
转债与ETF搁一块来比较,转债是可以全市场选债,因为横向都可以对比,选择性价比,质地最优的持有。
场外以主动型基金为主,买的是服务,比如优质固收+、主动型基金等。
ETF是不同的。
A股指数与海外QDII的逻辑就不一样,就算是多因子,也不具备横向可比性。另外场内基金里还有债券型,LOF(主动型)。就算是纯粹宽基、行业、smart beta(主题、策略)这样的ETF。
做量化数据是基础,但这个数据是需要持续更新了,如何方便读,全市场回测如何做到速度快。这个系统的设计还是很重要,考验能力的。
量化数据,包含基本面数据、量化数据等等。按因子列存是个不错的选择。
数据建立按代码、因子的方式。可以是增量(不存在则写入),更新(删了重建)。
数据构建无论在量化投资、机器学习,人工智能领域都非常重要。
传统的大数据编排像airflow,重在提供不同数据存储之间的能力,比如hadoop,spark等。现代的数字驱动的栈更倾向于像 prefect和dagster。
prefect大致的观感是去中心化的,它的server就是一个登记中心,只存储一些meta信息,调度信息,任务的代码与执行都是agent自己完成。agent自己向server提交自己的位置和代码。然后server会把调度信息发给agent进行执行,大致是这样的一个架构。这导致prefect无论通过“手动” trigger一个任务。比如“手工补数”这样的需求。
prefect从1到2进行了比较大的重构,无论是UI上还是代码上,应该是无法向后兼容的。
——Prefect coordinates your dataflow。Prefect的定位是“协调”您的数据流。包括定位任务,重试,日志,缓存,通知与监控。


dagster的定位似乎也“重构”了——Dagster is used to build and maintain data assets. ——用来构建和维护数据“资产”。之初使用的时候,从op和job开始,就是执行各种操作。现在它把assets置于这个技术栈最前边,弱化op与job。
import pandas as pd import requests from dagster import MetadataValue, Output, asset @asset def hackernews_top_story_ids(): """ Get top stories from the HackerNews top stories endpoint. API Docs: https://github.com/HackerNews/API#new-top-and-best-stories """ top_story_ids = requests.get( "https://hacker-news.firebaseio.com/v0/topstories.json" ).json() return top_story_ids[:10] # asset dependencies can be inferred from parameter names @asset def hackernews_top_stories(hackernews_top_story_ids): """Get items based on story ids from the HackerNews items endpoint""" results = [] for item_id in hackernews_top_story_ids: item = requests.get( f"https://hacker-news.firebaseio.com/v0/item/{item_id}.json" ).json() results.append(item) df = pd.DataFrame(results) # recorded metadata can be customized metadata = { "num_records": len(df), "preview": MetadataValue.md(df[["title", "by", "url"]].to_markdown()), } return Output(value=df, metadata=metadata)
通过 dagit -f 直接启动单文件:
dagit -f hello-dagster.py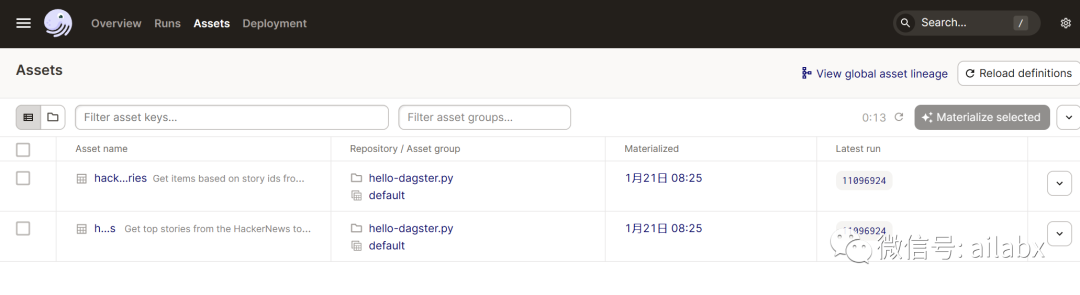
点击“物化”就是执行asset函数,默认存储在本地。
这里的逻辑比较简单,第一个从远程api中取top 10的id,然后把文章读回来。
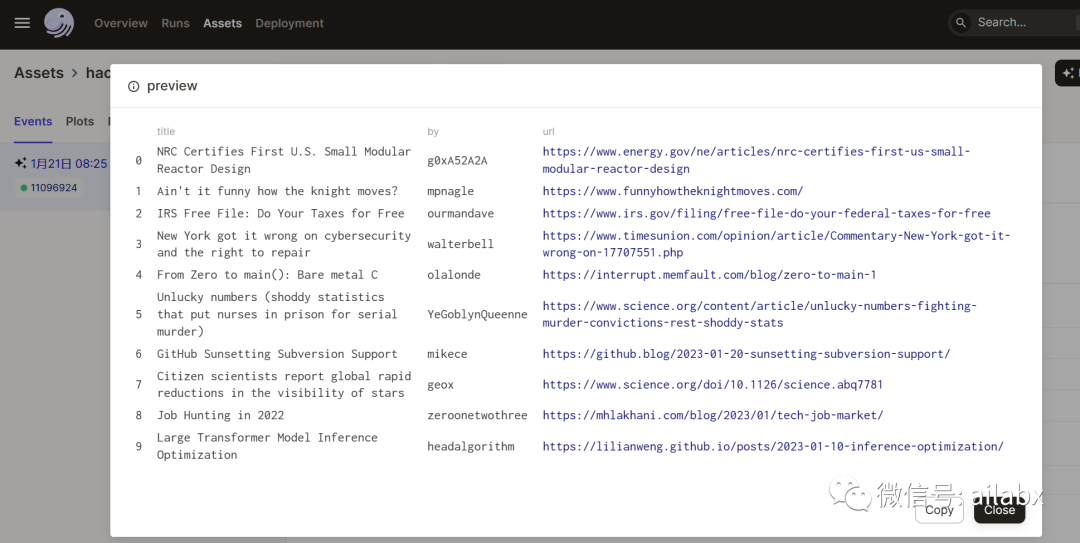
这里是“让数据工程化”的过程。
默认缓存在本地文件中。
——数据驱动的应用中,本地缓存机制是有用的。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104170
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!