
今天说说duckdb。之前有简单提过AI量化的基础工程设施:dagster&duckdb
duckdb可以轻松访问多个csv和parquet文件,作为本地的分析引擎很好用。
Mongo持久化,简单易用,适合交易数据增量更新。但分析性能不够。
Duckdb,一个嵌入式的olap引擎。
Mongo数据历史按symbol入csv(parquet),然后当月更新增量包覆盖即可。
@asset(description='增量(当月的增量数据)从多个库中整合宽表入csv', group_name='stocks')
def load_data_to_csv(stock_list_from_mongo):
for i, s in enumerate(stock_list_from_mongo):
get_dagster_logger().debug('主板股票一共:{}支,当前{},代码:{}'.format(len(stock_list_from_mongo), i, s))
date_str = datetime.now().strftime('%Y%m%d')
date = date_str[:6] + '01'
DIR = DATA_DIR_CSVS.joinpath(date_str[:6])
DIR.mkdir(exist_ok=True, parents=True)
df_all = loader_mongo.load_stock_datas(s, date)
if df_all is None:
continue
df_all.to_csv(DIR.joinpath('{}.csv'.format(s.replace('.', '_'))))
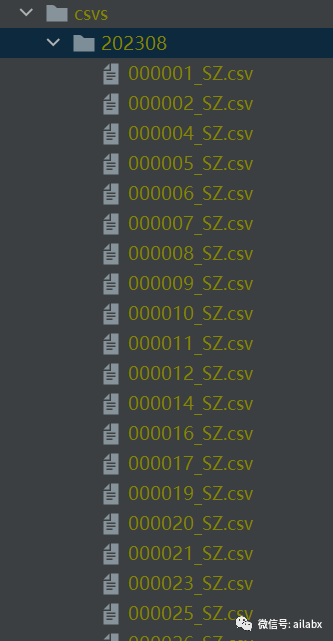

duckdb特别神奇的地方,可以对这多个文件夹下面的csv进行查询,而且性能特别好——如果使用pandas,我们需要遍历这些文件夹,然后把csv读成dataframe,然后concat在一起。——pandas读csv是需要把全量,所有列都一并读入。
duckdb可以使用sql直接查询这个文件夹:使用csvs/*/*.csv,只查询close,date,symbol数据库,某一天的数据:( 这里是不是有点像qlib的数据格式,qlib的文件存储最不方便的地方是增量更新,我这里按csv可以直接覆盖当月,确保数据不会重复,duckdb性能足够好)
当然也可以使用parquet格式,更适合大数据。在小文件下,parquet的压缩不明显,如果月度数据的话,parquet文件比csv还大。
import duckdb import pandas from quant_project.config import DATA_DIR_CSVS df = duckdb.query( """ select symbol,date,close from '{}/*.csv' where date = '20230809' """.format(DATA_DIR_CSVS.resolve()) ) print(df.df())
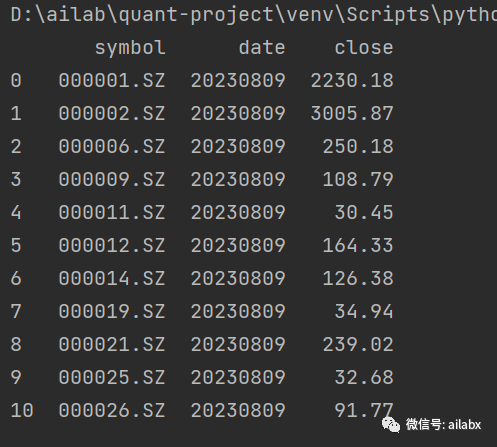
我们的任务编排如下:
每天收盘后更新日线,日线指标,后面还有基本面,财务数据,其他数据等,然后把增量数据更新到csv里,形成当月的增量包,我们客户端下载这个增量包到对应位置即可。
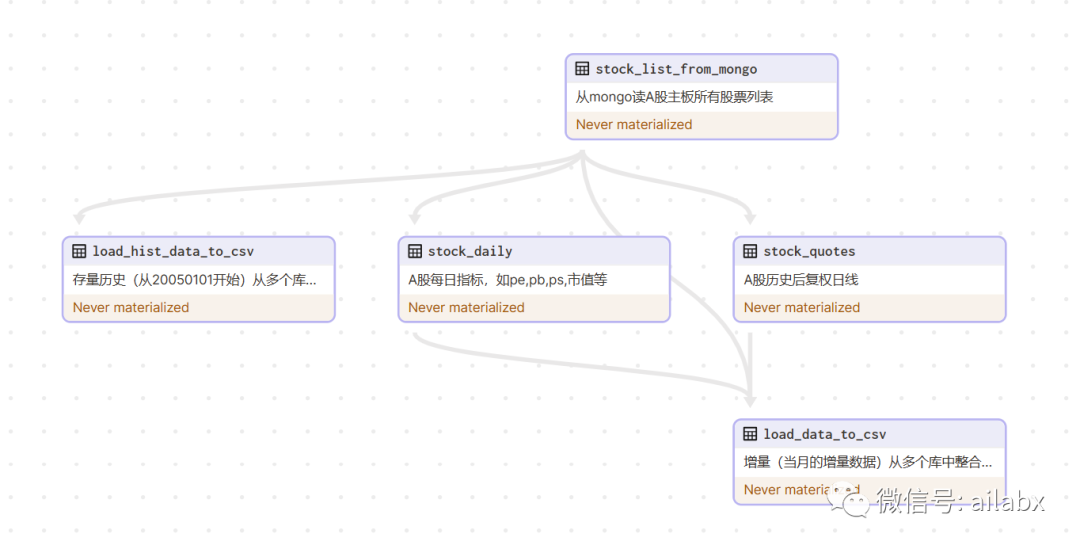
在服务器上的运行界面:
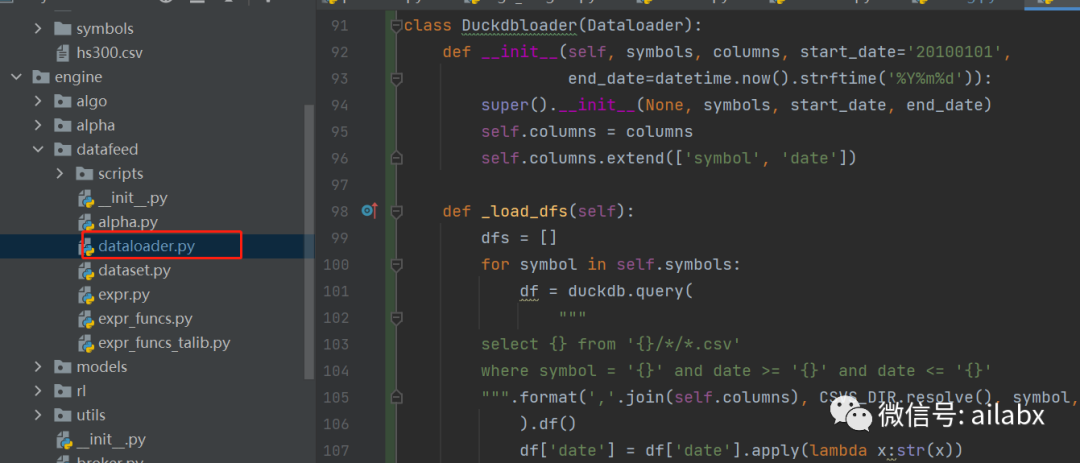
我实现了Duckdbloader:比之前的CSVloader和Hdf5loader都要简洁和高效得多。
class Duckdbloader(Dataloader): def __init__(self, symbols, columns, start_date='20100101', end_date=datetime.now().strftime('%Y%m%d')): super().__init__(None, symbols, start_date, end_date) self.columns = columns self.columns.extend(['symbol', 'date']) def _load_dfs(self): dfs = [] for symbol in self.symbols: df = duckdb.query( """ select {} from '{}/*/*.csv' where symbol = '{}' and date >= '{}' and date <= '{}' """.format(','.join(self.columns), CSVS_DIR.resolve(), symbol, self.start_date, self.end_date) ).df() df['date'] = df['date'].apply(lambda x:str(x)) dfs.append(df) return dfs
前段时间,“有点被流量裹挟”的感觉。
每个用户有不同的诉求,不同的文章,代码发出来之后,大家的反馈不一。确实,这个领域如果要抓眼球,很容易,但不长久。——我们的目标是星辰大海。
有一些小白用户加入进来,问pycharm, python的环境如何安装,依赖包如何解决。也有一些人上来就问策略怎么自动化实盘。——客观讲,这些都不是我期望的目标用户。
给出系统的源代码,是为了引发讨论,学习与交流,它当下肯定不是一个成熟的”产品“。商用金融产品怎么可以交付代码呢。
值得庆幸的是,星球里有一些老用户了解我的逻辑。
回归初心,做长期有价值的事情!
——利用AI模型,把当下A股5000多支股票里,最合适的,得分最高的挑选出来。
我们先构建沪深300成份股列表:还是使用tushare的数据:
# 指定日期的指数成份股 def index_components(index_symbol, date): # 拉取数据 df = pro.index_weight(**{ "index_code": index_symbol, "trade_date": date, "start_date": "", "end_date": "", "ts_code": "", "limit": "", "offset": "" }, fields=[ "index_code", "con_code", "trade_date", "weight" ]) return df
从数据工程的角度,计算少量几支指数会比较容易,当数据量上来的时候,工程的复杂度会指数级上升,甚至完全不是一个技术栈。
今天与一个朋友吃饭,说了一个比喻:盖两层的房子,可以木质材料就可以,如果盖十层,就需要钢筋混凝土,如果需要几十层到上百层,那么需要的技术更不一样的。
当前的大模型也是如此,看似就是从十亿、百亿到千亿。百亿可能很多公司都能解决,但要跨越千亿,那就需要很多工程上的积累。
量化数据也是,百级的数据,几十个因子,可以很容易处理,但几千支股票,上百个甚至更多的因子,那就需要在工程上好好设计一下。
有一点思考,我们的目标是星辰大海,所以星球寻找是志同道合的人群,少而精,因此我进一步提高了门槛。
回到我们的工程设计,mongo等数据库是支持增量更新,我们会到查询最新的数据日期,然后增量去获取数据,mongo数据库有一个好处,就是_id如果重复会自动跳过,这个特别好,我们可以批量覆盖,不必担心说数据重复。
但无论是数据分析,还是多因子回测,都需要对因子进行预计算,整合大宽表等。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103999
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!