
前面几天的文章:
年化41.4%的指数多因子轮动与年化26.5%大类资产动量轮动,准备实盘跟踪。(代码下载)
年化24.9%:基于动量、波动率、乖离率的多因子合成策略的指数轮动。(代码+数据下载)
我们通过等权合成算法,对行业指数进行了轮动,效果还不错。
今天我们尝试使用
来回测。
代码在工程如下位置:

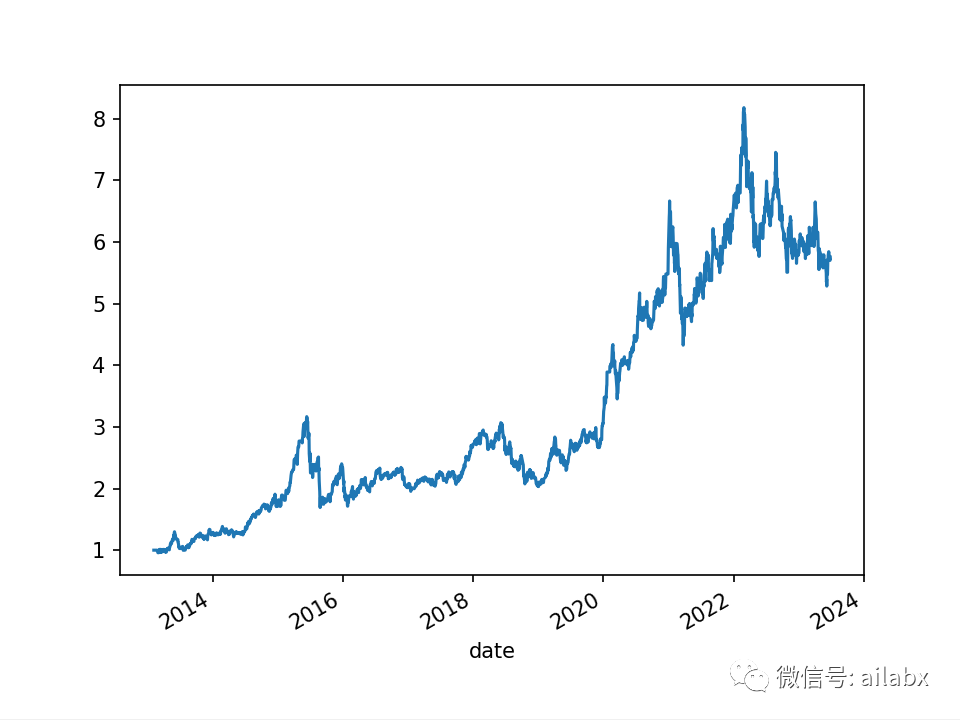
from engine.datafeed.dataset import DataSet from engine.env import Env from engine.config import etfs_indexes from engine.datafeed.dataloader import Hdf5Dataloader from engine.config import DATA_INDEX from engine.datafeed.alpha import AlphaLit loader = Hdf5Dataloader(symbols=etfs_indexes.values()) loader = Hdf5Dataloader(etfs_indexes.values(), start_date="20130101") fields = ['roc(close,20)', 'std(volume,20)', 'bias(close,20)', 'roc(close,5)', 'std(volume,5)', 'bias(close,5)', 'rank(roc_5)', 'rank(std_5)', 'rank(bias_5)', 'rank(roc_20)', 'rank(std_20)', 'rank(bias_20)', 'rank(roc_20)+rank(bias_20)+rank(roc_5)+rank(bias_5)-rank(std_20)-rank(std_5)', "shift(close, -2)/shift(open, -1) - 1", "qcut(label_c, 6)", ] names = ['roc_20', 'std_20', 'bias_20', 'roc_5', 'std_5', 'bias_5', 'rank(roc_5)', 'rank(std_5)', 'rank(bias_5)', 'rank(roc_20)', 'rank(std_20)', 'rank(bias_20)', 'rank', "label_c", 'label', ] df = loader.load(fields=fields, names=names) from engine.algo.algos import * from engine.algo.algo_weights import * from engine.algo.algo_model import ModelWFA from engine.models.lgb_ranker import LGBRanker from engine.env import Env model = LGBRanker(name='滚动回测——排序', load_model=False, feature_cols=['rank(roc_20)', 'rank(std_20)', 'rank(bias_20)', 'rank(roc_5)', 'rank(std_5)', 'rank(bias_5)' ]) # model.train(ds.data, '2022-01-01') df.dropna(inplace=True) env = Env(df) env.set_algos([ RunDays(2), ModelWFA(model=model), SelectTopK(drop_top_n=1, K=1, order_by='pred_score', b_ascending=False), WeightEqually() ]) env.backtest_loop() #env.save_results() env.show_results()
我们使用toml的做策略持久化的配置文化 ,比起qlib的yaml要优雅得多。toml与dict字典基本等价,而dict可以与nametumple命名元组对等。这样我们可以使用命名元组做做配置。
import toml from engine.config import DATA_PRJ from typing import NamedTuple, List class Project(NamedTuple): name: str = "" start_date: str = "" end_date: str = "" fields: list = [] names: list = [] names: list = "" benchmarks: list = [] algos: list = [] config = toml.load(DATA_PRJ.joinpath('demo.toml')) print(config) proj = Project(**config) new_proj = Project(names='这是一个测试', benchmarks=['000300.SH'], start_date='20100101', end_date='20100101' ) new_proj.algos.append({'name': 'RunOnce'}) new_proj.algos.append({'name': 'WeightEqually'}) new_proj = new_proj._replace(end_date='20230101') print(toml.dumps(new_proj._asdict())) with open('demo_write.toml', 'w',encoding='utf8') as f: r = toml.dump(new_proj._asdict(), f) print(r)
另一个是关于loguru logger的重定向输出。
loguru可以添加自己的sink,这对于gui非常好,使用console程序时的logger记录可以直接定向到文本框里去输出。
from loguru import logger import json def my_func(message): print(message) logger.add(my_func) logger.debug('你好')
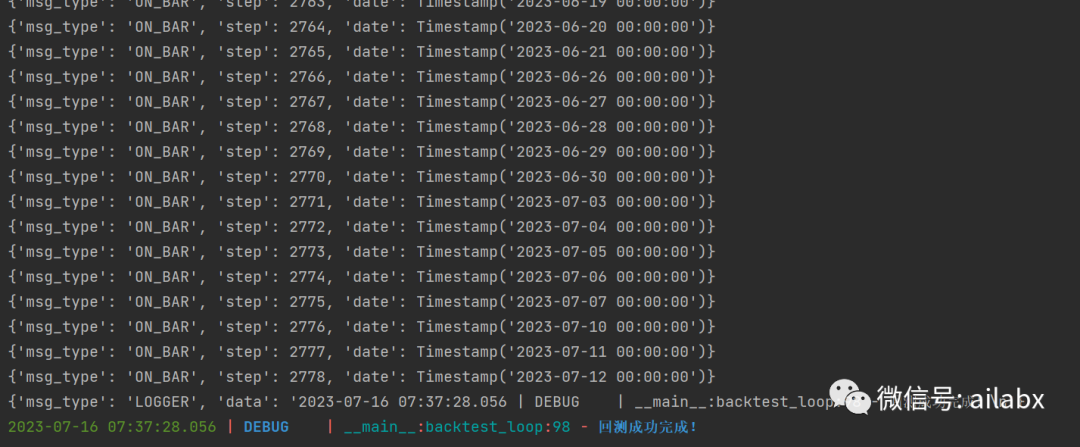
全局的观察者模式:
class GlobalHandler: def __init__(self): self.observers_fns = [] def add_observer_fn(self, fn): self.observers_fns.append(fn) def notify(self, data: dict): for o in self.observers_fns: o(data) g = GlobalHandler() def my_logger_notify(data): g.notify({'msg_type': 'LOGGER', 'data': data}) from loguru import logger logger.add(my_logger_notify)
非常方便日志、状态等内容输出的gui,尤其是跨组件的信息通信。
代码与数据请自行前往星球下载。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104064
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!