
吾日三省吾身。
以自己喜欢的方式过这一生。
昨天我突然想到这句:“以悦人之心,做悦己的事情”。
你做的事情,要对别人有价值,对更多人有价值,对市场有价值,那么市场会给你回报。这叫“取悦他人”的目标,”悦己“,做你自己认同且喜欢,且擅长的事情。
我们在做一件什么事呢?——低门槛快速实验AI量化策略。
我们知道,因子也好,策略也罢,没有永远有效的圣杯。需要不停地观察市场,不断学习,迭代,这时候,需要一个好用的,低成本的策略研发平台。所以我们做“积木式”,“可视化”的策略开发过程。
前面的文章我们主要是围绕ETF、指数多因子轮动,大类资产配置展开。
今天开始我们正式进行A股股票市场。
记住我们的步骤:数据,因子,策略或模型,回测,分析,迭代。
所以,第一步先搞定数据:从tushare直接下载hs300成份股,我们从沪深300开始。你会说这个成份股是一直在变的,没错,但我们只是用它作为一个基准池子,没有特别的影响。一直来就搞4000-5000支股票,数据量大,没必要。
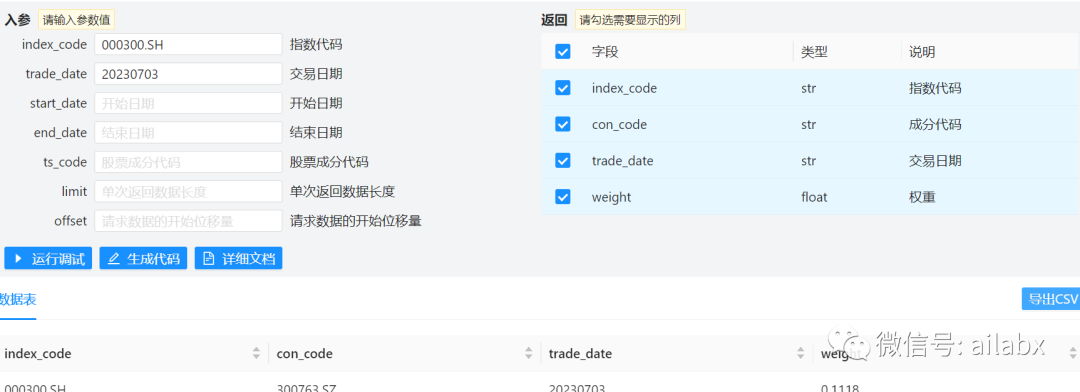

有了300支的清单,我们需要下载历史复权数据。
脚本在这里,把300支股票历史上全量的“后复权”数据保存到本地h5中。
文件400多M了,可能通过git很难下载了。
import akshare as ak import pandas as pd from engine.config import DATA_DIR, DATA_H5 df_codes = pd.read_csv(DATA_DIR.joinpath('hs300.csv').resolve()) codes = df_codes['con_code'] with pd.HDFStore(DATA_H5.resolve()) as s: for i, code in enumerate(codes): symbol = code code = code[:6] print(i, code) df = ak.stock_zh_a_hist(symbol=code, period="daily", adjust="hfq") df['symbol'] = symbol df.rename(columns={'日期': 'date', '开盘': 'open', '收盘': 'close', '最高': 'high', '最低': 'low', '成交量': 'volume', '换手率': 'turnover'}, inplace=True) df['date'] = pd.to_datetime(df['date']) df.set_index('date', inplace=True) df = df[['symbol', 'open', 'high', 'low', 'close', 'volume', 'turnover']] print(df) s[symbol] = df
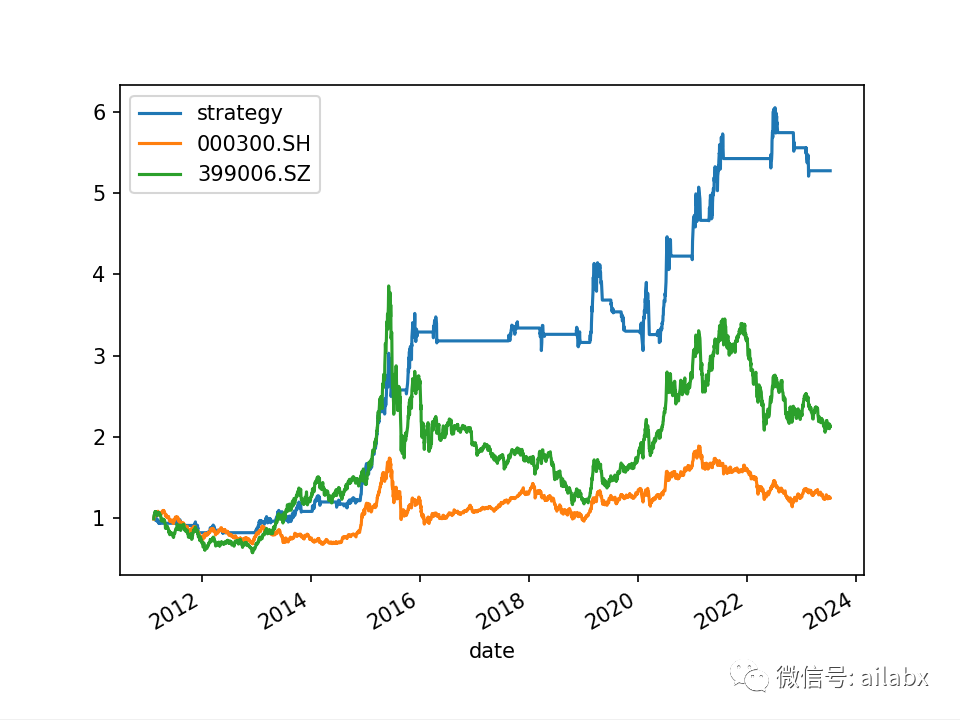
拿 指数的多因子试试:
from engine.datafeed.dataloader import Hdf5Dataloader from engine.env import Env from engine.algo import * from engine.config import DATA_H5, DATA_DIR df_codes = pd.read_csv(DATA_DIR.joinpath('hs300.csv').resolve()) codes = df_codes['con_code'] loader = Hdf5Dataloader(codes, start_date="20100101") fields = ['roc(close,20)', 'std(volume,20)', 'bias(close,20)', 'roc(close,5)', 'std(volume,5)', 'bias(close,5)', 'rank(roc_20)+rank(bias_20)+rank(roc_5)+rank(bias_5)-rank(std_20)-rank(std_5)'] names = ['roc_20', 'std_20', 'bias_20', 'roc_5', 'std_5', 'bias_5', 'rank'] df = loader.load(fields=fields, names=names) bench_loader = Hdf5Dataloader(['000300.SH']) e = Env(df=df, benchmarks=bench_loader.load(fields=['slope_pair(high,low,18)', 'zscore(rsrs_18,600)<-0.7'], names=['rsrs_18', 'zscore'])) e.set_algos([ RunDays(days=10), #RunWeekly(), # SelectAll(), #SelectBySignal(buy_rules=[], sell_rules=['ind(roc_20)<-0.08']), SelectTopK(drop_top_n=1, K=10, order_by='rank', b_ascending=False), PickTime(benchmark='000300.SH', signal='zscore'), WeightEqually() ]) e.backtest_loop() e.show_results() #e.save_results()
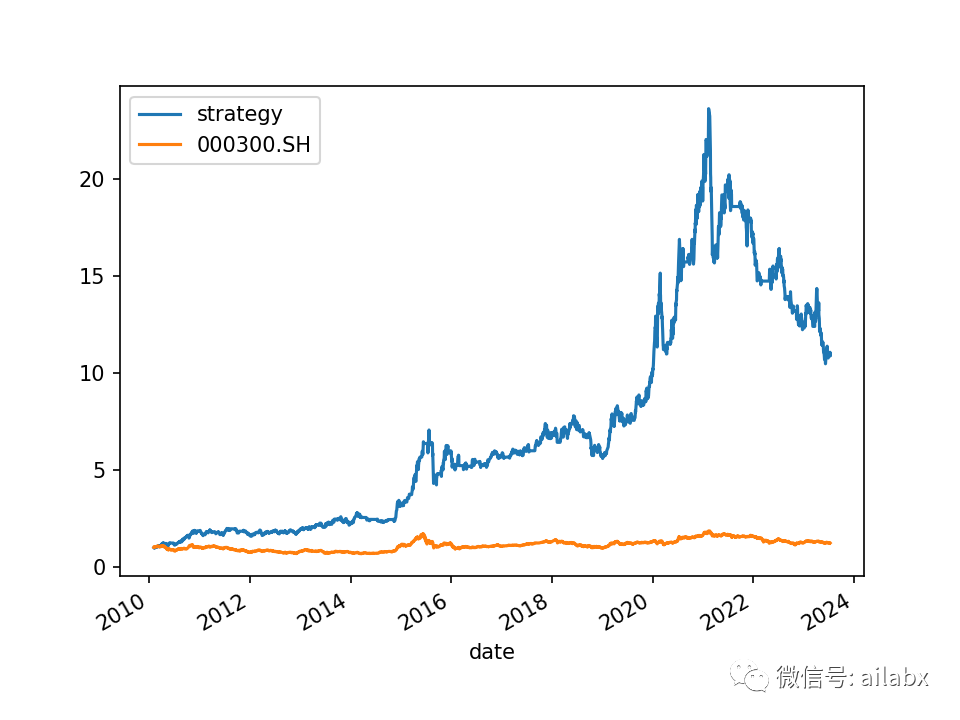

优化了一下performance计算:
之前我们使用empyrical库来计算,我们可以自己计算,后续我们需要补充多个指标,大家最好熟悉指标的计算公式,当然二者计算是结果是一样的。

import pandas as pd from datetime import datetime class PerformanceUtils(object): def rate2equity(self, df_rates): df = df_rates.copy(deep=True) df.dropna(inplace=True) for col in df.columns: df[col] = (df[col] + 1).cumprod() return df def equity2rate(self, df_equity): df = df_equity.copy(deep=True) df = df.pct_change() return df def calc_equity(self, df_equity): df_rates = self.equity2rate(df_equity) return self.calc_rates(df_rates) def calc_rates(self, df_rates): df_equity = self.rate2equity(df_rates) df_rates.dropna(inplace=True) df_equity.dropna(inplace=True) # 累计收益率,年化收益 count = len(df_rates) accu_return = round(df_equity.iloc[-1] - 1, 3) annu_ret = round((accu_return + 1) ** (252 / count) - 1, 3) # 标准差 std = round(df_rates.std() * (252 ** 0.5), 3) # 夏普比 sharpe = round(annu_ret / std, 3) # 最大回撤 mdd = round((df_equity / df_equity.expanding(min_periods=1).max()).min() - 1, 3) ret_2_mdd = round(annu_ret / abs(mdd), 3) ratios = [accu_return, annu_ret, std, sharpe, mdd, ret_2_mdd] # df_ratio存放这里计算结果 df_ratios = pd.concat(ratios, axis=1) # df_ratios.index = list(df_rates.columns) df_ratios.columns = ['累计收益', '年化收益', '波动率', '夏普比', '最大回撤', '卡玛比率'] # 相关系数矩阵 df_corr = round(df_equity.corr(), 2) start_dt = df_rates.index[0] end_dt = df_rates.index[-1] if isinstance(start_dt, str): start_year = int(start_dt[:4]) end_year = int(end_dt[:4]) df_equity['trade_date'] = df_equity.index df_equity.index = df_equity['trade_date'].apply(lambda x: datetime.strptime(x, '%Y%m%d')) del df_equity['trade_date'] else: start_year = start_dt.year end_year = end_dt.year ''' years = [] for year in range(start_year, end_year + 1): sub_df = df_equity[str(year)] if len(sub_df) <= 3: continue year_se = round(sub_df.iloc[-1] / sub_df.iloc[0] - 1, 3) year_se.name = str(year) years.append(year_se) if len(years): df_years = pd.concat(years, axis=1) else: df_years = None ''' return df_ratios, df_corr# df_years
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104061
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!