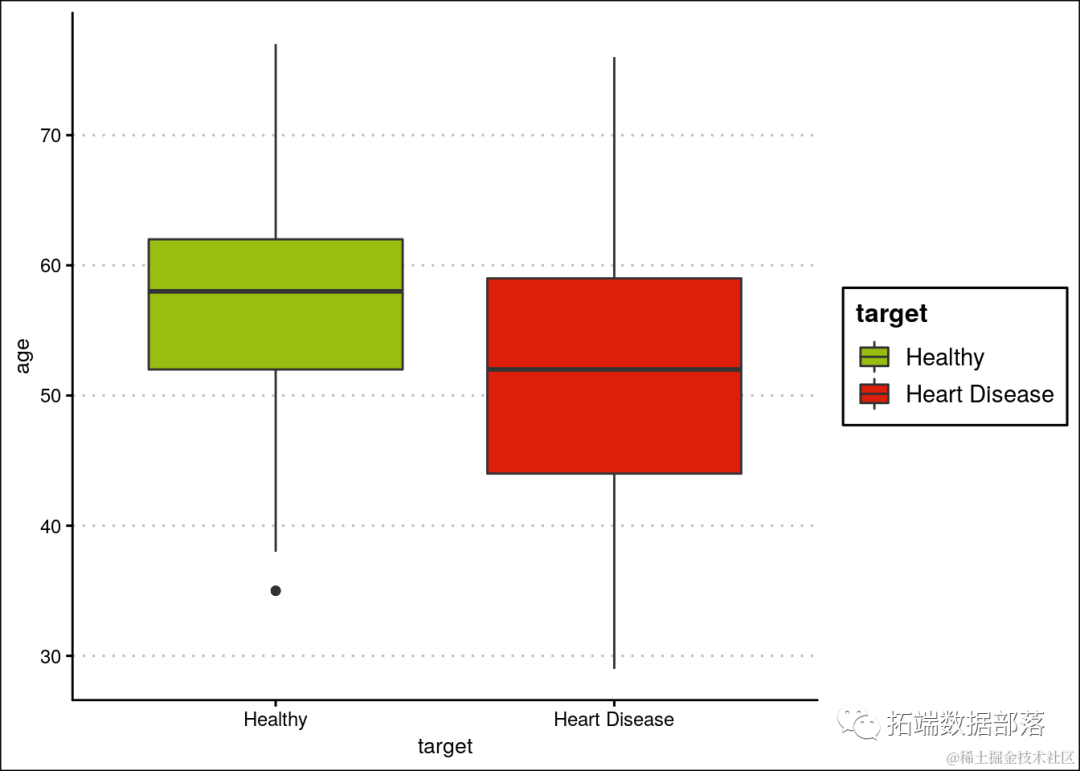
可以观察到心脏病在各个年龄段均匀分布。此外,患者的中位年龄为56岁,最年轻和最年长的患者分别为29岁和77岁。可以从图表中观察到,患有心脏病的人的中位年龄小于健康人。此外,患心脏病的患者的分布略微倾斜。因此,我们可以将年龄作为一个预测特征。
ggplot(heartDiseaseData,aes(age, fill=target)) + ...
ggplot(heartDiseaseData,aes(x=target, y=age, fill=target)) +
...
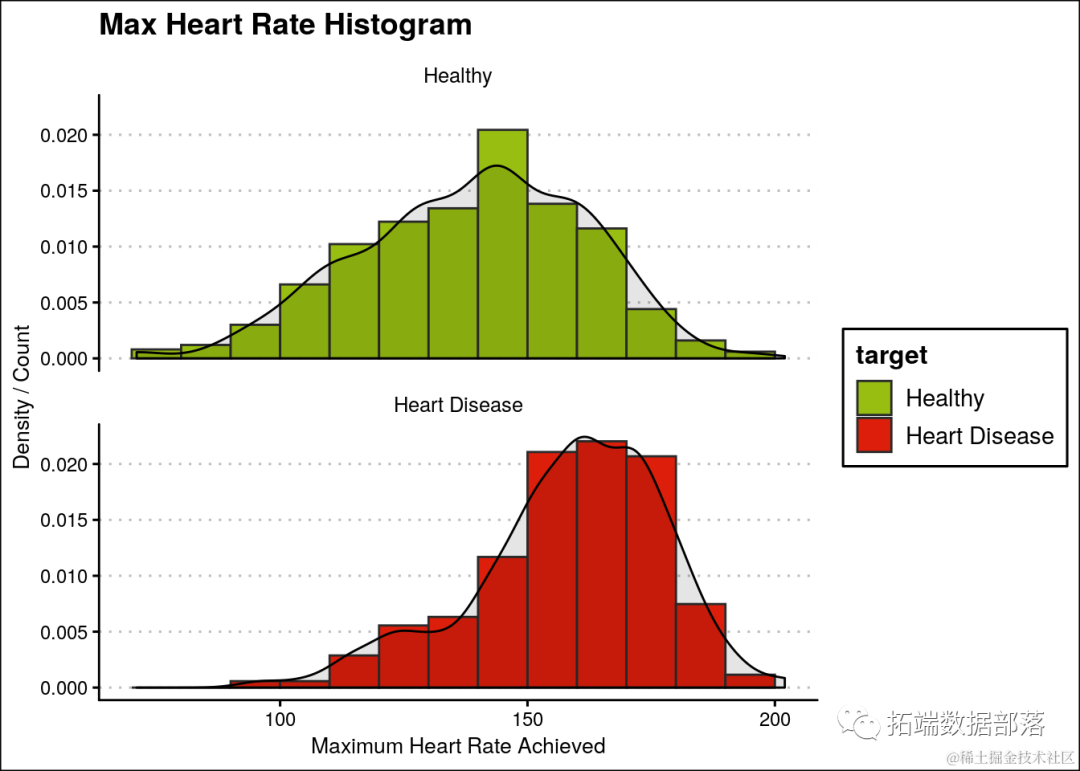
此外,患有心脏病的人通常具有比健康人更高的最高心率。
ggplot(heartDiseaseData,aes(thalach, fill=target)) +
...
ggtitle("Max Heart Rate Histogram")
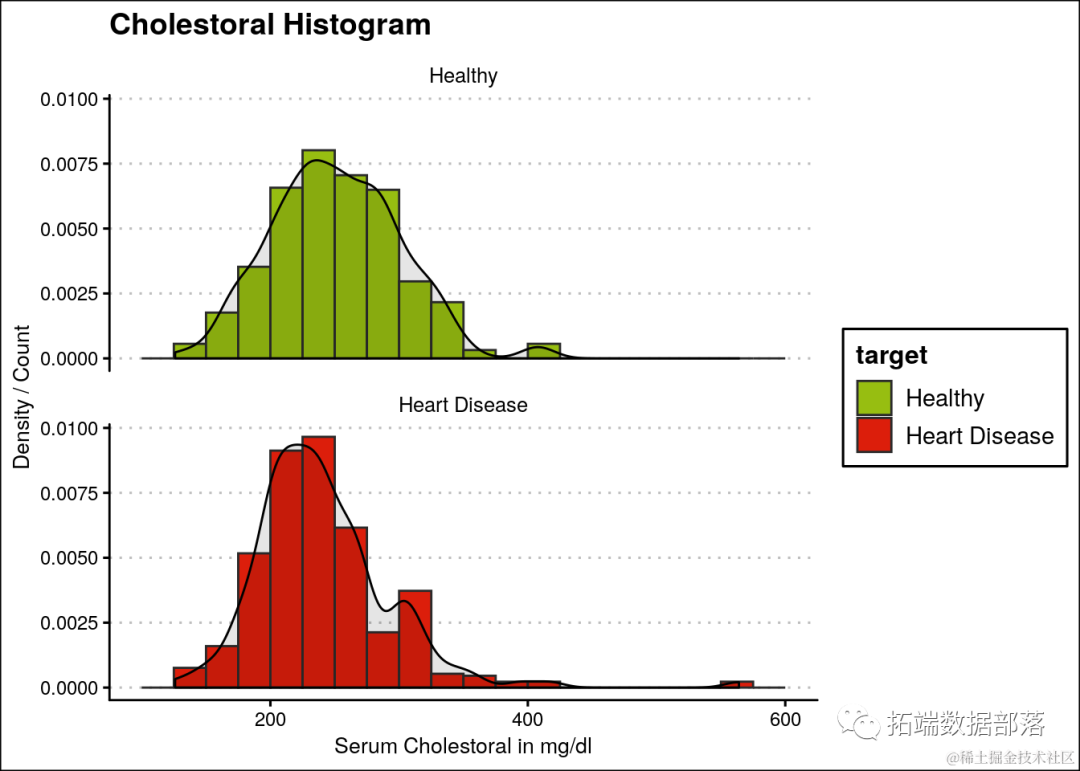
此外,可以观察到大多数患有心脏病的人其血清胆固醇在200-300 mg/dl范围内。
ggplot(heartDiseaseData,aes(chol, fill=target)) +
...
大多数心脏病患者的ST段压低为0.1。


ggplot(heartDiseaseData,aes(oldpeak, fill=target)) + geom_histogram(aes(y=..density..),breaks=seq(0, 7, by=0.1), ...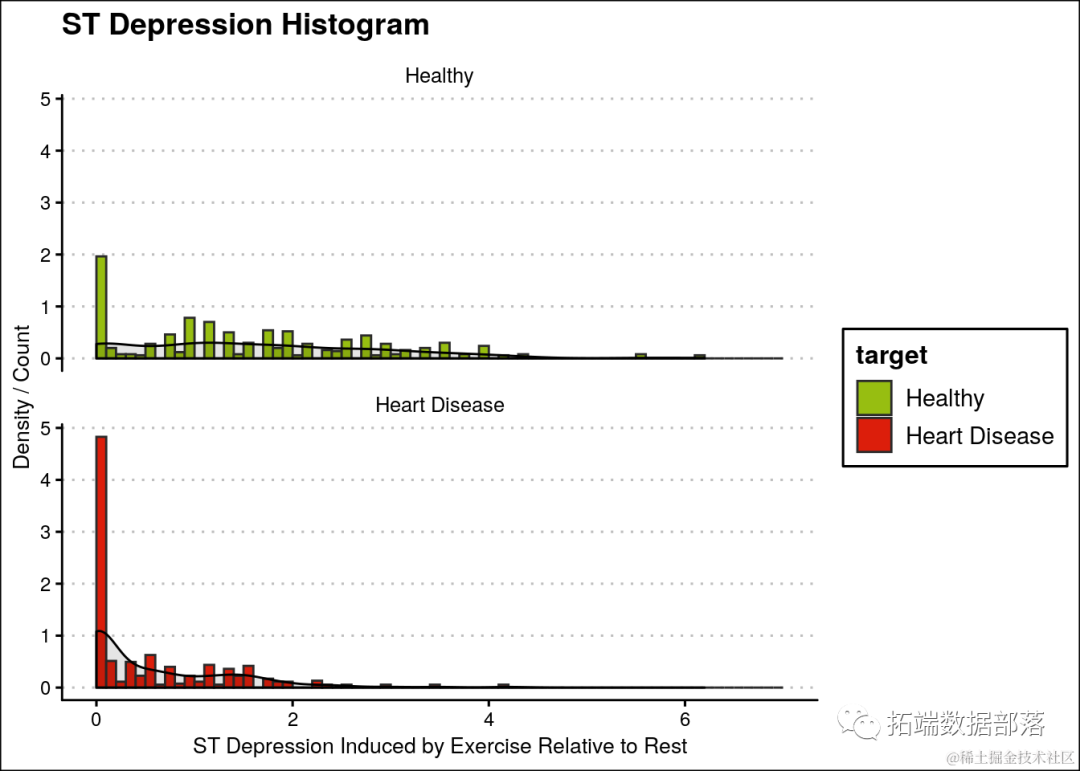
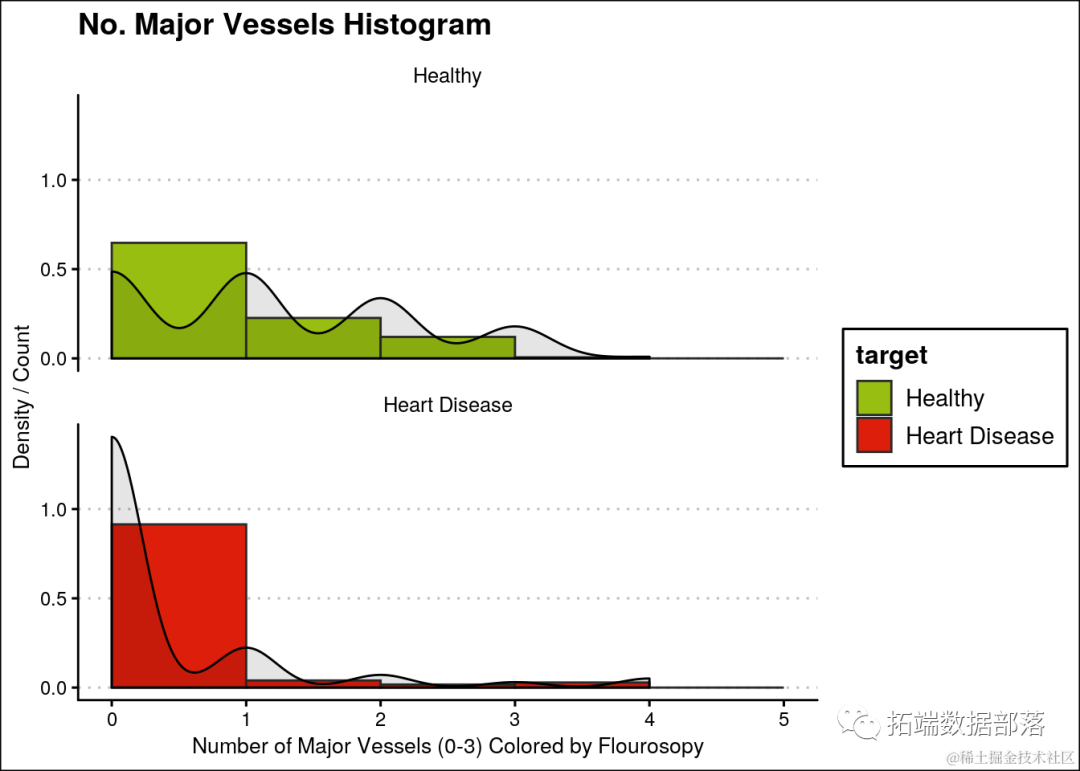
大多数拥有0个主要血管的人患有心脏病。
ggplot(heartDiseaseData,aes(ca, fill=target)) +
geom_histogram(aes(y=..density..),breaks=seq(0, 5, by=1), ...
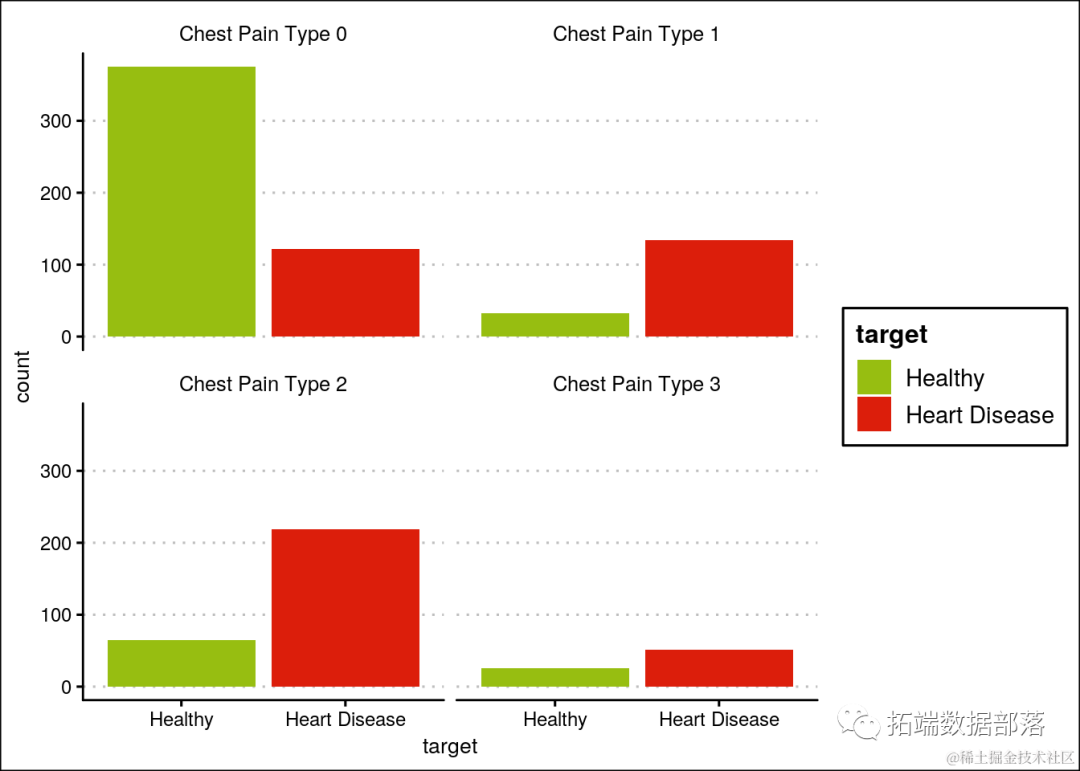
大多数患有心脏病的人胸痛类型为1或2。
ggplot(heartDiseaseData,aes(target, fill=target)) +
...
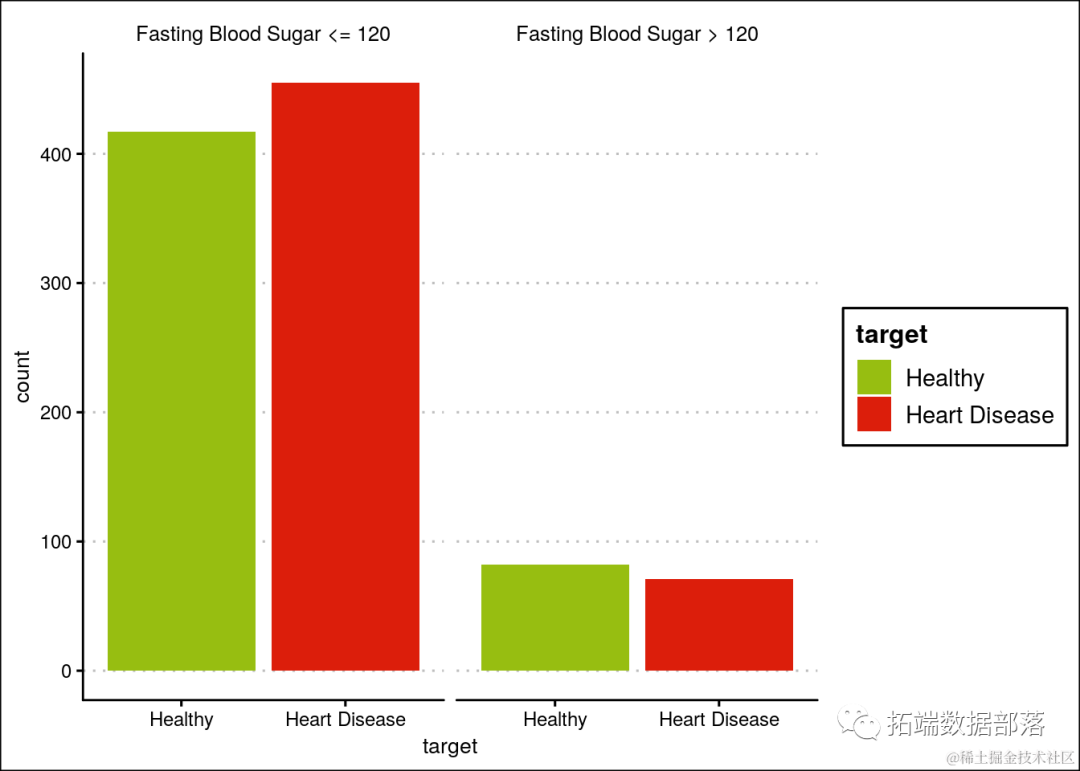
空腹血糖没有明显差异。
ggplot(heartDiseaseData,aes(target, fill=target)) +
...
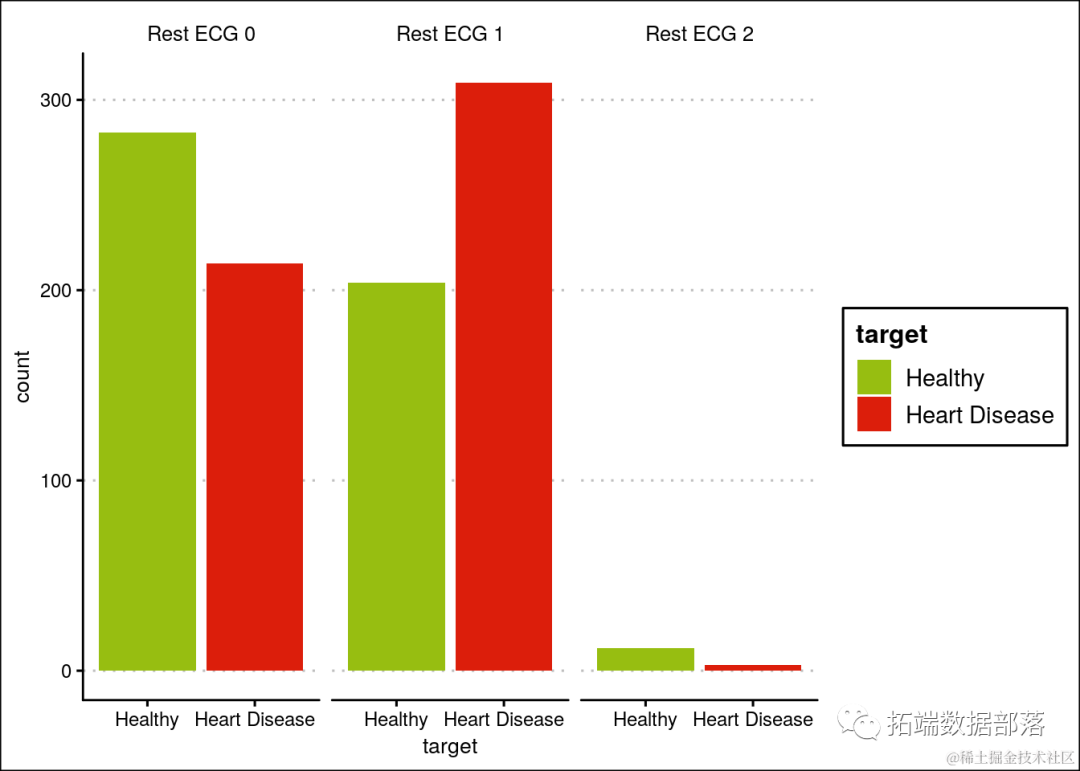
拥有静息心电图异常类型1的人患心脏病的可能性较高。
ggplot(heartDiseaseData,aes(target, fill=target)) +
...
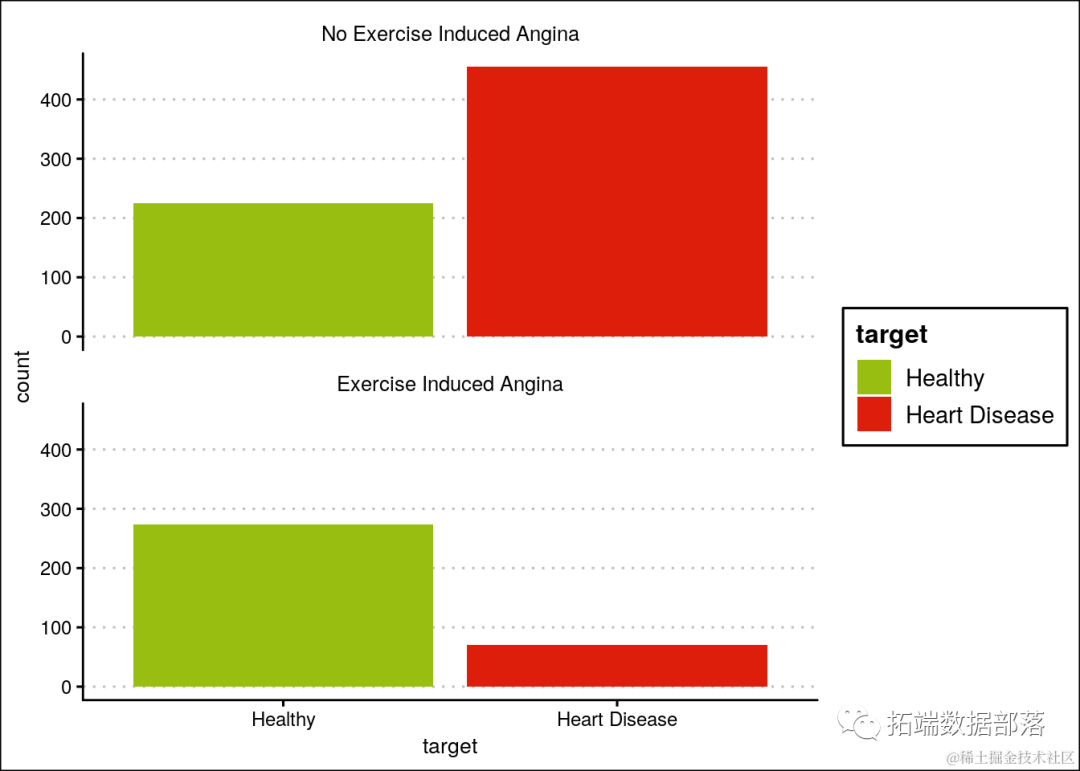
没有运动诱发性心绞痛的人患心脏病的可能性较高。
ggplot(heartDiseaseData,aes(target, fill=target)) +
...
scale_fill_manual(values=c("#97BE11","#DC1E0B"))
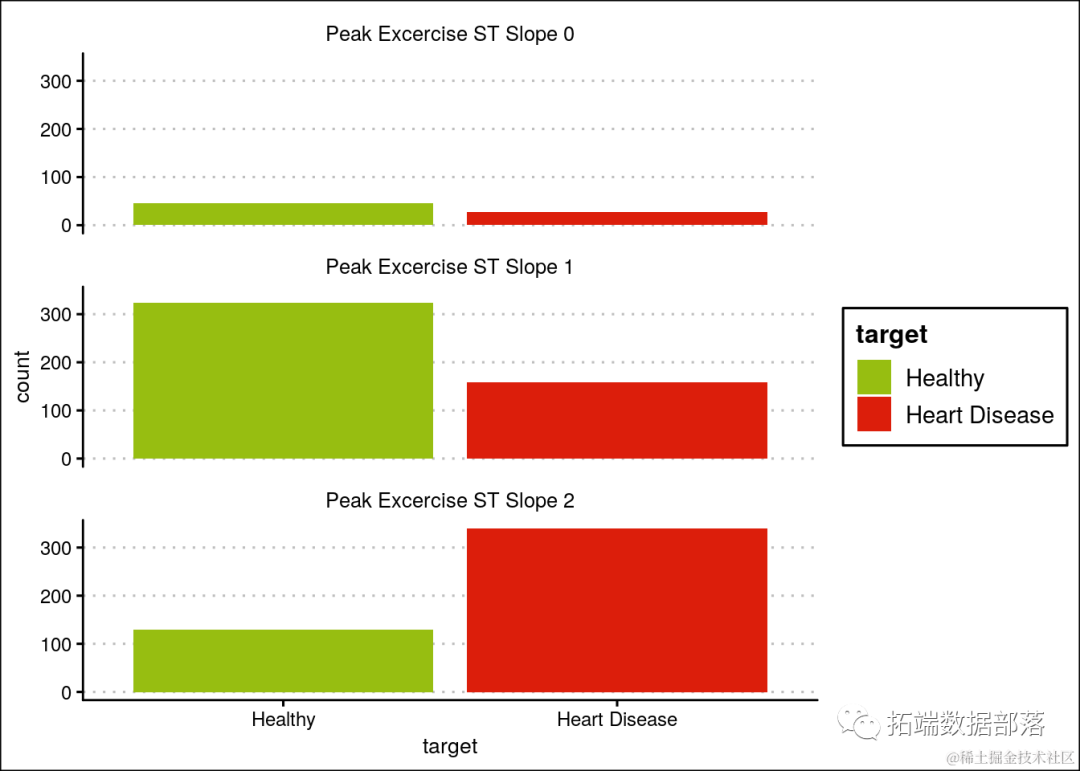
具有最高斜率2的人患心脏病的可能性更高
R
ggplot(heartDiseaseData, aes(target, fill=target)) +
...
scale_fill_manual(values=c("#97BE11", "#DC1E0B"))
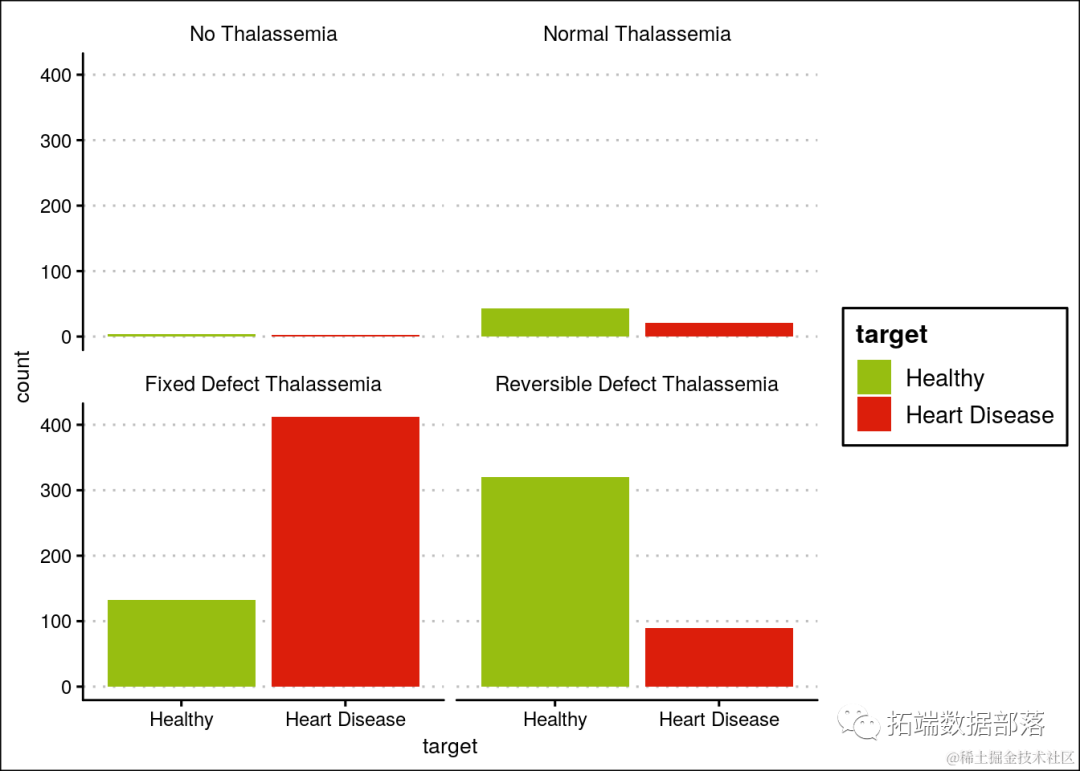
具有固定缺陷地中海贫血的人患心脏病的可能性更高
R
ggplot(heartDiseaseData,aes(target, fill=target)) +
...
scale_fill_manual(values=c("#97BE11","#DC1E0B"))
可以观察到仅有少数参数,如胸痛类型、性别、运动诱发心绞痛、血管数量和ST段压低,对结果有显著影响。因此,可以舍弃其他参数。
R
log <- glm(...
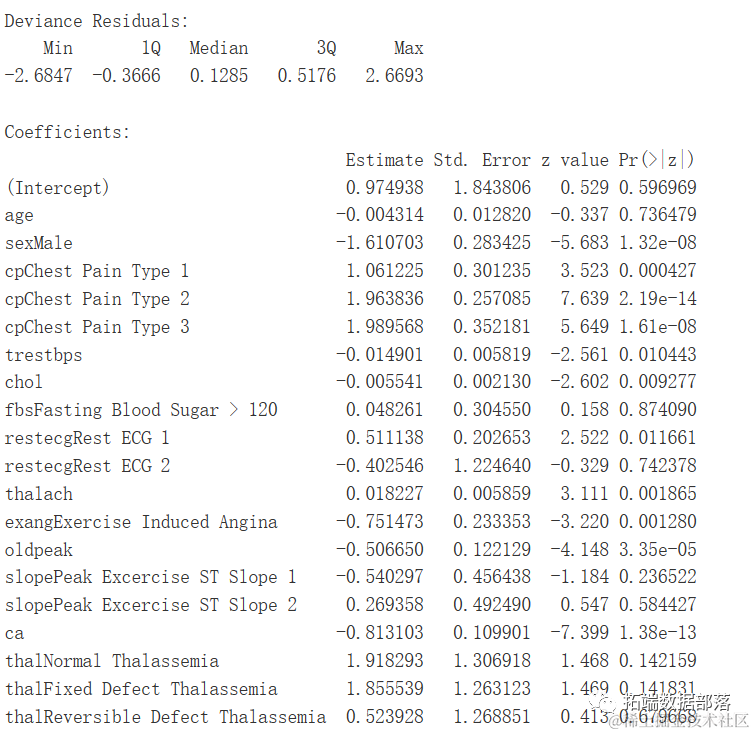

显著特征的总结
R
d <- heartDiseaseDa...
逻辑回归
R
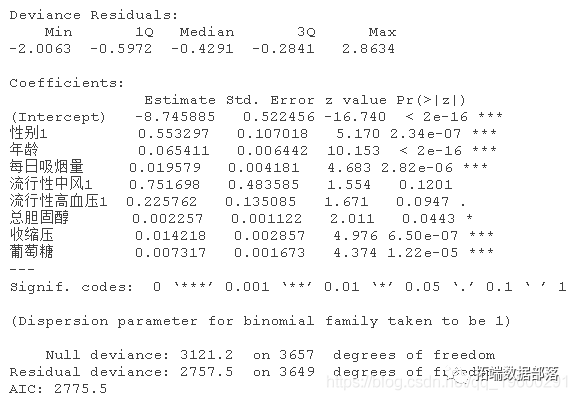
log <- glm(...=binomial)
summary(log)
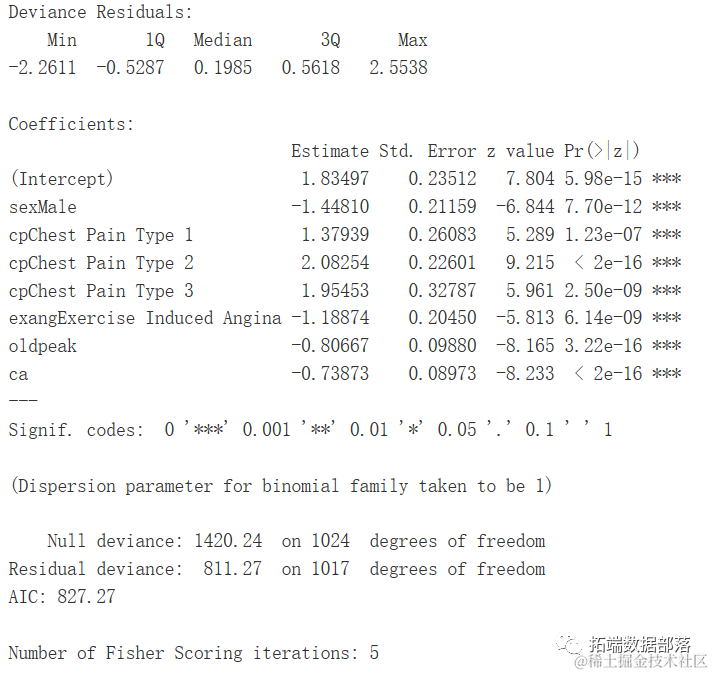
R
log.df <- tidy...
观察表明,如果个体患有2型或3型胸痛,患心脏病的可能性更高。随着血管数量、运动诱发心绞痛、ST段压低和男性性别数值的增加,患心脏病的可能性较低。
R
log.df %>%
mutate(term=reorder(term,estimate)) %>%
...
geom_hline(yintercept=0) +
coord_flip()
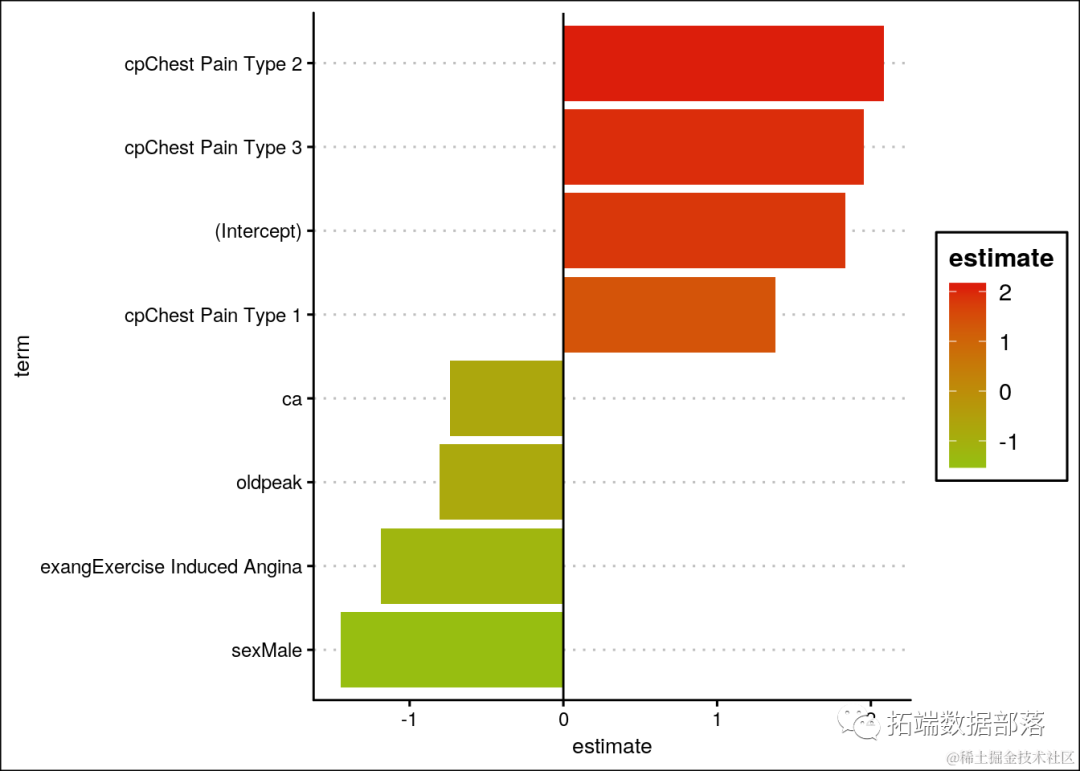
随着ST段压低值的增加,患心脏病的可能性降低。随着血管数量的增加,女性患心脏病的可能性降低,而男性的可能性增加。
逻辑回归
R
data <- d
set.seed(1237)
train <- sample(nrow(data), .8*nrow(data), replace = FALSE)
...
#调整参数
fitControl <- trainControl(method = "repeatedcv",
...
TrainSet$target <- as.factor(TrainSet$target)
R
gbm.ada.1 <- caret::train(target ~ .,
...
metric="ROC")
gbm.ada.1

ST段压低是最重要的特征,其次是胸痛类型2等等。
varImp(gbm.ada.1)

pred <- predict(gbm.ada.1,ValidSet)
....
res<-caret::confusionMatrix(t...
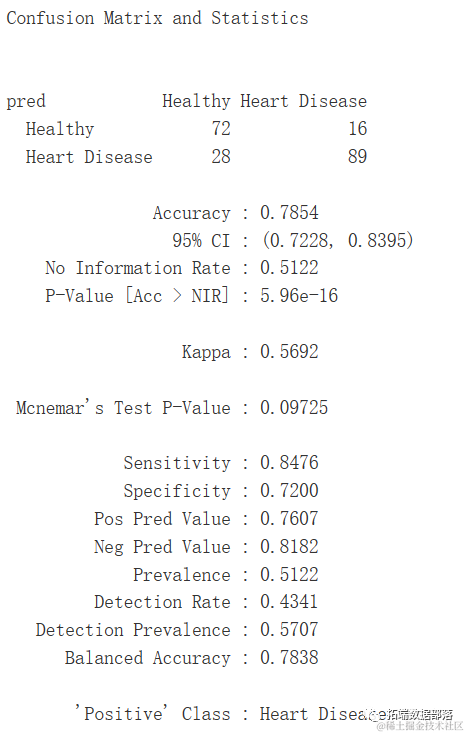
混淆矩阵
ggplot(data = t.df, aes(x = Var2, y = pred, label=Freq)) +
...
ggtitle("Logistic Regression")

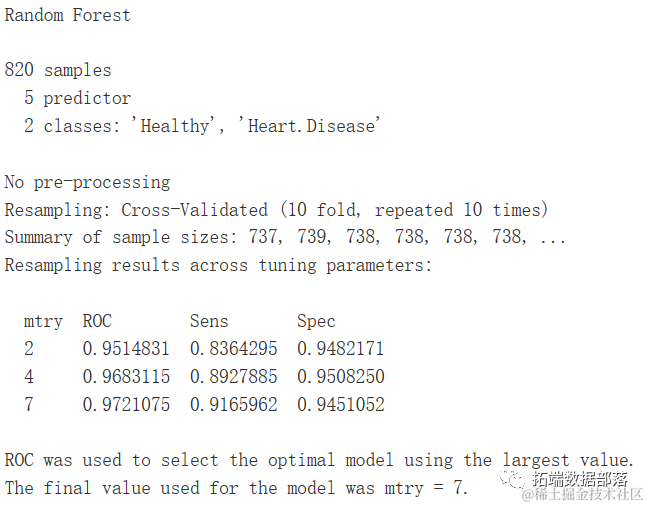
随机森林
gbm.ada.1 <- caret::train(target ~ .,
...
metric="ROC")
gbm.ada.1
变量重要性
varImp(gbm.ada.1)

pred <- predict(gbm.ada.1,ValidSet)
...
res<-caret::confusionMatrix(t, positive="Heart Disease")
res

混淆矩阵
ggplot(data = t.df, aes(x = Var1, y = pred, label=Freq)) +
...
ggtitle("Random Forest")
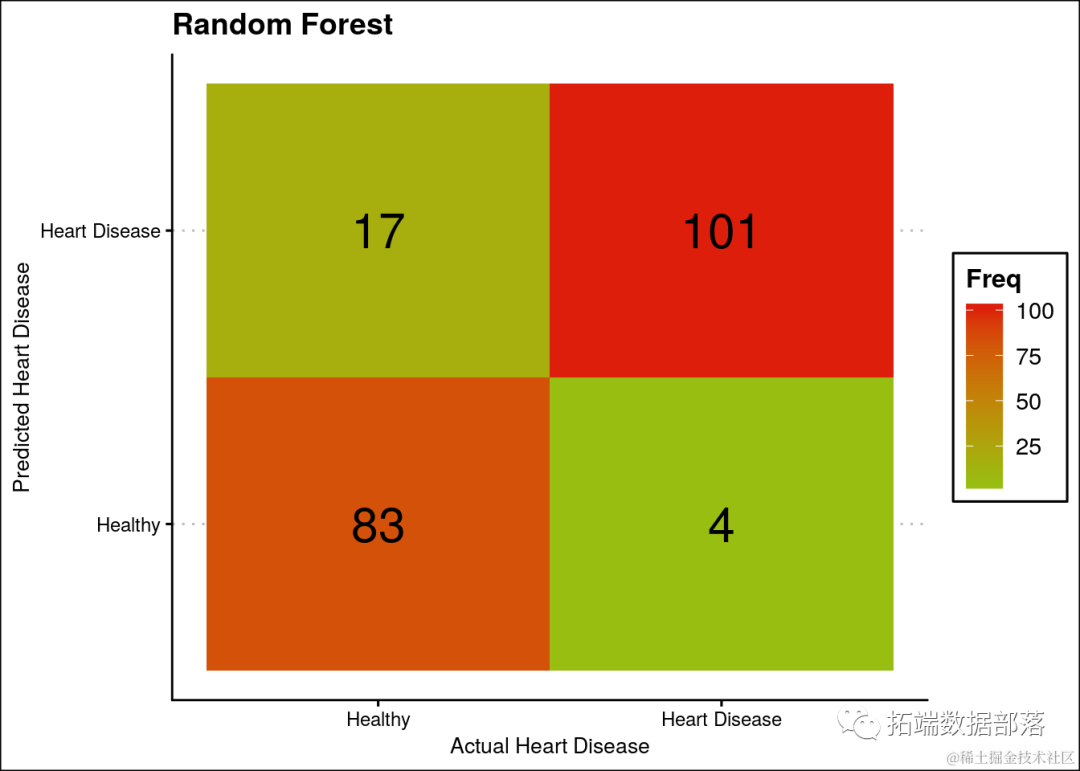
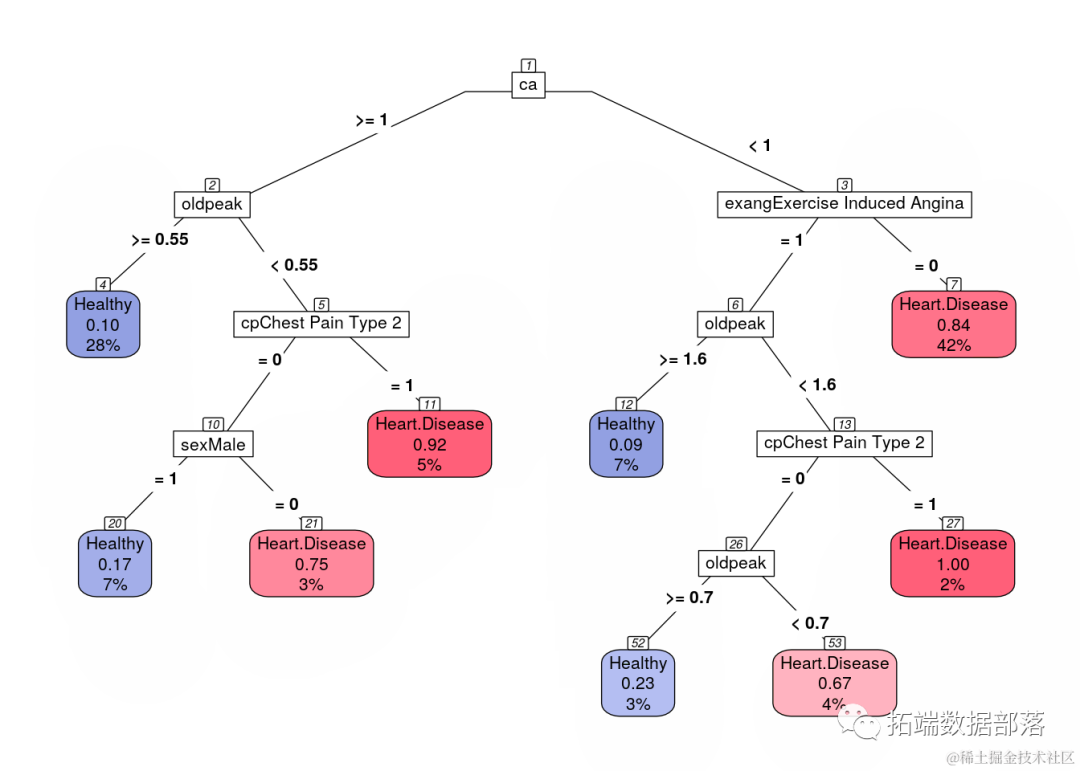
绘制决策树
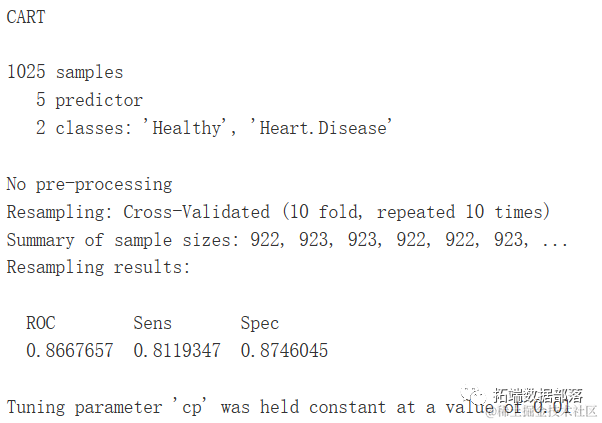
gbmGrid <- expand.grid(cp=c(0.01))
fitControl <- trainControl(method = "repeatedcv",
...
summaryFunction = twoClassSummary)
d$target<-make.names(d$target)
system.time(gbm.ada.1 <- caret::train(target ~ .,
...
tuneGrid=gbmGrid))
gbm.ada.1
varImp(gbm.ada.1)
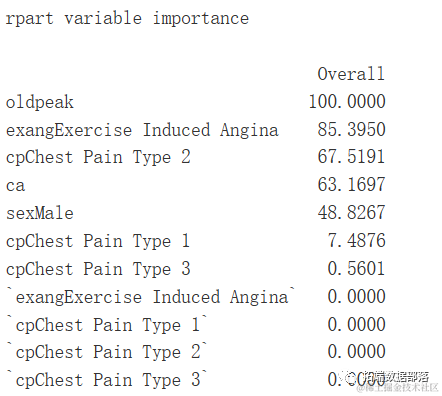
rpart.plot(gbm.ada.1$finalModel,
...
nn=TRUE)
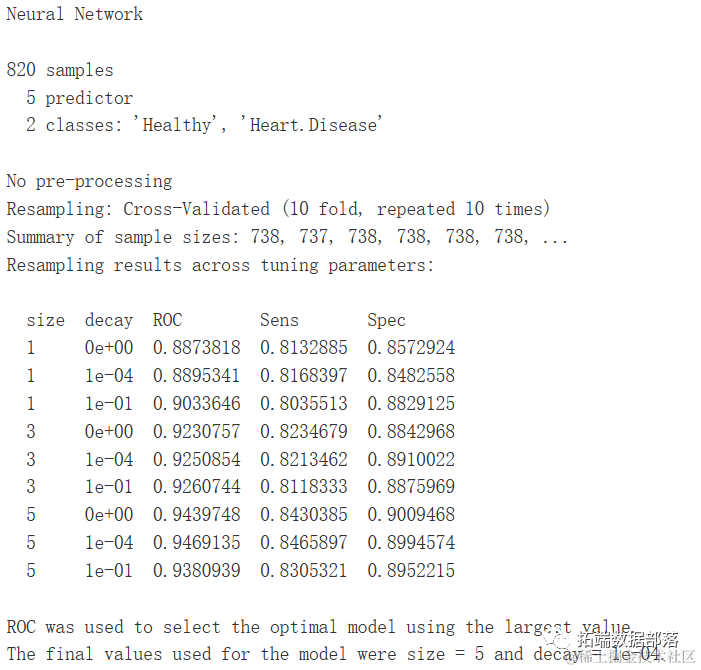
神经网络
fitControl <- trainControl(method = "repeatedcv",
...
summaryFunction = twoClassSummary)
gbm.ada.1 <- caret::train(target ~ .,
...
metric="ROC")

gbm.ada.1
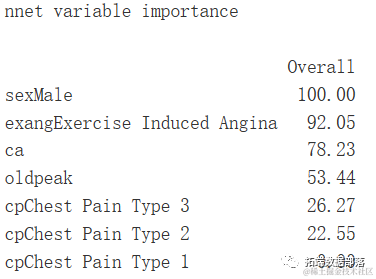
变量重要性
varImp(gbm.ada.1)
pred <- predict(gbm.ada.1,ValidSet)
...
res<-caret::confusionMa...
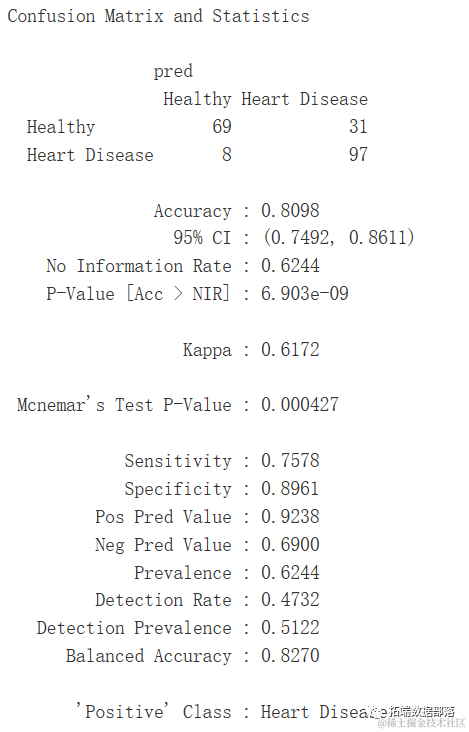
混淆矩阵
混淆矩阵(Confusion Matrix)是用于评估分类模型性能的一种表格。它以四个不同的指标来总结模型对样本的分类结果:真阳性(True Positive, TP)、真阴性(True Negative, TN)、假阳性(False Positive, FP)和假阴性(False Negative, FN)。
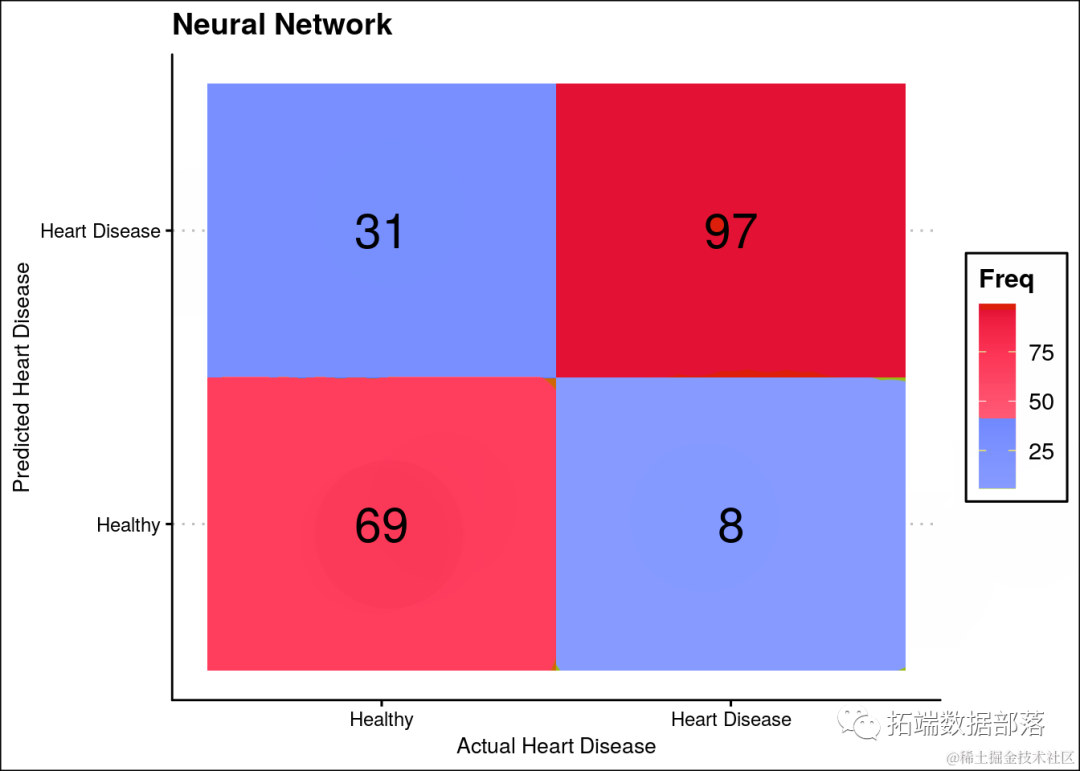
ggplot(data = t.df, aes(x = Var1, y = pred, label=Freq)) +
...
ggtitle("Neural Network")
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/109161
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!