
今日计划:
1、lightGBM排序学习的StockRanker
2、滚动式训练模型及回测(top55个因子)。
3、分析因子特征之重要性。
昨天夜里想起来,一些因子收益异常高,但策略又没有明显的问题。有两点不符合预期,一是涨停板,尤其是牛市里的连续涨停板,这些因子,并不需要与收益多相关,而是像动量、价量背离能连续取到涨停板,但事实上,这是交易不了了。另外就是没有添加交易佣金。
这里添加交易佣金,卖出印花税千1,买卖按万五算,佣金又边按万三算,一共是0.0008的commission。
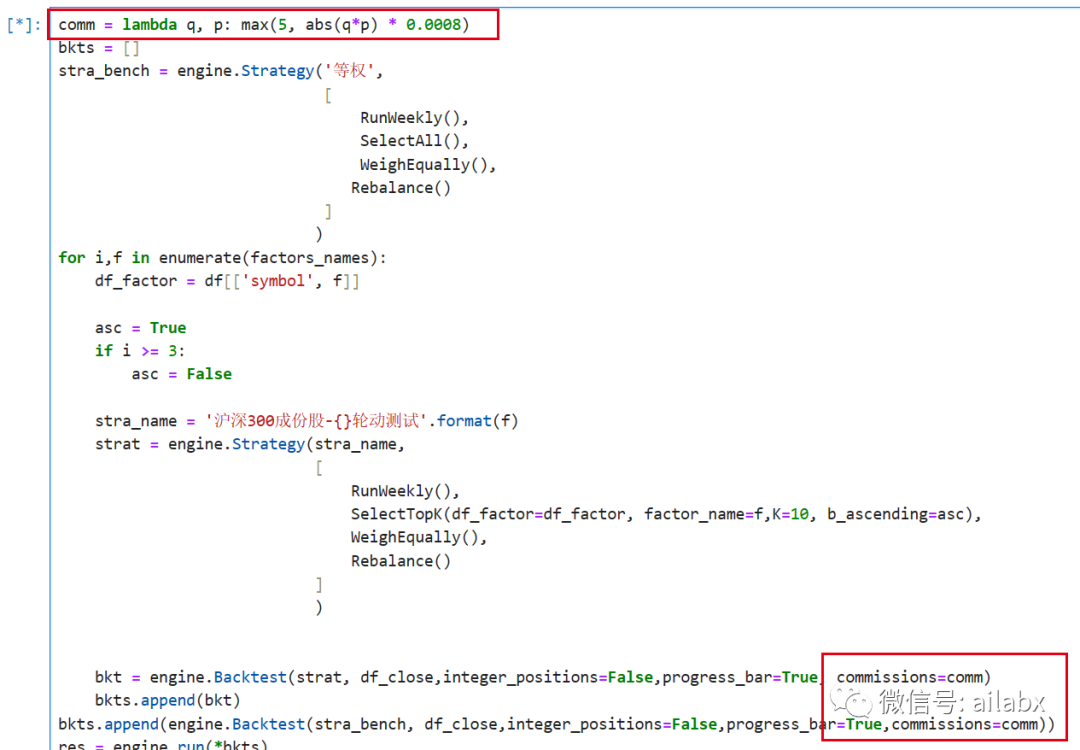

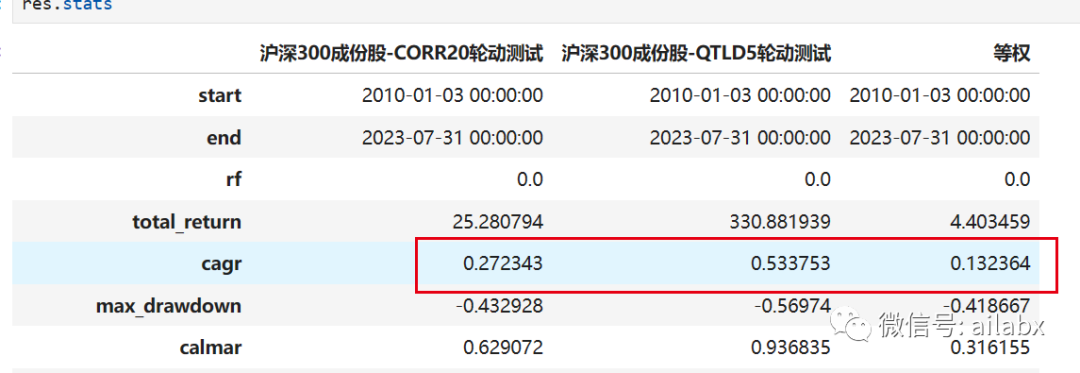
CORR20的年化由43%降到了27%。
LGBRanker排序学习:
import pandas as pd import lightgbm as lgb from lightgbm import log_evaluation, early_stopping class StockRanker: def __init__(self, feature_cols=None): # super(StockRanker, self).__init__(name, load_model) self.feature_cols = feature_cols self.label_col = 'label' def _prepare_groups(self, df): df['day'] = df.index group = df.groupby('date')['date'].count() return group.values def train(self, df: pd.DataFrame, split_date: str = None): if split_date: df_train = df[df.index < split_date] df_val = df[df.index >= split_date] else: df_train = df df_val = df query_train = self._prepare_groups(df_train.copy(deep=True)) query_val = self._prepare_groups(df_val.copy(deep=True)) ranker = lgb.LGBMRanker() callbacks = [log_evaluation(period=100), early_stopping(stopping_rounds=50)] ranker.fit(df_train[self.feature_cols], df_train[self.label_col], group=query_train, eval_set=[(df_val[self.feature_cols], df_val[self.label_col])], eval_group=[query_val], eval_at=[1, 2, 5], callbacks=callbacks) self.ranker = ranker score, names = zip(*sorted(zip(ranker.feature_importances_, ranker.feature_name_), reverse=True)) print(score) print(names) if __name__ == '__main__': from datafeed.dataloader import Duckdbloader from config import DATA_DIR from factor import alpha import pandas as pd import duckdb df = duckdb.query(''' select * from '{}' '''.format(DATA_DIR.joinpath('data_ignore/dataset.csv').resolve()) ).df() df.set_index(['date', 'symbol'], inplace=True) from datafeed.expr import calc_expr df['label'] = calc_expr(df, 'qcut(return_5,5)') df.reset_index(inplace=True) a = alpha.Alpha158() fields, names = a.get_factors() print(df) StockRanker(feature_cols=names).train(df)
树模型有个好处,就是可以给出特征重要性:

与我们收益分析比较类似。
关于大模型
大模型这一波,有点找到了通往AGI(通用人工智能)的可能性。
这才是令人着迷之处。
当然它的算力投入,对数据的要求,也让普通人与普通创业公司望而生畏。当然如同当年计算机刚发明的时候,watson说全世界仅需要5台计算机一样。我们可以乐观一点。
人的大脑其实能耗并不高,但能力其实非常强。
大模型做小,一部分变成基础能力。我们更关心解决问题的能力。
以及在一些场景上,可以衍生出一些好玩的东西,比如投资研究。可以自动整合、分析数据,读研报,给出结论?
吾日三省吾身
不忘初心,用AI技术做量化只是手段,而如何有效指导投资决策才是关键。
面对一众投资标的,5000+支股票,1000+多支ETF,500+支可转债,还有场外基金,期货,或者加密货币。形式都是时间序列,背后的基本面各有不同。
AI量化投资,重要的是投资逻辑,然后看技术也好,AI也罢,能帮我们做什么信息处理,信息增值,自动化等等。
alphalens因子分析,本质是相关分析,还是线性回归。线性回归是先假设有线性关系,然后去拟合。若本身没有关系,且你硬拟合,那就是“过拟合”了。
你拿历史所有数据算的相关性,然后去回测,结果不会差。但这个结果能不能持续,仍然没有把握。因子分析,也需要分样本内与外。
从原理来讲,ETF或者场外基金,适合做长线,大类资产配置。之前见过有人用动量的方式做,单边市场可以,但熊市可能够呛。因些,在AI量化里,ETF因子太少。
传统机器学习目前看来仅保留 :lightGBM(l2r滚动式(StockRanker)训练即可),至于调参都是下一步的事情了。
深度学习应用于图像学习,可以直接跳过特征工程,这是一个巨大的飞跃,直接使用所以图片的像素级的信息,通过叠加复杂的网络结构“端对端”的解决问题。
本身因子化,就是对时序数据在大量简化,会丢失很多原始信息。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103951
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!