
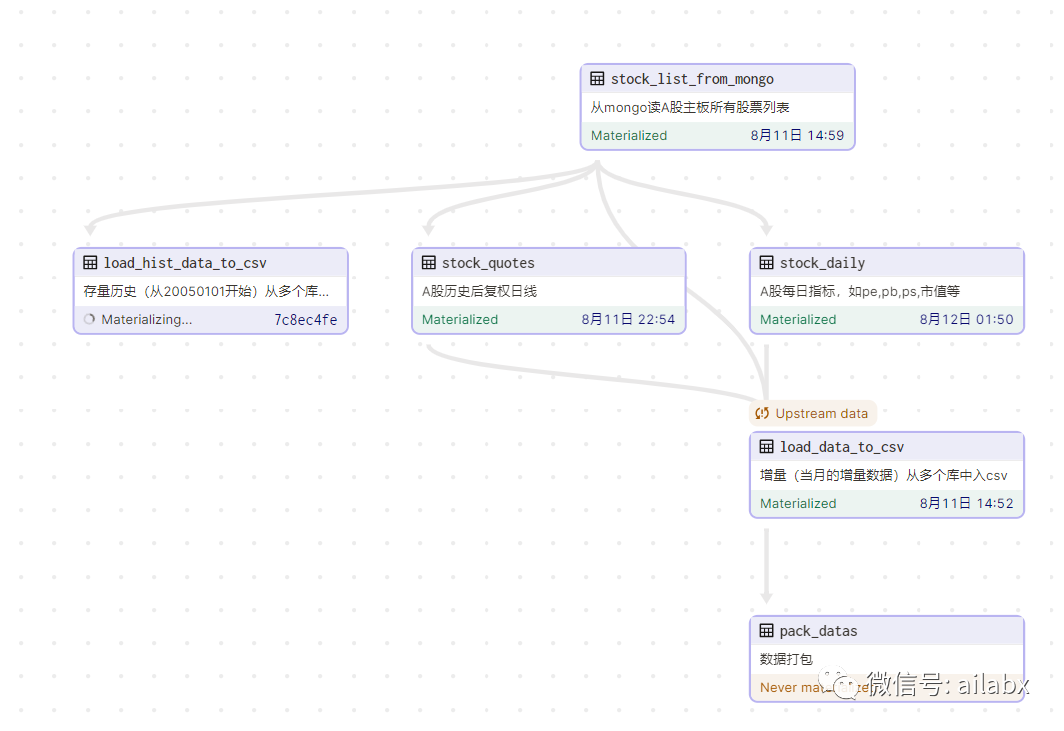

从每日更新增量数据,到数据缓存到csv,到csv合并成csv大宽表,然后自动化打包成zip文件供下载。
说说这里的逻辑以及实现的难点:
我们的持久化库是mongo,选择的理由就是简单易用。与之对比的如mysql,或者postgres这样的关系型数据库,建schema,数据排重之类都很麻烦。mongo这样bson格式相对宽松。我们并不需要事务,或者跨表查询,因此不需要关系型数据库。
那为什么又要导出到本地csv呢?
oltp和olap的区别,oltp关注事务逻辑,每次操作的数据量很小,就是某条数据的增、删,改查为主。但olap不一样,分析需求,很大可能就是分析历史至信,那就需要把全市场全量数据都加载上来。这时候,如果每次从数据库中访问,那性能是个很大的问题。
因此我把数据分成两段,一段是历史数据,一段是最近的增量数据,只有增量数据需要每天更新,然后使用duckdb可以直接查询分析整个文件夹。
下面是打包的代码:
import zipfile, os def zip_dir(startdir, file_news): startdir = startdir # 要压缩的文件夹路径 z = zipfile.ZipFile(file_news, 'w', zipfile.ZIP_DEFLATED) # 参数一:文件夹名 for dirpath, dirnames, filenames in os.walk(startdir): print(dirnames) fpath = dirpath.replace(str(startdir), '') # 这一句很重要,不replace的话,就从根目录开始复制 fpath = fpath and fpath + os.sep or '' # 实现当前文件夹以及包含的所有文件的压缩 for filename in filenames: z.write(os.path.join(dirpath, filename), fpath + filename) z.close() if __name__ == '__main__': from quant_project.config import DATA_DIR_CSVS zip_dir(DATA_DIR_CSVS.resolve(), 'test.zip')
有了大数据大宽表之后,后面仍然需要聚焦。之前我们希望兼容传统规则量化,这个不必使用gui即可。gui仅呈现AI量化相关,选择选股范围,比如沪深300,中证500,或者加上行业维度的筛选条件,成立时间等。
然后就是特征工程与交易模型,二者比较之下,特征工程 更加重要。我们可以借用qlib的alpha158或者alpha360,也和quant101这样的因子集。但最最关键的点在于——如何持续有效地“挖掘”出因子集。如何衡量,这是整件事情之关键。
当然我们可以把基建做好,这们做实验的效率会高很多。
1、数据集加载:补充数据源,另类数据等。
2、因子特征计算——因子计算结果缓存。————如何持续挖掘出高质量的因子
3、模型训练:划分训练集与测试集。——因子合成规则或模型
4、模型回测与评价。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103996
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!