
工欲善其事,必先利其器。
对于强化学习而言,一个好的强化学习框架非常重要。
强化学习的范式更适合金融投资组合管理,后续一段时间应该会专注强化学习应用于金融投资上。
对于初学者而言,易用性是摆在第一位的,我们必须快速跨过入门这一关,而后才是所谓的效率与扩展。
这里我们选择statble-baseline3(下面简称sb3)。
Sb3的安装比较简单:pip
install stable-baselines3 tensorboard。
今天我们来介绍下stablebaseline3。
安装比较简单:pip install stable-baselines3 tensorboard
我这里使用的是1.6.2版本。
01 hello baseline3
from stable_baselines3 import A2C
model = A2C("MlpPolicy", "CartPole-v1", verbose=1, tensorboard_log="./a2c_cartpole_tensorboard/")
model.learn(total_timesteps=10000)
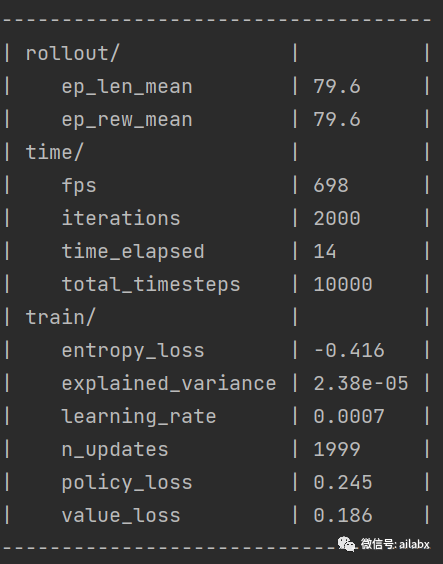

02 整合tensorboard
tensorboard –logdir ./a2c_cartpole_tensorboard/
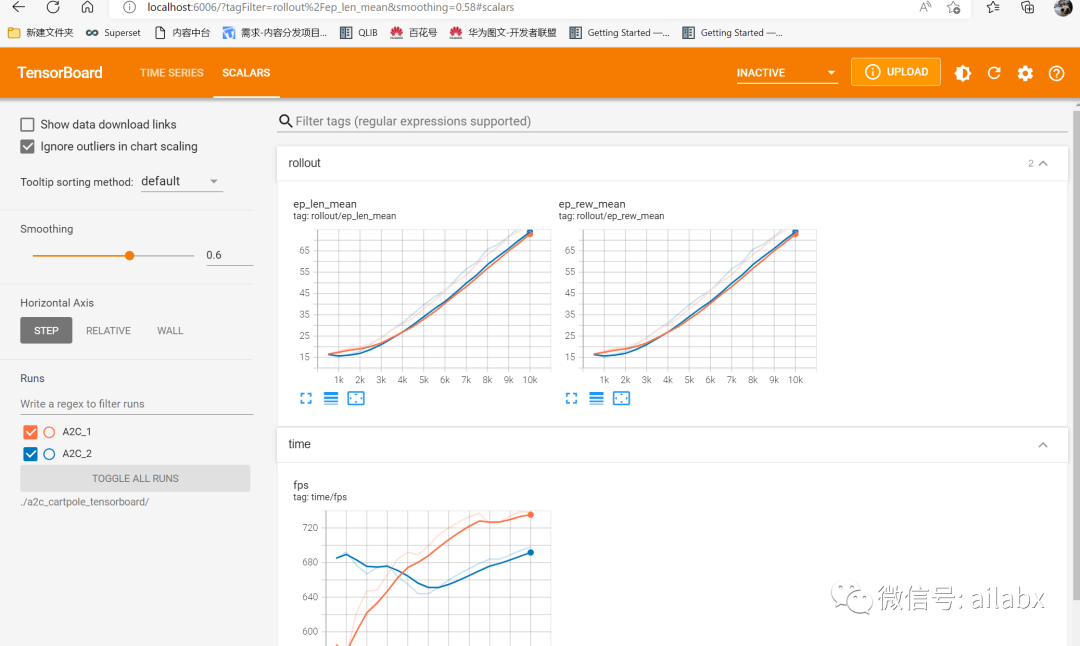
03 自定义env
把强化学习应用于金融投资,一定是需要自定义自己的强化学习环境。
而sb3的自定义环境只需要遵守open
ai的gym标准即可。
import gym import numpy as np from gym import spaces class FinanceEnv(gym.Env): metadata = {"render.modes": ["human"]} def __init__(self): super(FinanceEnv, self).__init__() # 定义动作与状态空间,都是gym.spaces 对象 # 例:使用离散空间: N_DISCRETE_ACTIONS = 2 self.action_space = spaces.Discrete(N_DISCRETE_ACTIONS) # Example for using image as input (channel-first; channel-last also works): N_CHANNELS = 3 HEIGHT = 28 WIDTH = 28 self.observation_space = spaces.Box(low=0, high=255, shape=(N_CHANNELS, HEIGHT, WIDTH), dtype=np.uint8) def step(self, action): observation = self.observation_space.sample() reward = 1.0 done = True info = {} return observation, reward, done, info def reset(self): observation = self.observation_space.sample() #print(observation) return observation # reward, done, info can't be included def render(self, mode="human"): pass def close(self): pass
1、继承gym.Env。
2、定义动作与状态空间,都是gym.spaces 对象
3、重点实现step与reset两个函数
Step就是传入一个动作,并计算reward,返回新的state。
Reset是环境重置初始化。
检查环境:
from stable_baselines3.common.env_checker import check_env env = FinanceEnv() check_env(env)
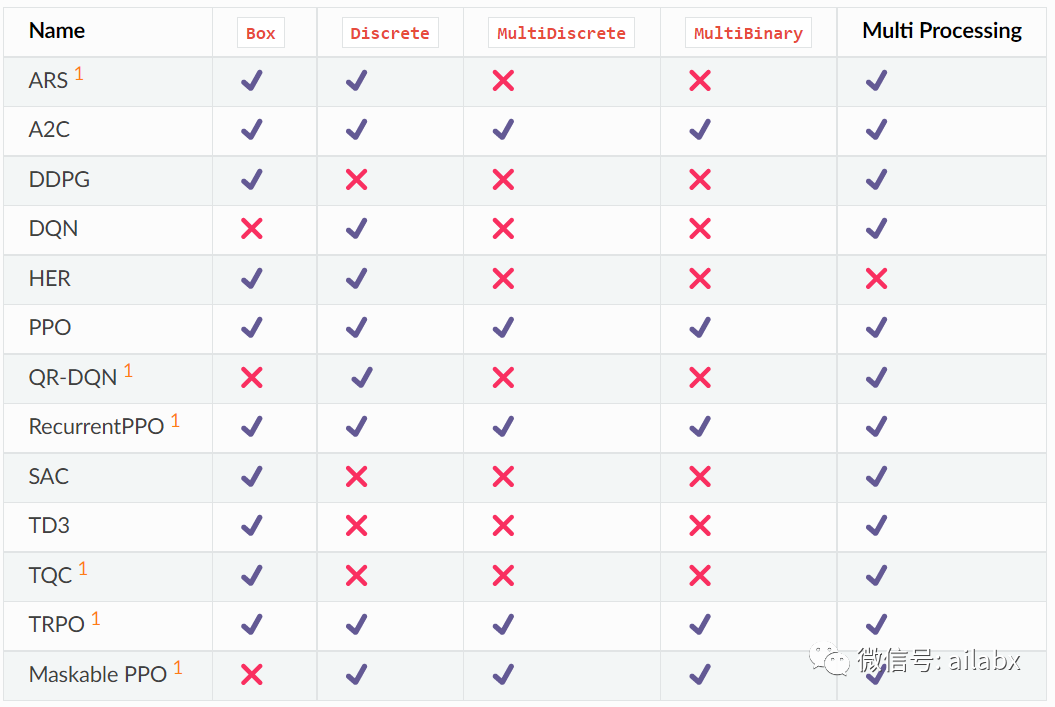
04 sb3已实现的算法
DQN和QR-DQN仅支持离散的动作空间;DDPG,SAC,TD3等仅支持连续的动作空间。
离散的空间对应的金融投资就是:做多,平仓或做空等;而连续空间可以做多资产投资组合配置,直接给出权重。
下面是sb3官网列出的当前已经实现的强化学习算法,以及它们的特点和适用场景。对于投资场景肯定是够用了。还有那句话,数据和特征工程决定了模型的上限,而模型只是帮忙逼近这个上限。这句话对于人工智能应用总体有效。改过模型很难带来的效果有限。所以,我们有追求还不错的模型即可。
05 yahoo!金融数据源
Tushare主要是A股的股票市场数据为主,而面向全球,常用的一个数据来源是yahoo!财经数据源。
它的api接口库是yfinance,直接pip install yfinance即可。
使用也不复杂:

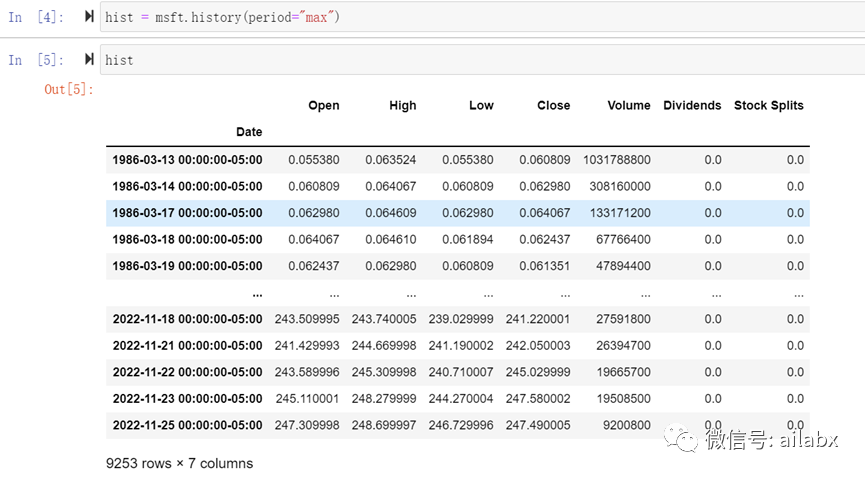
可以看出来,我们使用yahoo!接口很容易得到股票的原始数据,但这里没有复权价值,需要自己计算(比较麻烦)。
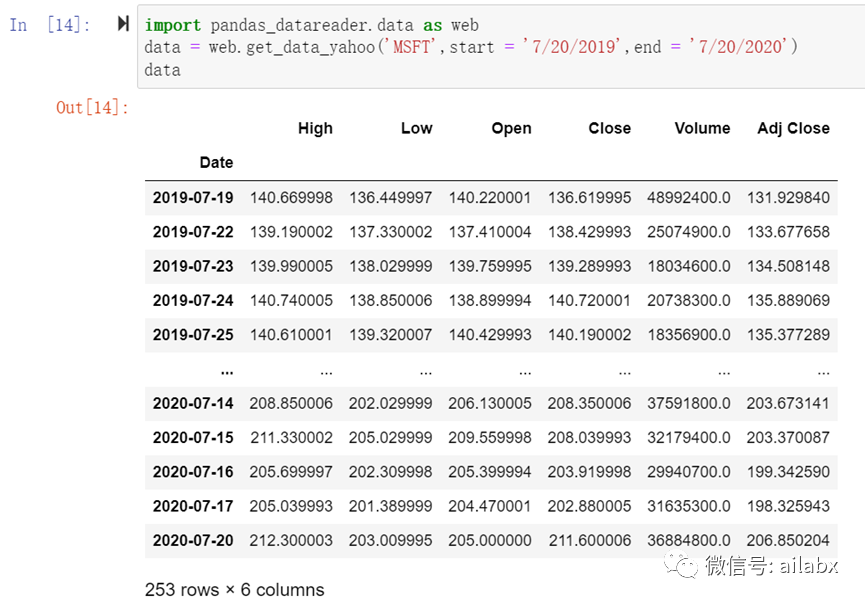
所以,我们使用一个更高层次的接口——pandas_datareader。
06 pandas_datareader
Pandas_datareader从pandas里拆分出来,专注金融数据获取。它支持多个数据源。它支持有常见的股票和基金等常见金融资产的交易数据来源,也有货币交易数据(FRED),以及常见的宏观经济数据(OECD和World Bank)
安装同样简单:pip install pandas_datareader即可。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104203
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!